This article was published as a part of the Data Science Blogathon.
Introduction
In the previous post, we have defined Probability Distributions and briefly discussed different Discrete Probability distributions. In this post, we will continue learning about probability distributions through Continuous Probability Distributions.
Definition
If you recall from our previous discussion, continuous random variables can take an infinite number of values over a given interval. For example, in the interval [2, 3] there are infinite values between 2 and 3. Continuous distributions are defined by the Probability Density Functions(PDF) instead of Probability Mass Functions. The probability that a continuous random variable is equal to an exact value is always equal to zero. Continuous probabilities are defined over an interval. For instance, P(X = 3) = 0 but P(2.99 < X < 3.01) can be calculated by integrating the PDF over the interval [2.99, 3.01]
List of Continuous Probability Distributions
We discuss the most commonly used continuous probability distributions below:
1. Continuous Uniform Distribution
Uniform distribution has both continuous and discrete forms. Here, we discuss the continuous one. This distribution plots the random variables whose values have equal probabilities of occurring. The most common example is flipping a fair die. Here, all 6 outcomes are equally likely to happen. Hence, the probability is constant.
Consider the example where a = 10 and b = 20, the distribution looks like this:
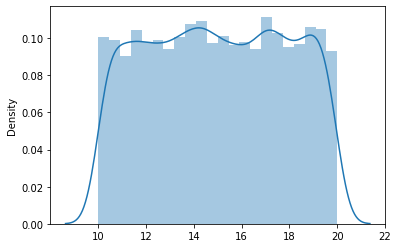
The PDF is given by,
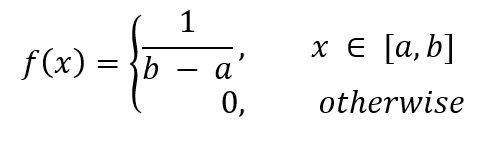
where a is the minimum value and b is the maximum value.
2. Normal Distribution
This is the most commonly discussed distribution and most often found in the real world. Many continuous distributions often reach normal distribution given a large enough sample. This has two parameters namely mean and standard deviation.
This distribution has many interesting properties. The mean has the highest probability and all other values are distributed equally on either side of the mean in a symmetric fashion. The standard normal distribution is a special case where the mean is 0 and the standard deviation of 1.
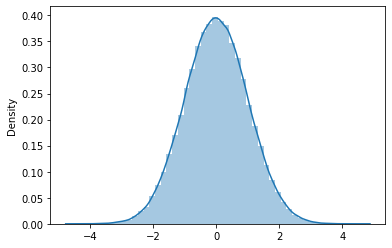
It also follows the empirical formula that 68% of the values are 1 standard deviation away, 95% percent of them are 2 standard deviations away, and 99.7% are 3 standard deviations away from the mean. This property is greatly useful when designing hypothesis tests(https://www.statisticshowto.com/probability-and-statistics/hypothesis-testing/).
The PDF is given by,
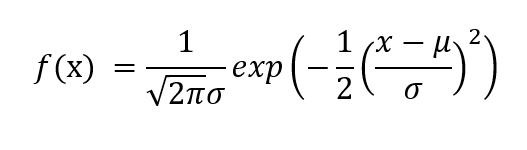
where μ is the mean of the random variable X and σ is the standard deviation.
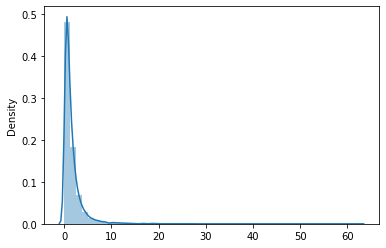
3. Log-normal Distribution
This distribution is used to plot the random variables whose logarithm values follow a normal distribution. Consider the random variables X and Y. Y = ln(X) is the variable that is represented in this distribution, where ln denotes the natural logarithm of values of X.
The PDF is given by,
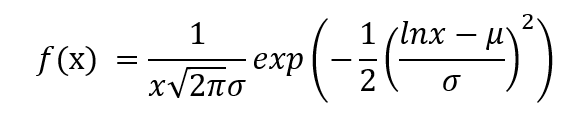
where μ is the mean of Y and σ is the standard deviation of Y.
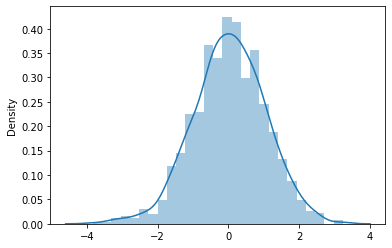
4. Student’s T Distribution
The student’s t distribution is similar to the normal distribution. The difference is that the tails of the distribution are thicker. This is used when the sample size is small and the population variance is not known. This distribution is defined by the degrees of freedom(p) which is calculated as the sample size minus 1(n – 1).
As the sample size increases, degrees of freedom increases the t-distribution approaches the normal distribution and the tails become narrower and the curve gets closer to the mean. This distribution is used to test estimates of the population mean when the sample size is less than 30 and population variance is unknown. The sample variance/standard deviation is used to calculate the t-value.
The PDF is given by,
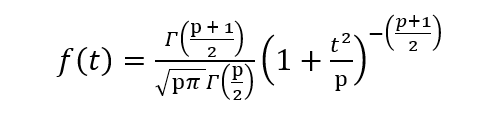
where p is the degrees of freedom and Γ is the gamma function. Check this link for a brief description of the gamma function.
The t-statistic used in hypothesis testing is calculated as follows,
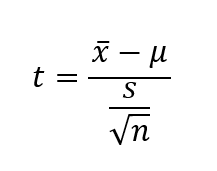
where x̄ is the sample mean, μ the population mean and s is the sample variance.
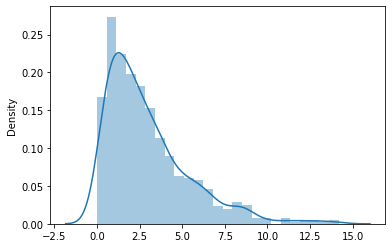
5. Chi-square Distribution
This distribution is equal to the sum of squares of p normal random variables. p is the number of degrees of freedom. Like the t-distribution, as the degrees of freedom increase, the distribution gradually approaches the normal distribution. Below is a chi-square distribution with three degrees of freedom.
The PDF is given by,
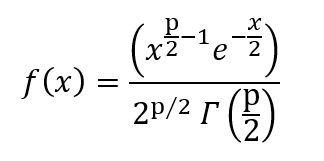
where p is the degrees of freedom and Γ is the gamma function.
The chi-square value is calculated as follows:
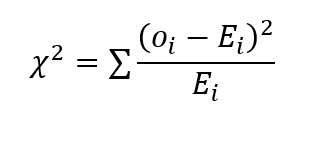
where o is the observed value and E represents the expected value. This is used in hypothesis testing to draw inferences about the population variance of normal distributions.
6. Exponential Distribution
Recall the discrete probability distribution we have discussed in the Discrete Probability post. In the Poisson distribution, we took the example of calls received by the customer care center. In that example, we considered the average number of calls per hour. Now, in this distribution, the time between successive calls is explained.
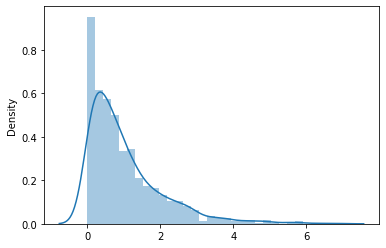
The exponential distribution can be seen as an inverse of the Poisson distribution. The events in consideration are independent of each other.
The PDF is given by,
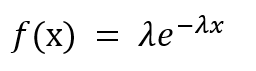
where λ is the rate parameter. λ = 1/(average time between events).
To conclude, we have very briefly discussed different continuous probability distributions in this post. Feel free to add any comments or suggestions below.
About Me
I am Priyanka Madiraju, a former software engineer, working on transitioning into Data Science. I am a master’s student in Data Science. Please feel free to connect with me on https://www.linkedin.com/in/priyanka-madiraju
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Priyanka Madiraju
09 Feb, 2021








Hi, I also read your previous post and very much impressed with the knowledge. I really thank you to share both articles. Regards
God richly bless you Brother for such a brief explanation. but please if you could add real life examples to each distribution type for more better understanding. Thank you Snr