In decision trees, making informed choices is pivotal for accurate and robust predictions. Selecting the optimal split to branch nodes significantly influences a decision tree’s effectiveness. One of the powerful methods employed for this purpose is the gini impurity decision tree. This article delves into the intricacies of utilizing Gini Impurity to discern the best split in decision trees. We will explore the concepts, calculations, and real-world implications, equipping you with a comprehensive understanding of how it enhances the precision and reliability of decision tree models. Whether you’re a novice or a seasoned data practitioner, uncovering the secrets behind this essential algorithm will empower you to harness the full potential of decision trees in your data analysis endeavors.
Gini impurity is a measure used in decision tree algorithms to quantify a dataset’s impurity level or disorder. In binary classification problems, it assesses the likelihood of an incorrect classification when a randomly selected data point is assigned a class label based on the distribution of classes in a particular node. It ranges from 0 to 0.5, where 0 indicates a perfectly pure node (all instances belong to the same class), and 0.5 signifies maximum impurity (an equal distribution of classes). In decision trees, it aids in selecting the optimal split by identifying features that result in more homogeneous subsets of data, ultimately contributing to the creation of accurate and reliable predictive models.
There are multiple algorithms that are used by the decision tree to decide the best split for the problem. Let’s first look at the most common and popular out of all of them, which is Gini Impurity. It measures the impurity of the nodes and is calculated as:

Let’s first understand what Gini is and then I’ll show you how you can calculate the Gini impurity for split and decide the right split. Let’s say we have a node like this-
So what Gini says is that if we pick two points from a population at random, the pink ones highlighted here, then they must be from the same class. Let’s say we have a completely pure node-

Can you guess what would be the probability that a randomly picked point will belong to the same class? Well, obviously it will be 1 since all the points here belong to the same class. So no matter which two points you picked, they will always belong to that one class and hence the probability will always be 1 if the node is pure. And that is what we want to achieve using Gini.
Gini ranges from zero to one, as it is a probability and the higher this value, the more will be the purity of the nodes. And of course, a lesser value means lesser pure nodes.
Let’s look at its properties before we actually calculate the gini impurity decision tree to decide the best split.
We decide the best split based on the gini impurity in decision tree and as we discussed before, Gini impurity is:
Here Gini denotes the purity and hence Gini impurity tells us about the impurity of nodes. Lower the Gini impurity we can safely infer the purity will be more and hence a higher chance of the homogeneity of the nodes.
Gini works only in those scenarios where we have categorical targets. It does not work with continuous targets.
A very important point to note to keep in mind. For example, if you want to predict the house price or the number of bikes that have been rented, Gini is not the right algorithm. It only performs binary splits either yes or no, success or failure, and so on. So it will only split a node into two sub-nodes. These are the properties of Gini impurity.
Also Read: How to Split a Decision Tree – The Pursuit to Achieve Pure Nodes
Let’s now look at the steps to calculate the Gini split.
First, we calculate the Gini impurity for sub-nodes, as you’ve already discussed gini impurity in decision tree is, and I’m sure you know this by now:
Here is the sum of squares of success probabilities of each class and is given as:
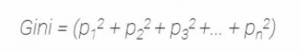
Considering that there are n classes.
Once we’ve calculated the Gini impurity for sub-nodes, we calculate the gini impurity decision tree of the split using the weighted impurity of both sub-nodes of that split. Here the weight is decided by the number of observations of samples in both the nodes. Let’s look at these calculations using an example, which will help you understand this even better.
For the split on the performance in the class, remember this is how the split was?
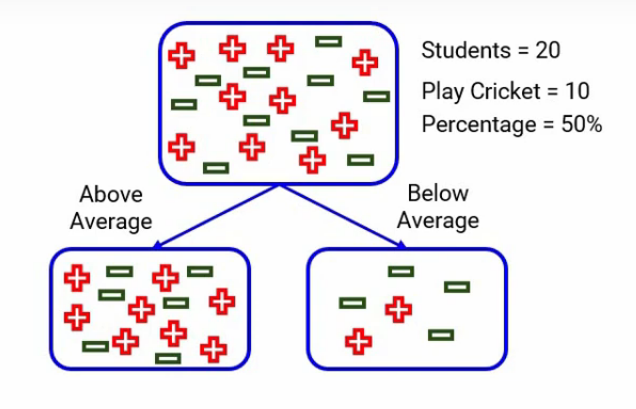
We have two categories, one is “above average” and the other one was “below average”.
When we focus on the above average, we have 14 students out of which 8 play cricket and 6 do not. The probability of playing cricket would be 8 divided by 14, which is around 0.57, and similarly, for not playing cricket, the probability will be 6 divided by 14, which will be around 0.43. Here for simplicity, I’ve rounded up the calculations rather than taking the exact number.
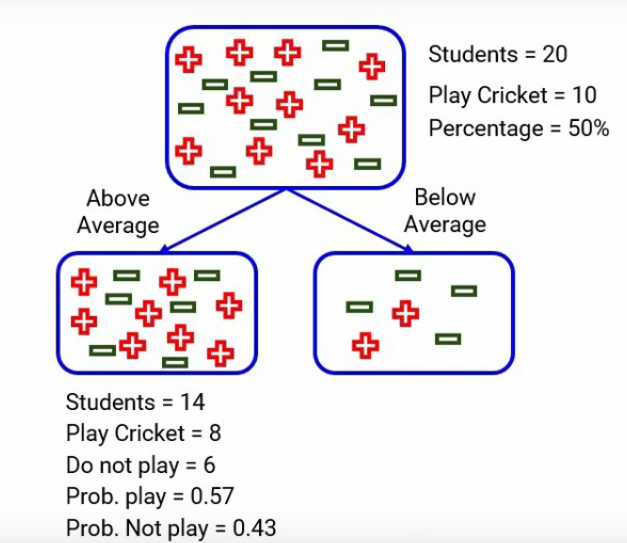
Similarly, when we look at below average, we calculated all the numbers and here they are- the probability of playing is 0.33 and of not playing is 0.67-
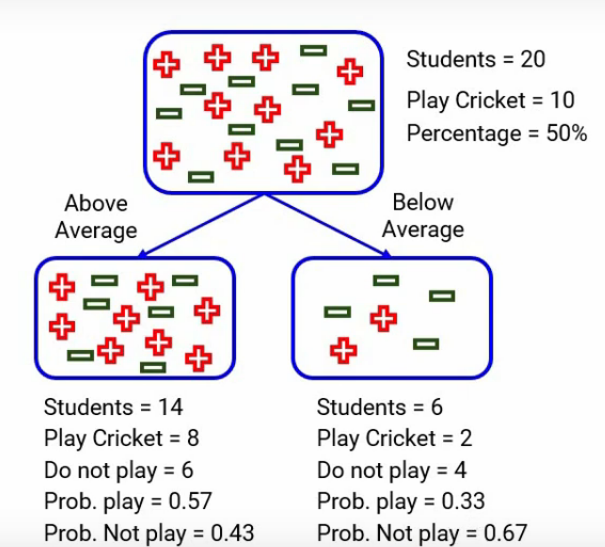
Let’s now calculate the GI of the sub-nodes for above average and here’s the calculation-

It will be, one minus the square of the probability of success for each category, which is 0.57 for playing cricket and 0.43 for not playing cricket. So after this calculation Gini comes out to be around 0.49. The Below average node will do the same calculation as Gini. For below average:

It comes up to be around 0.44. Just take a pause and analyze these numbers.
Now to calculate the gini impurity in decision tree of the split, we will take the weighted Gini impurities of both nodes, above average and below average. In this case, the weight of a node is the number of samples in that node divided by the total number of samples in the parent node. So for the above-average node here, the weight will be 14/20, as there are 14 students who performed above the average of the total 20 students that we had.
And the weight for below average is 6/20. So, the weighted Gini impurity will be the weight of that node multiplied by the Gini impurity of that node. The weighted gini impurity decision tree for performance in class split comes out to be:

Similarly, here we have captured the gini index decision tree for the split on class, which comes out to be around 0.32–

Now, if we compare the two Gini impurities for each split-

We see that the Gini impurity for the split on Class is less. And hence class will be the first split of this decision tree.
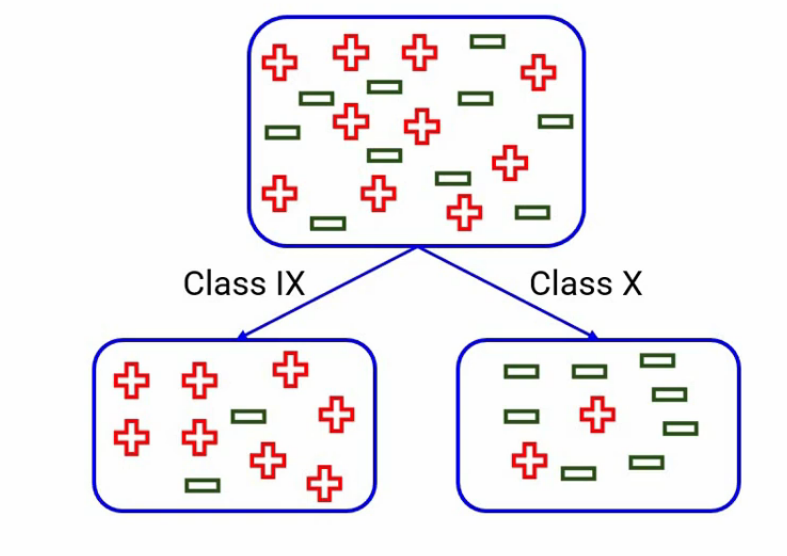
Similarly, for each split, we will calculate the Gini impurities and the split producing minimum Gini impurity will be selected as the split. And you know, that the minimum value of gini index decision tree means that the node will be purer and more homogeneous.
In conclusion, understanding the Gini Impurity measure is pivotal for enhancing the accuracy and reliability of decision tree models. By quantifying the impurity level of data nodes, Gini Impurity aids in identifying optimal splits, leading to more homogeneous subsets and ultimately more accurate predictions. With a range from 0 to 0.5, where lower values signify purer nodes, Gini Impurity serves as a crucial tool in decision tree algorithms. Mastery of this concept equips data practitioners, whether beginners or experts, to unlock the full potential of decision trees in their data analysis endeavors.
If you are looking to kick start your Data Science Journey and want every topic under one roof, your search stops here. Check out Analytics Vidhya’s Certified AI & ML BlackBelt Plus Program!
If you have any questions, let me know in the comments section!
A. The Gini Impurity formula is: 1 – (p₁)² – (p₂)², where p₁ and p₂ represent the probabilities of the two classes in a binary classification problem.
A. A Gini Impurity of 0 indicates a perfectly pure node, where all instances belong to the same class.
A. The Gini coefficient measures income inequality, while Gini Impurity assesses impurity in decision tree nodes, helping to determine optimal splits for classifying data.
A. Entropy measures a set’s disorder level, while Gini impurity quantifies the probability of misclassifying instances. Both are used in decision trees to determine node splits, but Gini favors larger partitions.
The highest Gini impurity is 0.5. This indicates that a node has an equal distribution of classes, meaning that it is completely impure.
I am a data lover and I love to extract and understand the hidden patterns in the data. I want to learn and grow in the field of Machine Learning and Generative AI.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








Nice overview
Thanks a lot:)
Great post!!!
Thanks a lot:)
Nice article!
Thanks a lot:)
It's very detailed and clear, thank you...
Thanks a lot:)
Great Article For Beginners. Concepts are explained in a very intuitive manner.
Hi, how does it work for regression, e.g. decision tree regressor? Is it in the exact same way or different?
Hi there! You've raised a really interesting point. When we switch from decision tree classification to regression, things change a bit, especially in how we decide to split the nodes.
In classification trees, we use measures like Gini Impurity or Entropy to figure out the best way to split our data. These methods work well because we're dealing with categories (like 'yes' or 'no', 'spam' or 'not spam'). But in regression, our goal is to predict continuous values (like house prices or temperatures), so we need a different approach.
Here's how it works in a regression tree:
Choosing Where to Split: Unlike in classification, for regression trees, we look at reducing the variance in our data. Variance is just a statistical way of saying how spread out our numbers are. The tree will try different features to split on and see which split reduces this spread the most.
The Math Behind It: To get technical for a moment, the tree calculates the reduction in variance for each potential split. Imagine you split your data into two groups based on some feature. The tree checks how much this split reduces the spread (variance) in each group compared to the original dataset. The best split is the one that reduces this spread the most.
Finalizing the Split: The algorithm goes through all the possible splits and picks the one that gives us the biggest reduction in variance. It keeps doing this, split by split, until it reaches a point where it can't or shouldn't split anymore (like when the groups get too small or we've reached a set depth for the tree).
So, in essence, while the basic idea of splitting data into smaller groups is the same in both classification and regression trees, the way we decide those splits is different. Classification is all about sorting out categories, while regression is about finding splits that best reduce the variability in our continuous data.
Hope that clears things up a bit!