This article was published as a part of the Data Science Blogathon.

Source-Pixabay
The Trade-off is when you choose to accept less for one thing to get more of another. For example, when you buy a phone there can be a trade-off between price and quality.
We often heard about bias-variance trade-offs in machine learning, the obvious questions that come into mind are, Why do we need to do this trade-off in the first place? What kind of sacrifice we are making and what are we gaining by doing that?
Let’s try to understand the background of the bias-variance trade-off first.
The Central issue in all of the Machine learning…
The fundamental question in machine learning is how do we expect a model which has been built by using a finite amount of training data to work well on something the model has never seen at all?
Let’s imagine, you are learning to drive, spend a couple of weeks driving a car that has dual control and a driving instructor to guide you. Driving on safe roads, following every traffic rule. After that, you passed the test and got your driving license. On the very next day in a very happy mood, you took out your car for a drive and you saw this,

A shocker for you 😱. These things are not new especially when you are driving in India. A driver has to deal with many challenges which he did not face during the motor training period. The real test of your learning happened on a road where you drive by yourself with a steering wheel in your hand. Things you learned during training, you will not encounter when you are driving in the traffic, yet you are expected to drive your way around without any accidents.
This scenario is pretty much similar to what we encounter in machine learning, we have a limited amount of data to train on where we try to abstract general enough from the data, which can be used on unseen data which we did not encounter before.
Now the question is, how to abstract general enough from data?
When in dilemma, choose the simpler…
Occam’s Razor
Occam’s Razor is a principle from philosophy. Suppose there exist two explanations for an occurrence. In this case, the one that requires the smallest number of assumptions is usually correct.

Shaving off unnecessary complexities source: Pixabay
Occam’s Razor In a machine learning context, says that, making a model as simple as possible but not simpler.
For example in a decision tree, we ask series of true and false questions and the depth of the tree will indicate how many questions we asked. Suppose we built two trees, one with a depth of 4 and another one with the depth of 6 and performance of both the tree is similar, then according to Occam’s razor principle we should choose a tree with a depth of 4, as it asked less number of questions, It is a simpler tree compare to a tree with a depth of 6.
So to abstract general enough from data we need to build a simpler model.
- If we build a model more complex than it needs to be, then we have a problem at our hands.
- If we build a model way too simple, then it is probably way too weak.
Now the question is what term the simple and complex means in the context of machine learning? And how to build a simpler model?
Simplicity X Complexity
Let’s imagine two students are preparing for a competitive exam like JEE where the core subjects are physics, maths, chemistry. Both the student have a different approach towards the exam. Both have different mental models.

Illustration of both the student’s source: milady
Student 1 -> He is going through all the syllabus and mugging up, solving a whole lot of different questions, learning the pattern of the previous year’s question papers. Preparing to ensure to answer the certain kind of questions within 3 hours. So basically he is only focusing on cracking the exam.
Student 2 -> He is very serious about the subjects. He has a clear understanding of the fundamental of subjects. According to him, there is no need to solve 100’s questions as long as your basics are clear. He can solve questions using fundamental understanding given enough time.
Let’s consider two different scenarios on the exam day.
Scenario 1-> The question paper was very similar to the question papers of the last few years. Here Student 1 solved a very high number of questions correctly. His whole mugged-up thing worked here, and he will crack the exam for sure. Student 2 on the other side, however, could have solved the all questions but the time was not enough for him, and will be less likely to crack it.
Scenario 2 -> Here NTA(National Testing Agency) decided to surprised everyone. The question paper altogether was a new one, with different patterns, no repeated questions. After seeing that question paper student 1 just frozen down. He was very confused about what to do here. He was surely going to fail. On the other hand student, 2 could have solved the questions, as his fundamentals were clear but he did not have sufficient time. In this scenario also chances of him cracking the exam were very less.
Now let’s observe, analyze the situations given above and try to figure out why do we seek simplicity?
let’s think about what kind of model these two students represent.
Student 1 –> he represents a complex model. He has mugged up the whole syllabus, watched tutorials, solved examples.
Student 2 –> he represents a simple model as he only relied on fundamental principles of subjects.
- We can observe even though the time was not sufficient, student 2 was able to solve the questions in both scenarios. Whereas student 1 failed miserably in the second scenario, as the questions were unseen. It is an illustration of simpler the model more generalizable it is and likely to perform in different kind of situations.
- We can also observe that the reading material used by student 1 is far more than student 2. If student 1 somehow got access to the material from where the scenario 2 question paper came from he could have cracked the exam. Whereas student 1 has gone through very less reading material. We can agree, that the simpler model requires less training data compared to the complex one.
- student 1 performance depends upon what kind of questions will be asked. Whereas student 2 won’t care about the question paper as his basics were clear. The simpler model is more robust to any situation compare to the complex model.
But simplicity has its own disadvantages,
as we have seen above chances of student 2 clearing the exam are very less in both scenarios, as the given time is not sufficient for him. He had not done exam centric preparation. Like a little bit of mugging up, learning new tricks to solve questions in less time.
So what could be the solution where both the students will able to crack the exam in both the scenarios?
Here trade-off comes into play. Student 1 needs to mug up less and try to gain a fundamental understanding, whereas student 2 needs to mug up some parts, solve questions.
Bias-Variance trade-off
Variance
How sensitive the model is to changes in the input data. Here we talk about the consistency of the model. In our example suppose the exam pattern changes then student 1 (complex model) will have to mug up something completely different than before, but student 2 (simple model) doesn’t care about the change in the exam pattern.
Bias
The inability of the machine learning model to capture the true relationship. The Inherent error that our model makes. Here we talk about the correctness of our model. Like in our example student 1 (complex model) has mug up everything from train data, he will crack the exam if the question paper comes from his preparation where Student 2(simple model) is likely to be failed.
Overfit
A model has become too specific to the training data and learned hidden patterns as well as noise and inconsistency in the dataset. Student 1 is a perfect case of overfitting.
The main objective of the Bias-Variance trade-off is to strike a balance between simplicity and complexity to build a simpler model which follows Occam’s razor principle. The trade-off between consistency and correctness.
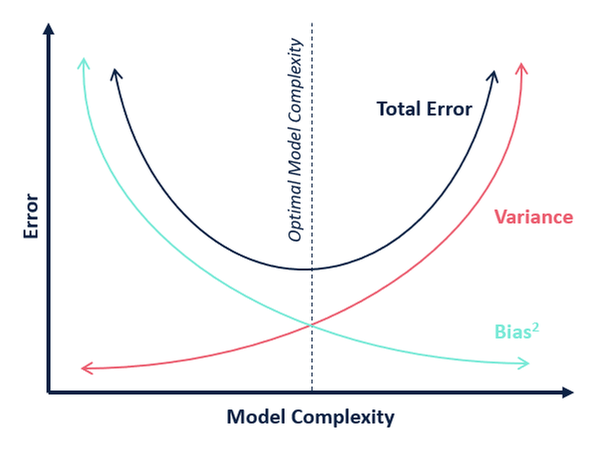
Bias-Variance Trade-Off source:Google images
- The horizontal axis represents the complexity. As you move more towards the right, the complexity will increase.
- The vertical axis tells the error made by the model.
- The complex model has very high variance and a simple model has low variance.
- The complex model has a very low bias and the simple model has a very high bias.
The expected error that the model will make is the bias + Variance. At the end of the trade-off, we want our model to have the lowest total error. Here we finally get our Simpler model. A model simple enough to be generalizable and complex enough not to make too many mistakes, Right balance between the two.
Almost every machine learning algorithm has some inbuilt steps to ensure that model does not become unnecessarily complex. These steps are called Regularization steps. like in the regression model we use Ridge, lasso, elastic net for regularization. Tree truncation and tree pruning in tree-based algorithms and dropouts in Neural nets.
End Notes
In this article, we tried to gain intuition behind the bias-variance trade-off and understood how it solves one of the key problems in machine learning.
References –
- ISLR book – bias and variance
- Wikipedia – Occam’s Razor
- Statquest bias and variance – Youtube
Feedbacks are welcomed, they are valuable to me. If you have any questions, let me know in the comments section! or you can contact me on Linkedin.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.







Very nice explanation of bias variance loved reading article.. I think the bias complex model is too much focus on details and facts in dataset which is like mugging up and memorizing to fit those facts and details in very short time in question paper as the pattens show similarity . Answering approach to question paper is facts and details driven here which is must however it's only focused on outcome. Student one is core Hardworking as he has strained his all senses in one direction only and that is to answer in a very short time. Variance simpler model student 2 is smart and creative, he is less concerned with facts and details as he knows a centre point where all these facts and details finally converge or may be obeying a very simple general rule of theory which may be forgotten or considered irrelevant by student 1 . The simpler model is very good in Understanding Question . If it's a theory paper he will excel. However he didnt take pain to work on steps to apply facts and details therefore he will always be slow. I think the trade off is between Answering the question paper(facts and details)and Making a question paper (most fundamental assumption behind question). Balancing between both will ensure optimum capacity utilization of the model