Quick Guide To Estimation
Introduction
Estimation techniques are used to help organizations make strategic business decisions.
It is difficult to get data for the entire population. In estimation, our goal is to estimate the population parameter value by working with a sample.
Often product companies run surveys through marketing survey services to get data which they then use for decision making to better design their products. A conclusion can be drawn about the entire customer base based on the information obtained from a sample.
An estimator is any quantity calculated from the sample data which is used to give information about an unknown quantity in the population (the estimand). For example, the average customer satisfaction.
An estimate is the particular value of an estimator that is obtained by a particular sample of data and used to indicate the value of a parameter. For example, after the survey, it was found that average customer satisfaction is 7 on a scale of 1 to 10.
The result of the estimation can be shown as a single number, but if the results are described as a range, with minimum and maximum values along with probability, it may be easier for the stakeholders to understand.
Point Estimation is the attempt to provide the single best prediction of some quantity of interest. In our example, the average customer satisfaction or the mean of the sample data of customer rating is a point estimate, i.e., it is just a single number that gives the estimate.
Interval Estimation involves computing an interval, or range of values, within which the parameter is most likely to be located. For example, we say that there is a 95% probability that the average customer satisfaction lies between intervals 6 and 8.
Average customer satisfaction, our estimator, is a random variable that depends on the information extracted from the sample. For the first sample, its estimate or value is 7. For the second sample, it could be 6.
Ideally one can consider all possible samples corresponding to a given sampling strategy and get a probability distribution. A probability distribution is nothing but the mapping between a list of all possible outcomes and their probabilities.
For a discrete random variable X ( customer satisfaction: {1,2,…10} ) that takes on a finite number of possible values, we determine P(X=x) for all of the possible values of X and called it the probability mass function (PMF)
The Average Customer Satisfaction estimate from all possible samples is a continuous random variable and we can build a probability density function for all the different estimates.
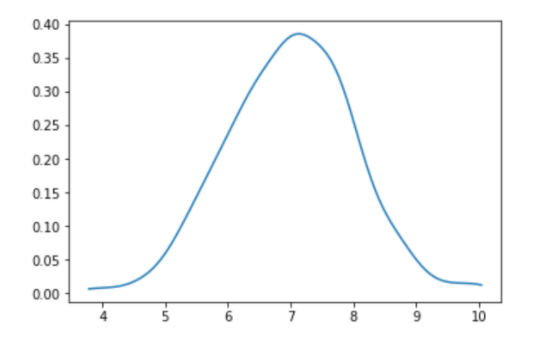
For a detailed understanding of PDFs please refer to this article.
By looking in particular at summary measures of the sampling distribution of an estimator, particularly its mean and variance, we can get a good idea of how well the estimator in question can be expected to perform. For instance, it would be useful if the estimator turns out to have an expected value equal to the parameter we are interested in estimating.
The expected value of an estimator is the average of the possible values of an estimator for all samples, weighted by their probabilities.
BIAS OF AN ESTIMATOR
If we let theta hat be an estimator for theta, the bias in theta hat is the difference between the expected value or the mean value of theta hat and the true value or the population parameter theta.
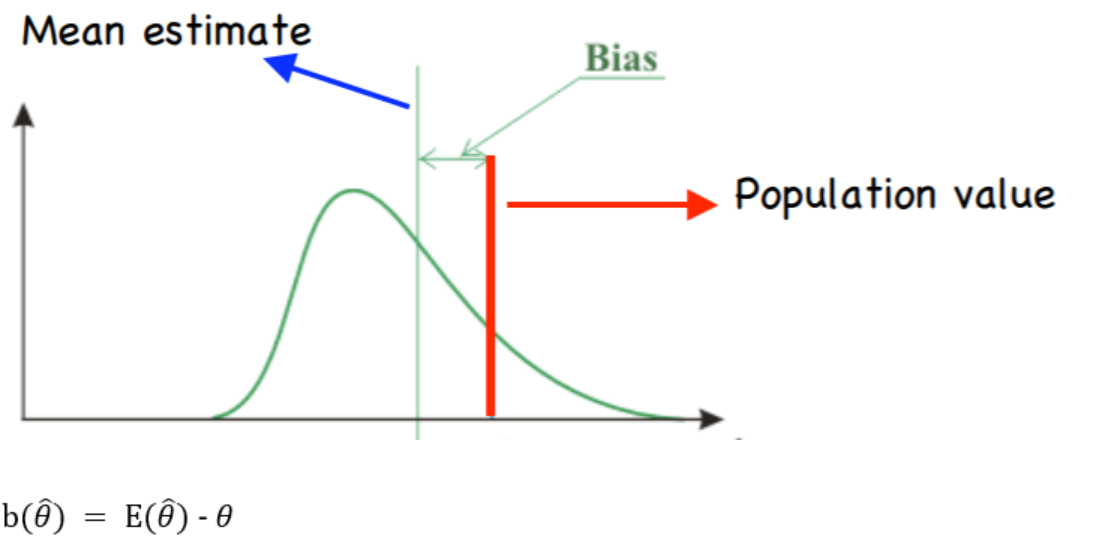
It is the distance between the average of the collection of estimates, and the single parameter being estimated.
Because of expectation in the picture, if the sampling procedure is repeated many times, then on average the estimated value for an unbiased estimator will be equal to the population parameter
Unbiasedness is a necessary condition but it is not sufficient to make the estimator most desirable.
EFFICIENCY OF AN ESTIMATOR
The variance of the estimator is simply the expected value of the squared sampling deviations

It is used to indicate how far, on average, the collection of estimates are from the expected value of the estimates.
An estimator is efficient if it has a probability distribution with a low degree of dispersion around the true value.
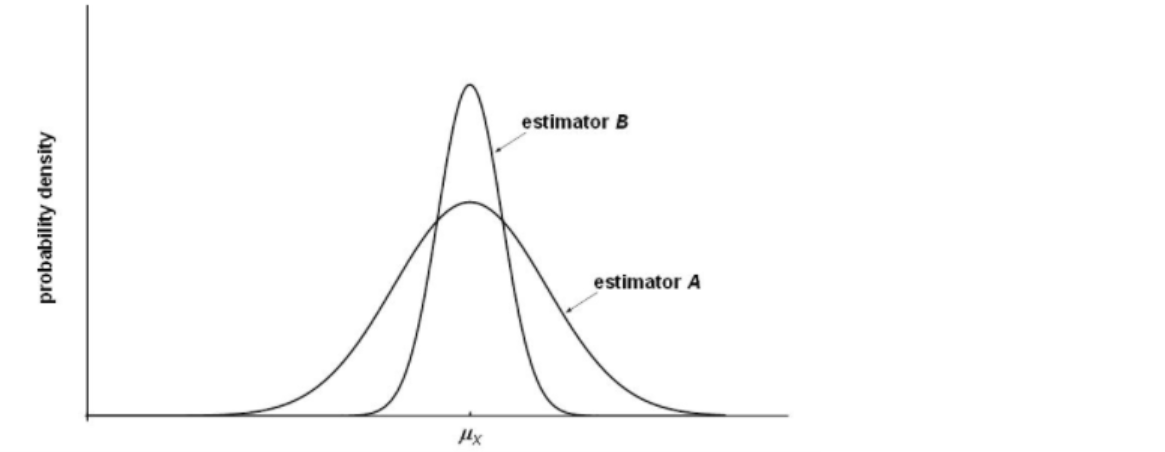
Among different unbiased estimators that can be obtained, we choose the one with minimum variance, here estimator B.
MEAN SQUARED ERROR
Unbiased and/or efficient estimators do not always exist. Moreover, one should not be very keen on unbiasedness as it could be misleading. For example, if an estimator overstates the value as µ + 5 half the times and understates the value as µ – 5 half the times. The estimator is unbiased with large variance even though for a single observation it is always incorrect. It would be better to have a slightly biased estimator with a small variance. But how do we decide that tradeoff?
MSE is a simple approach to tradeoff biasedness with variance and compares the estimators.

It is used to indicate how far, on average, the collection of estimates are from the single parameter being estimated. The bias-variance decomposition of the above shows that the MSE, variance, and bias, are related:

i.e. mean squared error = variance + square of bias. In particular, for an unbiased estimator, the variance equals the MSE.

FUNCTION ESTIMATION
X: independent input variables or predictors like price, no of days taken for delivery, etc
Y: dependent or response variable – customer satisfaction.
Since Y is dependent on factors X, there is a relationship which we can assume as a function of X and some random error e:
Y = f(X)+e
In function estimation, we try to approximate f with a model or estimate f̂. The goal is to come up with an equation such that an accurate data model is created based upon sample observations and the equation can then be used to predict the response for new data that was not seen during the estimation phase.
This is also called statistical learning or machine learning or more specifically supervised learning.
The learning algorithm with its configuration of parameters tries to guess the hypothesis function from a set of all functions possible in that hypothesis space.
Reducible error is the error arising from the mismatch between f̂ and f. f is the true relationship between X and Y, but we can’t see f directly— we can only estimate it. We can reduce the gap between our estimate and the true function by applying improved methods. Reducible error is again of 2 types: bias, variance
Error due to bias Sometimes the method is too rigid, failing to capture key features in the training set (“underfitting”) and thus yielding models that are too simple-minded.
The resulting errors are said to be due to bias since the method is biased toward certain outcomes in spite of what the training set says.
Error due to variance Other times the method is too sensitive to the training set, capturing noise that doesn’t generalize beyond the training set (“overfitting”).
Errors arising from this situation are said to be due to variance since the method generates models that vary strongly across training sets.
Irreducible error arises from the fact that X doesn’t completely determine Y. That is, there are variables outside of X — and independent of X— that still have some small effect on Y. For example competitor positioning and offerings is an independent variable that has an impact on customer satisfaction too. But since this variable was not a part of the study and estimation, this gives rise to an error which we can’t reduce in any manner.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.








A very well curated article. I have read about Bias-variance trade-off before. This article helped me cement the idea. Would revisit it again! Thanks Namrata :)
The BIAS OF AN ESTIMATOR graphic is not being displayed.