This article was published as a part of the Data Science Blogathon.
Boosting Algorithm In Machine Learning
Boosting can be referred to as a set of algorithms whose primary function is to convert weak learners to strong learners. They have become mainstream in the Data Science industry because they have been around in the machine learning community for years. Boosting was first introduced by Freund and Schapire in the year 1997 with their AdaBoost algorithm, and since then, Boosting has been a prevalent technique for solving binary classification problems.
Why are Boosting algorithms are so popular?
To understand this, in simpler words boosting algorithms can outperform simpler algorithms like Random forest, decision trees, or logistic regression. It is one of the primary reasons for the rise in promoting algorithms by many machine learning competitors because boosting algorithms are powerful. Still, they can improve the prediction accuracy of your model by a considerable amount of factors. Many machine learning competitors either use a single boosting algorithm or multiple boosting algorithms to solve the respective problems.
Boosting Algorithm Explained
Boosting combines the weak learners to form a strong learner, where a weak learner defines a classifier slightly correlated with the actual classification. In contrast to a weak learner, a strong learner is a classifier associated with the correct categories.
To understand this, let us assume a scenario:
Suppose you build a Random forest model that gives you an accuracy of 75% on the validation dataset, and next, you decide to try some other model on the same dataset. Suppose you try linear regression and kNN model on the same validation dataset, and now your model gives you an accuracy of 69% and 92%, respectively. It is clear that all three models work in entirely different ways and provide completely different results on the same dataset.
Have you ever thought, instead of just using one of these models, what if we use a combination of all these models for making the final predictions?
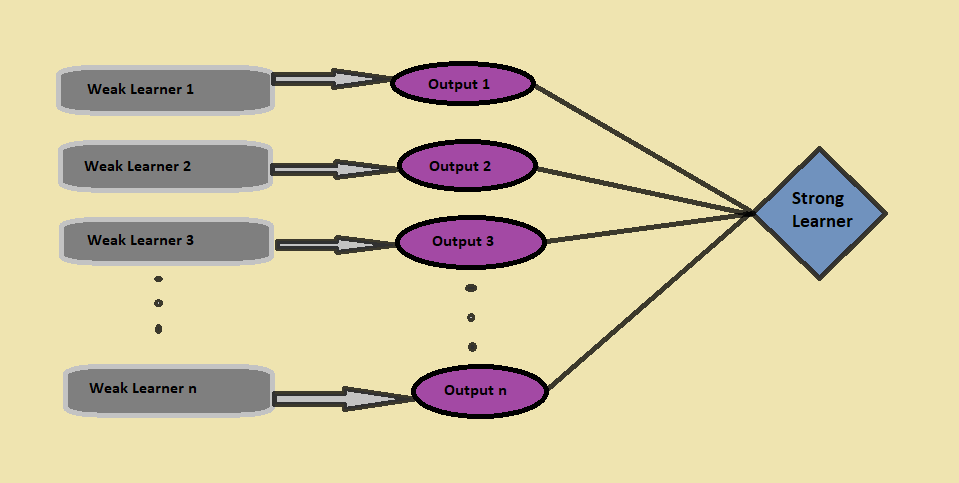
We will capture more information from the data by taking the average of predictions from these models; similarly, the boosting algorithm combines multiple simpler models (also called weak learners) to generate the final output (also called a strong learner).
Now you would think about how to identify weak learners?
To identify weak learners, we use machine learning algorithms with a different distribution for each iteration, and for each algorithm, it generates a new weak prediction rule. After many iterations, the boosting algorithm combines all the vulnerable learners to form a single string prediction rule.
Another essential thing to notice here is, ‘How do we determine different distribution for each round?’
There are three steps we need to consider to choose the correct distribution:
- The weak learner considers all the distributions and then assigns equal weight to each observation, then
- .If the error is caused by prediction from the first weak learning algorithm, more attention is given to the observations’ prediction error. The following weak learning algorithm is applied.
- Last, iterate through the 2nd step until the base learning algorithm reaches its limit or desirable accuracy is achieved.
At last, as a result, the boosting algorithm combines all the outputs from the weak learners. It comes up with a more powerful, strong learner, which eventually improves the model’s prediction accuracy ( as seen in above fig.).
In boosting, rather than just combining the isolated classifiers, it uses the mechanism of uplifting the weights of misclassified data points in the preceding classifiers.
Types of Boosting Algorithms
Time to look into some of the essential types of boosting algorithms now
1. Gradient Boosting
In the gradient boosting algorithm, we train multiple models sequentially, and for each new model, the model gradually minimizes the loss function using the Gradient Descent method. The Gradient Tree Boosting algorithm takes decision trees as the weak leaners because the nodes in a decision tree consider a different branch of features for selecting the best split, which means all the trees are not the same. Hence, they can capture different outputs from the data all the time.
The gradient tree boosting algorithm is sequentially built because, for each new tree, the model considers the errors of the last tree, and the decision of every successive tree is built on the mistakes made by the previous tree.
Gradient Boosting algorithms is mainly used for classification and regression problems.
Python Code:
from sklearn.ensemble import GradientBoostingClassifier #For Classification
from sklearn.ensemble import GradientBoostingRegressor #For Regression
cl = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1)
cl.fit(Xtrain, ytrain)
where:
n_estimators parameter is used to control the number of weak learners,
learning_rate parameter controls the contribution of all the vulnerable learners in the final output,
max_depth parameter is for the maximum depth of the individual regression estimators to limit the number of nodes in the tree.
2. AdaBoost (Adaptive Boosting)
The AdaBoost algorithm, short for Adaptive Boosting, is a Boosting technique in Machine Learning used as an Ensemble Method. In Adaptive Boosting, all the weights are re-assigned to each instance where higher weights are given to the incorrectly classified models, and it fits the sequence of weak learners on different weights.
Adaboost starts by making predictions on the original dataset in easy language, and then it gives equal weights to each observation. If the prediction made using the first learner is incorrect, it allocates the higher importance to the incorrectly predicted statement and an iterative process. It goes on to add new learners until the limit is reached in the model.
We can use any machine learning algorithm with Adaboost as weak learners if it accepts weights on the training dataset and it is used for both regression and classification problem.
Python Code:
from sklearn.ensemble import AdaBoostClassifier #For Classification
from sklearn.ensemble import AdaBoostRegressor #For Regression
from sklearn.tree import DecisionTreeClassifier
dtree = DecisionTreeClassifier()
cl = AdaBoostClassifier(n_estimators=100, base_estimator=dtree,learning_rate=1)
cl.fit(xtrain,ytrain)
where:
n_estimators and learning_rate parameter serves the same purpose as in the case of Gradient Boosting algorithm,
base_estimator parameter helps to specify different machine learning algorithms.
3. XGBoost
The XGBoost algorithm, short for Extreme Gradient Boosting, is simply an improvised version of the gradient boosting algorithm, and the working procedure of both is almost the same. One crucial point in XGBoost is that it implements parallel processing at the node level, making it more powerful and fast than the gradient boosting algorithm. XGBoost reduces overfitting and improves overall performance by including various regularization techniques by setting the hyperparameters of the XGBoost algorithm.
One important point to note about XGBoost is that you don’t need to worry about the missing values in the dataset because, during the training process, the model itself learns where to fit the missing values, i.e., left node or the correct node.
XGBoost is mainly used for classification problems but can be used for regression problems.
Python Code:
import xgboost as xgb
xgb_model = xgb.XGBClassifier(learning_rate=0.001, max_depth=1, n_estimators_100)
xbg_model.fit(x_train, y_train)
END NOTES
This article looked at boosting algorithms in machine learning, explained what is boosting algorithms, and the types of boosting algorithms: Adaboost, Gradient Boosting, and XGBoost. We also looked at their respective python codes and parameters involved.
If you have any questions, you can reach out to me on my LinkedIn @mrinalwalia.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Mrinal Singh Walia
26 Feb, 2024







