This paper focuses on evaluating the machine learning models based on hyperparameter tuning. Hyperparameter tuning is choosing a set of optimal hyperparameters for a learning algorithm. A hyperparameter is a model argument whose value is set before the learning process begins. The key to machine learning algorithms is hyperparameter tuning.
The trade-off between these components is determined by the complexity of the model and the amount of training data. The optimal hyperparameters help to avoid under-fitting (training and test error are both high) and over-fitting (Training error is low but test error is high)
Workflow: One of the core tasks of developing an ML model is to evaluate its performance. There are multiple stages in developing an ML model for use in software applications.
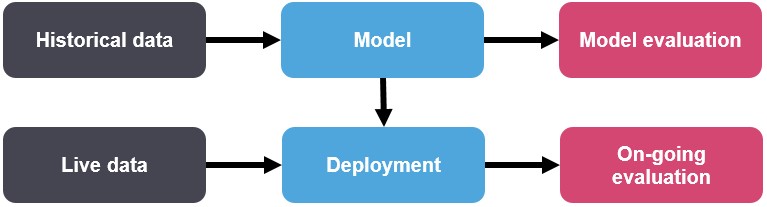
Figure 1: Workflow
Evaluation: Model evaluation and ongoing evaluation may have different matrices. For example, model evaluation may include Accuracy or AUROC and ongoing evaluation may include customer lifetime value. Also, the distribution of the data might change between the historical data and live data. One way to detect distribution drift is through continuous model monitoring.
Hyper-parameters: Model parameters are learned from data and hyper-parameters are tuned to get the best fit. Searching for the best hyper-parameter can be tedious, hence search algorithms like grid search and random search are used.
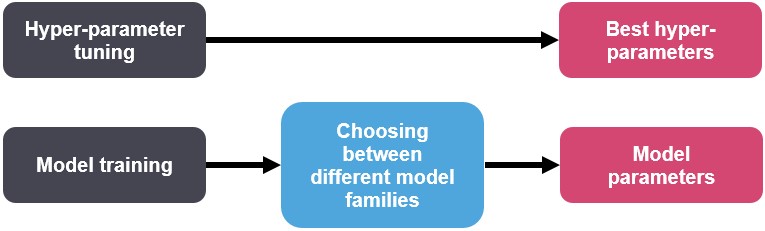
Figure 2: Hyper-parameter tuning vs Model training
Evaluation Matrices: These are tied to ML tasks. There are different matrices for supervised algorithms (classification and regression) and unsupervised algorithms. For example, the performance of classification of the binary class is measured using Accuracy, AUROC, Log-loss, and KS.
Evaluation Mechanism: Model selection refers to the process of selecting the right model that fits the data. This is done using test evaluation matrices. The results from the test data are passed back to the hyper-parameter tuner to get the most optimal hyperparameters.
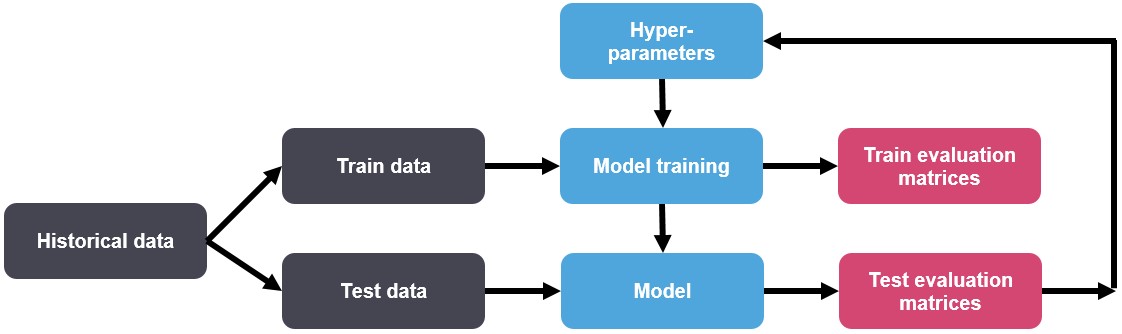
Figure 3: Evaluation Mechanism
Hyperparameters: Vanilla linear regression does not have any hyperparameters. Variants of linear regression (ridge and lasso) have regularization as a hyperparameter. The decision tree has max depth and min number of observations in leaf as hyperparameters.
Optimal Hyperparameters: Hyperparameters control the over-fitting and under-fitting of the model. Optimal hyperparameters often differ for different datasets. To get the best hyperparameters the following steps are followed:
1. For each proposed hyperparameter setting the model is evaluated
2. The hyperparameters that give the best model are selected.
Hyperparameters Search: Grid search picks out a grid of hyperparameter values and evaluates all of them. Guesswork is necessary to specify the min and max values for each hyperparameter. Random search randomly values a random sample of points on the grid. It is more efficient than grid search. Smart hyperparameter tuning picks a few hyperparameter settings, evaluates the validation matrices, adjusts the hyperparameters, and re-evaluates the validation matrices. Examples of smart hyper-parameter are Spearmint (hyperparameter optimization using Gaussian processes) and Hyperopt (hyperparameter optimization using Tree-based estimators).
Lorem ipsum dolor sit amet, consectetur adipiscing elit,







