This article was published as a part of the Data Science Blogathon.
Introduction
Operationalizing a Machine Learning (ML) model in production needs a lot more than just creating and validating models like in academia or research. The ML application in production can be a pipeline with multiple components running consecutively as shown in Fig 1.
Before we reach model training in the pipeline, various components like Data Ingestion, Data versioning, Data validation, and Data pre-processing need to be executed. Here, we will discuss the Data Validation and have arranged this article as below:
- What is data validation?
- Why is data validation required?
- What are the challenges with data validation?
- How does the data validation component work?
- Examples of data validation components available in the market.

1) What is data validation?
Data validation means checking the accuracy and quality of source data before training a new model version. It ensures that anomalies that are infrequent or manifested in incremental data are not silently ignored. It focuses on checking that the statistics of the new data are as expected (e.g. feature distribution, number of categories, etc).
Different types of validation can be performed depending on objectives and constraints. Examples of such objectives in the machine learning pipeline are below –
- Are there any anomalies or data errors in the incremental data? If yes, raise an alert to the team for investigation.
- Are there any assumptions on data that are taken during model training and are getting violated during serving? If yes, raise an alert to the team for investigation.
- Are there significant differences between training and serving data? Or, Are there differences between successive data that are getting added into training data? If yes, raise an alert to investigate differences in training and serving code stack.
Output from the data validation steps should be informative enough for a data engineer to take action. Also, it needs to have high precision as too many false alarms will easily be lost credibility.
2) Why is data validation required?
Machine learning models are vulnerable to poor data quality as per the old adage “garbage in garbage out”.
In production, the model gets re-trained with a fresh set of incremental data added periodically (as frequent as daily) and the updated model is pushed to the serving layer. The model makes predictions with new incoming data while serving and the same data is added with actual labels and used for retraining. This ensures that the newly generated model adapts to the changes in data characteristics.
However, the new incoming data in the serving layer can change due to various reasons like code changes that introduces errors in the serving data ingestion component or the difference between training and serving stacks. With time, the erroneous ingested data will become part of the training data, which will start degrading the model accuracy. Since In each iteration, newly added data is generally a small fraction of overall training data, hence, the changes in model accuracy will be easily missed and the errors will keep adding with time.
Thus, catching the data errors at an early stage is very important because it will reduce the cost of data error which is bound to increase as the error propagates further in the pipeline (as shown in fig 2).

3) What are the challenges with the data validation?
There are various challenges that a data scientist faces while developing a data validation component, such as
- Creating data validation rules for a dataset with few columns does sound simple. However, when the number of columns in datasets increases, it becomes a humongous task.
- Tracking and comparing metrics from the historical datasets to find anomalies in historical trends for each column needs a good amount of recurring time from a data scientist.
- Today applications are expected to run 24-by-7 and in such scenarios, data validation needs to be automated. The data validation component should be smart enough to refresh validation rules.
4) How does the data validation component work?
Think of the data validation component as a guard post of the ML application that does not let bad quality data in. It keeps a check on each and every new data entry that is going to add to the training data. As shown in Fig 3, the data validation framework can be summarised in 5 steps:
- Calculate the statistics from the training data against a set of rules
- Calculate the statistics of the ingested data that has to be validated
- Compare the statistics of the validation data with the statistics from the training data
- Store the validation results and takes automated actions like removing the row, capping, or flooring the values
- Sending the notification and alerts for approval

5) Examples of data validation components available in the market
Amazon Research [1] and Google Research [2] proposed a very similar approach to building a data validation component. Overall, both approaches follow the same workflow as given in Fig 2. We will discuss both approaches here.
5.1) Unit-test approach for data validation by Amazon Research (Deequ)
In software engineering, engineers write unit tests to test their code. Similarly, unit tests should also be defined to test the incoming data. Authors have defined a framework to define this component that follows the below principles –
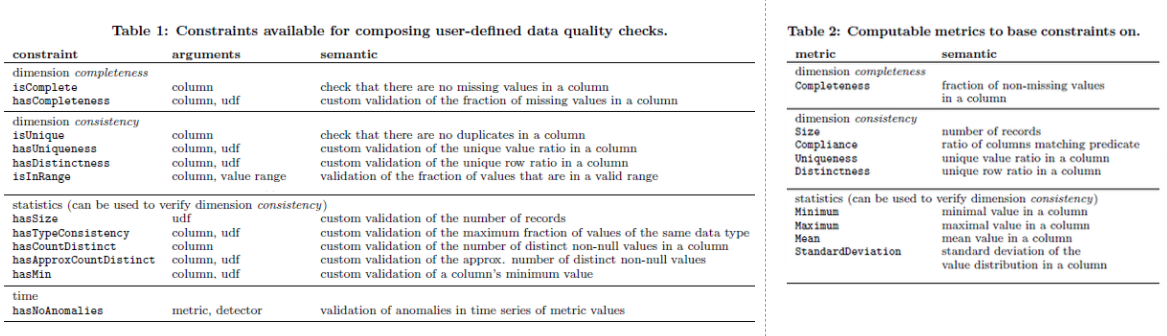
- a) Declare constraints: User defines how their data should look like. It works by declaring checks on their data by composing constraints on various columns. A list of constraints is shown in Table 1 below.
- b) Compute metrics: Based on the declared constraint, translate them to measurable metrics as shown in Table 2 below. These metrics can be computed and compared between the data in hand and the incremental data.
- c) Analyze and report: Based on the collected metrics over time, predict if the metric on the incremental data is an anomaly or not. As a rule, the user can have the system issue “a warning” if the new metric is more than three standard deviations away from the previous mean or throw “an error” if it is more than four standard deviations away. Basis the analysis, report the constraints that fail including the value(s) that made the constraint fail.
5.2) Data schema approach for data validation by Google Research (Tensorflow data validation)
Google Research has come up with a very similar technique but adopted “battle-tested” principles from the data management system and customized it for ML. This technique first codifies the expectation from correct data and then using these expected statistics along with user-defined validation schema performs data validation. This data validation framework consists of 3 sub-component as also shown in Fig 4.
- Data Analyzer – computes a predefined set of data statistics required to define the data
- Data Validator – checks for properties of data as specified through a schema. This schema is a precursor for a data validator to perform. This schema list out all the constraints on the features for basic checks and ML-related checks.
- Model Unit Tester – checks for errors in training code using synthetic data generated through the schema
This framework gives the user the ability to
- validate a single batch of incremental data by detecting anomalies in it
- Detect significant changes between successive batches of incremental training data. Few anomalies are not visible when checking only a single batch but manifest when we look at successive batches.
- Find assumptions in the training code that are not reflected in the data (e.g. if a feature is expected to have log() in the training code should not have -ve value or string values). The goal here is to cover those constraints that are missed to add into the schema. It happens in 2 steps
-
- Synthetic training examples that adhere to the schema constraints are generated
- This generated data is iterated through the training code for checking errors

Both Amazon Research and Google Research approaches to provide users with suggestions such as constraints in the Amazon framework and recommendations to update schema in the google framework. Both approaches treat data as a first-class citizen in ML pipelines and do data validation before putting data into the system. However, there are few differences worth noting.
| Deequ (Amazon) | Tensorflow data validation (Google) | |
| 1 | No visualization available | Provides visualization using Google Facets. It summarises statistics for each feature and compares the training and validation data. |
| 2 | Recalculates training statistics by aggregating prior saved training statistics and new data statistics. | Calculates statistics on whole training data in every run unless specified. This may become computationally expensive. |
| 3 | Provides capability to do anomaly detection based on running average and standard deviation in addition to the threshold or absolute/relative difference from training data. | Provides capability to do anomaly detection based on the threshold or absolute/relative difference from training data. |
| 4 | Supports data only in SparkDataFrame. | Supports pandas dataframe, CSV, and best works with TFRecord. |
Table 3: Differences between Data Validation libraries
References
- S. Schelter, D. Lange, P. Schmidt, M. Celikel, F. Viessmann and A. Grafberger, “Automating Large-Scale Data Quality Verification” in Proceedings of the VLDB endowment, volume 11, Issue 12: 1781-1794, 2018. Available: http://www.vldb.org/pvldb/vol11/p1781-schelter.pdf
- E. Breck, M. Zinkevich, N. Polyzotis, S. Whang and S. Roy, “Data validation for machine learning”, in Proceedings of the 2nd SysML Conference, Palo Alto, CA, USA, 2019. Available: https://mlsys.org/Conferences/2019/doc/2019/167.pdf
Authors:
Aditya Aggarwal serves as Data Science – Practice Lead at Abzooba Inc. With more than 12+ years of experience in driving business goals through data-driven solutions, Aditya specializes in predictive analytics, machine learning, business intelligence & business strategy across a range of industries. As the Advanced Analytics Practice Lead at Abzooba, Aditya leads a team of 50+ energetic data science professionals at Abzooba that are solving interesting business problems using machine learning, deep learning, Natural Language Processing, and computer vision.
He provides thought leadership in AI to clients to translate their business objectives into analytical problems and data-driven solutions. Under his leadership, several organizations have automated routine tasks, reduced operational cost, boosted team productivity, and improved top-line and bottom-line revenues. He has built solutions such as subrogation engine, price recommendation engine, IoT sensor predictive maintenance, and more. Aditya holds a Bachelor of Technology and Minor Degree in Business Management from the Indian Institute of Technology (IIT), Delhi.
Dr Arnab Bose is Chief Scientific Officer at Abzooba, a data analytics company, and an adjunct faculty at the University of Chicago where he teaches Machine Learning and Predictive Analytics, Machine Learning Operations, Time Series Analysis, and Forecasting, and Health Analytics in the Master of Science in Analytics program. He is a 20-year predictive analytics industry veteran who enjoys using unstructured and structured data to forecast and influence behavioral outcomes in healthcare, retail, finance, and transportation.
His current focus areas include health risk stratification and chronic disease management using machine learning, and production deployment and monitoring of machine learning models. Arnab has published book chapters and refereed papers in numerous Institute of Electrical and Electronics Engineers (IEEE) conferences & journals. He has received Best Presentation at American Control Conference and has given talks on data analytics at universities and companies in the US, Australia, and India. Arnab holds MS and Ph.D. degrees in electrical engineering from the University of Southern California, and a B.Tech. in electrical engineering from the Indian Institute of Technology at Kharagpur, India.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.







Hey thanx for sharing this blog over here. It seems useful to start career in clinical research. We will look forward for more updates.