Introduction
Everyone dealing with data in any capacity has to be conversant in both SQL and Python. Python has Pandas, which makes data import, manipulation, and working with data, in general, easy and fun. On the other hand, SQL is the guardian angel of Databases across the globe. It has retained its rightful grip on this field for decades.
By this monopolistic hold, the data being stored by an organization, especially the Relational Databases, needs the use of SQL to access the database and create tables and some operations on the tables. Most of these operations can be done in Python using Pandas as well. Through experience, I have noticed that SQL is more efficient (and hence easy to use) for some operations, and for others, Pandas has the upper hand (and hence more fun to use).
This article aims to introduce you to “Best of Both Worlds.” You shall know how to do operations in both of these interchangeably. This will be useful to those with experience working with SQL but new to Python. Just one more thing: This is my first attempt to marry SQL and Python. Watch out this space for more such articles, and leave your demand for specific topics in comments for me to write about them.
So, let us begin with our journey without any further ado.

Learning Objectives
- Connectivity with pyodbc: Understand pyodbc’s role in connecting Python to SQL databases for efficient data interactions.
- Installation and Import: Learn to install and import pyodbc, enabling dynamic Python-ODBC connectivity.
- Server Connection: Establish connections to SQL servers, differentiating between trusted and non-trusted methods.
- Query Execution: Execute SQL queries from Python, emphasizing cursor definition for effective operations.
- Data Import with Pandas: Import SQL data into Python as Pandas DataFrames using read_sql functions for further analysis.
This article was published as a part of the Data Science Blogathon.
Installing and Importing the library pyodbc
We are going to use the library named pyodbc to connect Python to SQL. This will give us the ability to use the dynamic nature of Python to build and run queries like SQL. These two languages together are a formidable force in our hands. Together, these can take your code to the pinnacle of automation and efficiency.
Step 1: Install pyodbc using pip or visit their webpage.
pip install pyodbcand then import the library into your Jupyter notebook
import pyodbcpyodbc is going to be the bridge between SQL and Python. This makes access to ODBC (Open Database Connectivity) databases easy. SQL Access Group developed ODBC in the early ’90s as an API (Application Programming Interface) to access databases. These DBMS (Database management Systems) are compliant with ODBC drivers.
- MySQL
- MS Access
- IBM Db2
- Oracle
- MS SQL Server
I am presently working on MS SQL Server, and that’s what I will be using for this article as well. However, the same codes can be used for any other ODBC-compliant database. Only the connection step will vary a little.
Connection to the SQL Server
We need to establish the connection with the server first and use pyodbc.connect the connector function for the same. This function needs connection string as a parameter. The connection string can be defined and declared separately. Let’s have a look at the sample connection String.
There can be two types of connection Strings. One when the connection is trusted and another where you must enter your User_id and Password. You would know which one you use from your SQL Server Management Studio.
For Trusted Connection
connection_string = ("Driver={SQL Server Native Client 11.0};"
"Server=Your_Server_Name;"
"Database=My_Database_Name;"
"Trusted_Connection=yes;")For Non-Trusted Connection
connection_string = ("Driver={SQL Server Native Client 11.0};"
"Server=Your_Server_Name;"
"Database=My_Database_Name;"
"UID=Your_User_ID;"
"PWD=Your_Password;")You need the following to access:
- Server
- Database
- User ID
- Password
Let me help you locate your Server Name and Database
Get Server Name
You can find the server name in two ways. One is to have a look at your SQL Server Management login window.
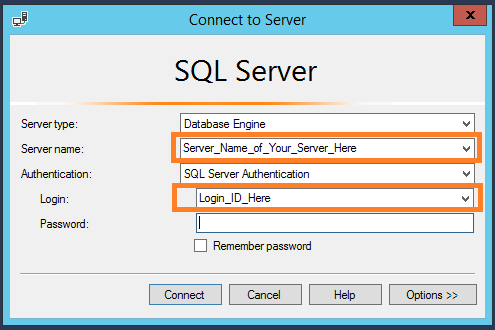
The other way is to run the following query in SQL.
SELECT @@SERVERNAMEGet Database
You need to give the name of the database in which your desired table is stored. You can locate the database name in the Object Explorer menu under the Databases section. This is located on the left-hand side of your SQL server.
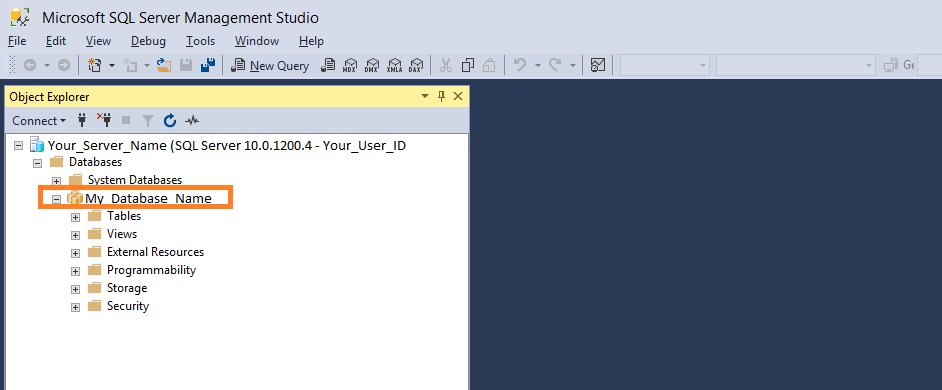
In our case, the Database Name is My_Database_Name.
Get UID
You can find the User ID in your SQL Server Management login window. The Login_ID_Here is the user name.
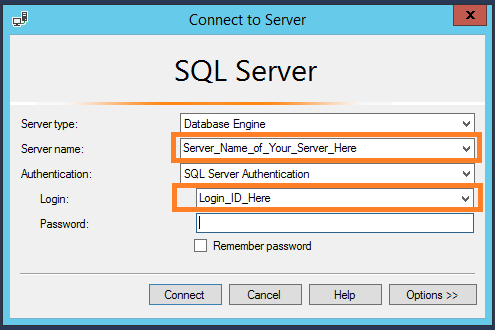
Once you have written the connection_string, you can initialize the connection by calling the pyodbc.connect function as below.
connection = pyodbc.connect(connection_string)Note: In case you have ever used SQL database connection with any other software or environment (like SAS or R), you can copy the values of the above parameters from the connection string used there as well.
In [1]:
# Lets summarise the codes till now
import pyodbc
connection_string = ("Driver={SQL Server Native Client 11.0};"
"Server=Your_Server_Name;"
"Database=My_Database_Name;"
"UID=Your_User_ID;"
"PWD=Your_Password;")
connection = pyodbc.connect(connection_string)Running the Query in SQL from Python
Now that you have established the connection of the SQL server with Python, you can run the SQL queries from your Python environment (Jupyter Notebook or any other IDE).
To do so, you need to define the cursor. Let’s do that here.
Let us run a simple query to select the first 10 rows of a table in the database defined in the connection_string, table name as State_Population.
In [2]:
# Initialise the Cursor
cursor = connection.cursor()
# Executing a SQL Query
cursor.execute('SELECT TOP(10) * FROM State_Population')This executes the query, but you will not see any output in python, as the query is executed in SQL. However, you can print the results, which will be the same as the ones returned inside the SQL server.
In [3]:
for row in cursor:
print(row)Out[3]:
(AL, under18, 2012, 1117489.0)
(AL, total, 2012, 4817528.0)
(AL, under18, 2010, 1130966.0)
(AL, total, 2010, 4785570.0)
(AL, under18, 2011, 1125763.0)
(AL, total, 2011, 4801627.0)
(AL, total, 2009, 4757938.0)
(AL, under18, 2009, 1134192.0)
(AL, under18, 2013, 1111481.0)
(AL, total, 2013, 4833722.0)This way, you can see the result in Python, which is useless for further processing. Importing the table as a Pandas DataFrame in the Python environment would be useful. Let us do that now.

Bringing SQL table in Python
Pandas bring a data structure in Python, which is similar to a SQL (or for that matter, any other) table. That’s Pandas DataFrame for you. So it’s prudent to import the data from SQL to Python in form of Pandas DataFrame. Pandas have import functions that read SQL data types.
These are the three functions pandas provide for reading from SQL.
- pandas.read_sql_table()
- pandas.read_sql_query()
- pandas.read_sql()
The read_sql_table function takes a table name as a parameter, the read_sql_query function takes SQL query as a parameter. The third one, read_sql is a wrapper function around the above two. It takes either, a table name or a query, and imports the data from SQL to Python in form of a DataFrame.
Also, notice how we give the SQL query in form of a string, and also tell the function the name of the connection.
In [4]:
import pandas as pd
# Using the same query as above to get the output in dataframe
# We are importing top 10 rows and all the columns of State_Population Table
data = pd.read_sql('SELECT TOP(10) * FROM State_Population', connection)In [5]:
dataOut[5]:
state/region ages year population
0 AL under18 2012 1117489.0
1 AL total 2012 4817528.0
2 AL under18 2010 1130966.0
3 AL total 2010 4785570.0
4 AL under18 2011 1125763.0
5 AL total 2011 4801627.0
6 AL total 2009 4757938.0
7 AL under18 2009 1134192.0
8 AL under18 2013 1111481.0
9 AL total 2013 4833722.0Notice the output above; it’s the same as expected from any local data file (say .csv or excel) imported in Python as Pandas DataFrame.
We can write the query outside the function and call it by the variable name as well. Let us import another table named state_areas, which has the name of the states and their area in Square Miles. But instead of calling the first 10 rows, we would like to see all the states whose area is more than 100,000 Square miles.
In [6]:
# write the query and assign it to variable
query = 'SELECT * FROM STATE_AREAS WHERE [area (sq. mi)] > 100000'
# use the variable name in place of query string
area = pd.read_sql(query, connection)In [7]
areaOut[7]:
state area (sq. mi)
0 Alaska 656425
1 Arizona 114006
2 California 163707
3 Colorado 104100
4 Montana 147046
5 Nevada 110567
6 New Mexico 121593
7 Texas 268601Conclusion
This article provided a comprehensive guide on leveraging the powerful combination of SQL and Python modules, particularly using the pyodbc library. By seamlessly integrating these two robust technologies, users can unlock efficient data manipulation, analysis, and automation possibilities. The article delved into the essential steps, from installing and importing the pyodbc library to establishing connections with SQL servers, running queries, and importing SQL tables into Python as Pandas DataFrames.
The tutorial emphasized the versatility of pyodbc, making it a bridge between SQL and Python, facilitating easy access to ODBC-compliant databases like MySQL, MS Access, IBM Db2, Oracle, and Microsoft SQL Server database. The detailed instructions on creating connection strings for trusted and non-trusted connections provided valuable insights into the initial setup process. The demonstration using MS SQL Server as an example assured readers that the same principles can be applied to other ODBC-compliant databases with minor variations in the connection steps.
The article showcased the seamless execution of SQL queries within Python, highlighting the significance of defining a cursor for query execution. The tutorial also demonstrated how to bring SQL tables into Python as Pandas DataFrames, enhancing the usability of the data for further analysis and processing. The use of Pandas functions, such as read_sql_table(), read_sql_query(), and read_sql(), showcased the flexibility and convenience of importing data from SQL to Python.
As technology enthusiasts embark on this journey to combine the strengths of SQL and Python, key concepts such as authentication, data sources, database APIs, and schema become integral. Including keywords like GitHub, Linux, MacOS, mkleehammer, tutorial, and source code indicates the importance of collaborative development, cross-platform compatibility, and educational resources in the realm of SQL and Python integration.
Key Takeaways
- Importance of Python and SQL in Data Handling:
- Python, with its Pandas library, is efficient for data manipulation and analysis.
- SQL remains crucial for accessing and managing relational databases.
- Best of Both Worlds:
- The article aims to bridge Python and SQL, allowing users to interchangeably perform operations in both languages.
- pyodbc for Connectivity:
- The use of pyodbc is emphasized for connecting Python to SQL databases.
- pyodbc serves as a bridge for ODBC-compliant databases like MySQL, MS Access, IBM Db2, Oracle, and MS SQL Server.
- Steps for Connection:
- Detailed steps for installing pyodbc using pip and importing the library.
- Explanation of connection strings for both trusted and non-trusted connections, including Server, Database, User ID, and Password.
- Executing SQL Queries and Importing Data:
- Demonstrates how to establish a connection to SQL servers using pyodbc.
- Shows the execution of SQL queries from Python, highlighting the importance of defining a cursor.
- Illustrates importing SQL data into Python as Pandas DataFrames using read_sql functions for further analysis.
You can also look at these similar articles —
Frequently Asked Questions
Q1. What is pyodbc used for?
Ans. pyodbc is used to connect Python applications to databases, facilitating the execution of SQL queries and management of database interactions.
Q2. Is pyodbc a Python library?
Ans. Yes, pyodbc is a Python library designed for connecting Python programs to ODBC-compliant databases.
Q3. How do I run a SQL query in Python pyodbc?
Ans. Install pyodbc, establish a connection to the database, create a cursor, execute the SQL query, and process the results.
Q4. Can pyodbc connect to PostgreSQL?
Ans. Yes, though pyodbc primarily targets ODBC-compliant databases, it can be used with PostgreSQL through ODBC drivers. However, many prefer using psycopg2 for direct PostgreSQL connectivity.
Q5. What is the difference between pyodbc and Sqlalchemy?
Ans. pyodbc focuses on low-level ODBC connectivity, providing a direct interface for executing SQL queries. Sqlalchemy is an ORM, abstracting database operations and offers a higher-level, Pythonic interface for various database systems. Use pyodbc for direct connectivity and Sqlalchemy for ORM features.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Nilabh Nishchhal
25 Feb, 2024








Great article! Was very helpful and clear instructions on setup for SQL with python, thanks
Error: ('01000', "[01000] [unixODBC][Driver Manager]Can't open lib 'ODBC Driver 17 for SQL Server' : file not found (0) (SQLDriverConnect)") please tell me ,how to solve this issue.