This article was published as a part of the Data Science Blogathon
Hyperparameters for a model can be chosen using several techniques such as Random Search, Grid Search, Manual Search, Bayesian Optimizations, etc. In this article, we will learn about GridSearchCV which uses the Grid Seach technique for finding the optimal hyperparameters to increase the model performance.
In this article, we will apply GridSearchCV on a dataset using 3 different estimators. We will also compare the Tuned and Untuned Models under each algorithm applied. In the end, we will compare the performance scores of all three Tuned Models and will create inference based on it.

GridSearchCV is a function that finds the best hyperparameters using Grid Search and Cross-Validation and fit the passed estimator with the found best hyperparameters. GridSearch is a technique which takes all combination of hyperparameters values and measures the performance of each combination. In the end, it selects the best value for the specified hyperparameters.
Grid Search itself is a lengthy and expensive process. In GridSearchCV, Cross-Validation is also performed. Thus, depending on the number of folds (in K-fold Cross Validation), the process may get more time-consuming and expensive. As a result, GridSearchCV is known as a time-consuming process.

Image by Pixabay from Pexels
.GridSearchCV() function is available in the class sklearn.model_selection. GridSearchCV() takes the following parameters:
1. estimator – A scikit-learn model, which is the ML algorithm.
2. param_grid – A dictionary with parameter names as keys and lists of parameter values.
3. scoring – Accuracy measure. For example, ‘r2’ for regression models, ‘recall’ for classification models.
4. cv – The number (int) of folds for K-fold cross-validation.
First, let’s build a Random Forest classification model which will be used as an estimator in GridSearchCV()
Importing the Libraries
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('heart.csv')
Here we are going to use the HeartDiseaseUCI dataset downloaded from Kaggle.
Specifying Independent and Dependent Variables
X = df.drop('target', axis = 1)
y = df['target']
Python Code:
rfc = RandomForestClassifier()
Here, we created the object rfc of RandomForestClassifier().
Initializing GridSearchCV() object and fitting it with hyperparameters
forest_params = [{'max_depth': list(range(10, 15)), 'max_features': list(range(0,14))}]
clf = GridSearchCV(rfc, forest_params, cv = 10, scoring='accuracy')
clf.fit(X_train, y_train)
Here, we passed rfc as an estimator, forest_params as param_grid, cv = 10 and accuracy as scoring technique into GridSearchCV() as arguments.
Getting the Best Hyperparameters
print(clf.best_params_)
This will give the combination of hyperparameters along with values that give the best performance of our estimate specified.
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('heart.csv')
X = df.drop('target', axis = 1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)
rfc = RandomForestClassifier()
forest_params = [{'max_depth': list(range(10, 15)), 'max_features': list(range(0,14))}]
clf = GridSearchCV(rfc, forest_params, cv = 10, scoring='accuracy')
clf.fit(X_train, y_train)
print(clf.best_params_)
print(clf.best_score_)
On executing the above code, we get:
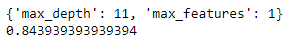
After tuning the model, we got the best hyperparameters values for max_depth = 11 and max_features = 1. The best score came out to be approximately 0.843
Note that this best score is the average cross-validated performance score.
Let’s get the Classification Report for Tuned and Untuned Random Forest Classifiers
print(metrics.classification_report(y_test, clf.predict(X_test)))
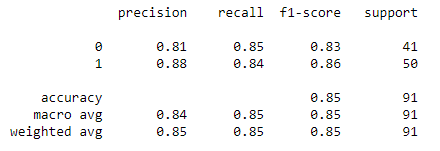
Thus, the Accuracy of the Tuned Random Forest Classifier came out to be 85%
rfc.fit(X_train, y_train) print(metrics.classification_report(y_test, rfc.predict(X_test)))
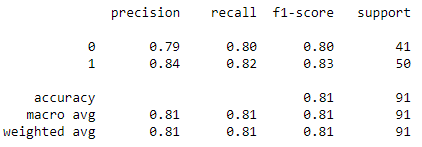
Thus, the Accuracy of the Untuned Random Forest Classifier came out to be 81%.
Here, Based on the accuracy results we can conclude that the Tuned Random Forest Classifier with the best parameters, specified using GridSearchCV, has more accuracy than the Untuned Random Forest Classifier.
Note that these results are based on the given dataset and conditions. The results may vary for different datasets or different random_state.
Now we will build the following models on the same dataset, followed by hyperparameter tuning.
1. Decision Tree Classifier
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
tuned_param = [{'max_depth': list(range(10, 15)), 'max_features': list(range(0,14))}]
clf_dtc = GridSearchCV(dtc, cv = 10, param_grid = tuned_param, scoring = 'accuracy')
clf_dtc.fit(X_train, y_train)
print(clf_dtc.best_params_)
print(clf_dtc.best_score_)
On executing this code, we get:

Here, we passed dtc as estimator, tuned_param as param_grid, cv = 10 and accuracy as scoring technique into GridSearchCV() as arguments.
After tuning the Decision Tree Classifier, we got the best hyperparameters values for max_depth = 11 and for max_features = 7. The best score came out to be approximately 0.778
Note that this best score is the average cross-validated performance score.
Let’s get the Classification Report for Tuned and Untuned Decision Tree Classifiers
A. Tuned Model:
print(metrics.classification_report(y_test, clf_dtc.predict(X_test)))
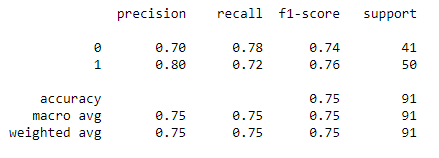
For the Tuned Decision Tree Classifier, the accuracy is 75% which is lower than the Tuned Random Forest Classifier (85%).
B. Untuned Model
dtc.fit(X_train, y_train) print(metrics.classification_report(y_test, dtc.predict(X_test)))
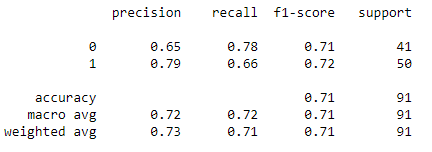
For the Untuned Decision Tree Classifier, the accuracy is 71% which is lower than the Untuned Random Forest Classifier (81%).
Here, Based on the accuracy results we can conclude that the Tuned Decision tree Classifier with the best parameters, specified using GridSearchCV, has more accuracy than the Untuned Decision Tree Classifier.
2. K-Nearest Neighbor Classifier
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
params = [{'n_neighbors': range(5,10),'metric': ['canberra', 'euclidean', 'minkowski']}]
clf_knn = GridSearchCV(knn, cv = 10, param_grid = params, scoring = 'accuracy')
clf_knn.fit(X_train, y_train)
print(clf_knn.best_params_)

Here, we passed the knn as an estimator, params as param_grid, cv = 10, and accuracy as a scoring technique into GridSearchCV() as arguments.
After tuning the K-Nearest Neighbor Classifier, we got the best hyperparameters values for metric = ‘canberra’ and for n_neighbors = 5. The best score came out to be approximately 0.834
Note that this best score is the average cross-validated performance score.
Let’s get the Classification Report for Tuned and Untuned KNN Classifiers
A. Tuned Model:
print(metrics.classification_report(y_test, clf_knn.predict(X_test)))
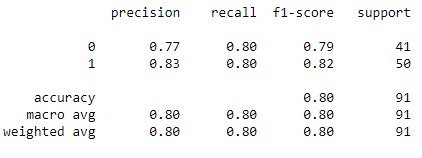
For the Tuned KNN Classifier, the accuracy is 80% which is lower than the Tuned Random Forest Classifier (85%) but higher than the Tuned Decision Tree Classifier (75%).
B. Untuned Model
knn.fit(X_train, y_train) print(metrics.classification_report(y_test, knn.predict(X_test)))
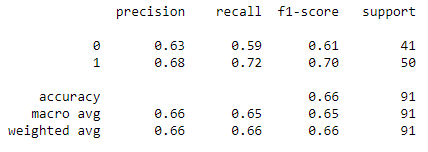
For the Untuned KNN Classifier, the accuracy is 66% which is way lower than the Untuned Random Forest Classifier (81%) and Decision Tree Classifier (71%)
Here, Based on the accuracy results we can conclude that the Tuned K-Nearest Neighbor Classifier with the best parameters, specified using GridSearchCV, has more accuracy than the Untuned K-Nearest Neighbor Classifier.
Here, We created a summary table using Pandas DataFrame to compare the best scores side by side.
df_best_scores = pd.DataFrame({'Estimators':['Random Forest', 'Decision Tree', 'KNN Classifier'],
'Best Scores':['{0:.3f}'.format(clf.best_score_), '{0:.3f}'.format(clf_dtc.best_score_), '{0:.3f}'.format(clf_knn.best_score_)]})
print(df_best_scores)
On executing this code, we get:
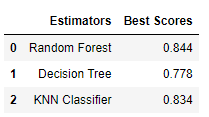
Based on the summary table, we can conclude that Random Forest Classifier (0.844) outperformed all the considered Estimators for the given dataset. Next, comes the KNN Classfieir which performed a little less (0.834) than Random Forest Classifier. The Decision Tree Classifier performed the worst among the three estimators. (0.778).
In this article, we performed two comparisons. First, among each estimator, we compared the Accuracy before and after tuning the estimator. Second, we compared the GridSearchCV best scores of all the estimators. As mentioned earlier, these are results are specific to these problems only one cannot generalize the results for the problems. Thus, it would be incorrect to say that Random Forest is the best Classifier or Decision Tree Classifier is the worst. In another example, one may find Decision Tree Classf8er performing better than other Classifiers. One can try experimenting with the results by changing the GridSearchCV() arguments or with a different dataset because one always learns by trying.
About the Author
Connect with me on LinkedIn Here.
Check out my other Articles Here
You can provide your valuable feedback to me on LinkedIn.
Thanks for giving your time!
The media shown in this article on comparison of Tuned and Untuned Classification Models are not owned by Analytics Vidhya and are used at the Author’s discretion.
IT Engineering Graduate currently pursuing Post Graduate Diploma in Data Science.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,







