This article was published as a part of the Data Science Blogathon
– what is RNN?
– Forward propagation in RNN
– Backward propagation in RNN
– Types of RNN architectures
– Applications of RNN
- Recurrent neural network is a type of neural network in which the output form the previous step is fed as input to the current step
- In traditional neural networks, all the inputs and outputs are independent of each other, but this is not a good idea if we want to predict the next word in a sentence
- We need to remember the previous word in order to generate the next word in a sentence, hence traditional neural networks are not efficient for NLP applications
- RNNs also have a hidden stage which used to capture information about a sentence
- RNNs have a ‘memory’, which is used to capture information about the calculations made so far
- In theory, RNNs can use information in arbitrary long sequences, but practically they are limited to look back only a few steps
.jpg)
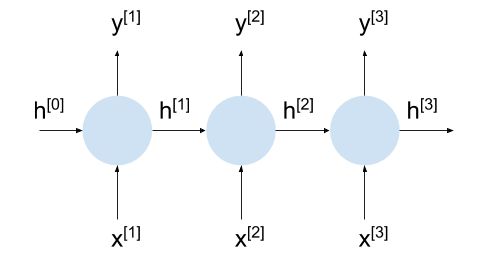
Here, xt: input at time t, st: hidden state at time t, and Ot: output at time t
Unfolding means writing the network for the complete sequence, for example, if a sequence has 4 words then the network will be unfolded into a 4 layered neural network
We can think of s t as the memory of the network as it captures information about what happened in all the previous steps
A traditional neural network uses different parameter at each layer while an RNN shares the same parameter across all the layers, in the diagram we could see that the same parameters (U, V, W) were being used across all the layers
Using the same parameters across all layers shown that we are performing the same task with different inputs, thus reducing the total number of parameters to learn
The tree set of parameter ( U, V, and W) are used to apply linear transformation over their respective inputs
Parameter U transformation the input xt to the state st
Parameter W transforms the previous state st-1 to the current state st
And, parameter V maps the computed internal state st to the output Ot
ht = f(ht-1,xt)
Here, ht is the current state, ht-1 is the previous state and xt is the current input
The equation applying after activation function (tanh) is:
ht=tanh(whhht-1 + wxhxt)
Here, whh : weight at recurrent neuron, Wxh : weight at input neuron
Ot = Why ht
Here, Ot is the output state, why: weight at output layer, ht: current state
Backward phase :
To train an RNN, we need a loss function. We will make use of cross-entropy loss which is often paired with softmax, which can be calculated as:
L = -ln(pc)
Here, pc is the RNN’s predicted probability for the correct class (positive or negative). For example, if a positive text is predicted to be 95% positive by the RNN, then the loss is:
L= -ln(0.95) = 0.051
After calculating loss, we will train the RNN using gradient descent to minimize loss
The common architectures which are used for sequence learning are:
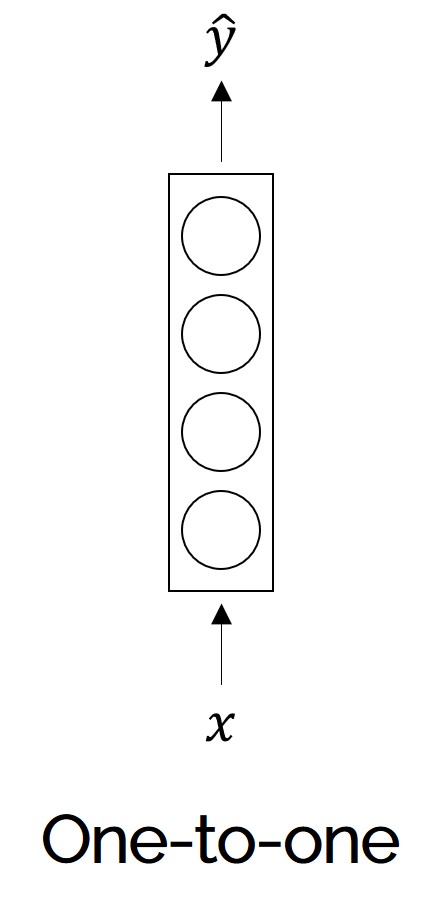
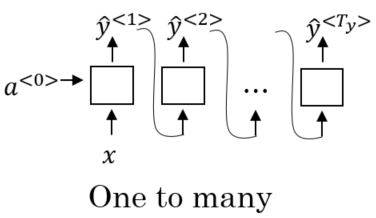
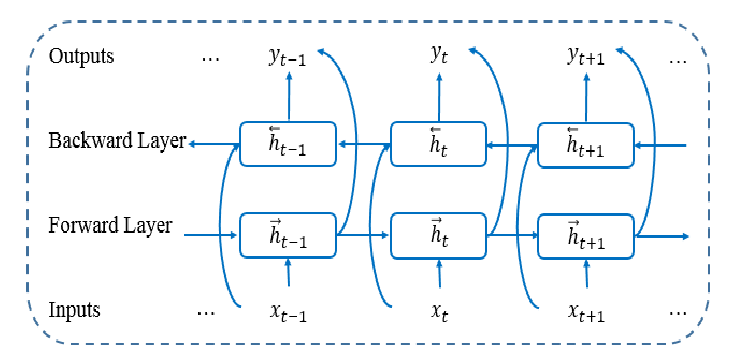
Note:-
Text summarization: Summarizing the text from any literature, for example, if a news website wants to display brief summary of important news from each and every news article on the website, then text summarization will be helpful
Text recommendation: Text autofill or sentence generation in data every work by making use of RNNs can help in automating the processes and make it less time consuming
Image recognition: RNNs can be combined with CNN in order to recognize an image and give its description
Music generation: RNNs can be used to generate new music or tunes, by feeding a single tune as an input we can generate new notes or tunes of music.
References and Links:
Understanding LSTM Networks — colah’s blog
Introduction to Recurrent Neural Network – GeeksforGeeks
Recurrent neural network – Wikipedia
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








simply good to understand