This article was published as a part of the Data Science Blogathon
Natural Language Processing(NLP) is a branch of Artificial Intelligence that deals with Daily Language. Have you ever wonder how Alexa, Siri, Google Assistant understand us with voice and respond to us. Human Language is the fuzziest and complex. As they receive text input first preprocessing of text happens and many techniques are embedded which lets them understand grammar. In this tutorial, we will study some techniques which are helpful to Analyze and visualize text data using a very powerful NLP library as Spacy.

Table of contents
- Introduction to Spacy
- Spacy Setup
- Spacy Basics
- Spacy in Action
- Tokenization
- Phrase Matching
- POS tagging
- Named Entity Recognition
- End Notes
Introduction to Spacy
Spacy is an open-source Natural Language processing library in python. It is used to retrieve information, analyze text, visualize text, and understand Natural Language through different means. Spacy is a way more fast and intelligent library than NLTK which provides some advanced techniques like NER, POS tagging, Dependency parsing, etc. NLTK is a first-level library for NLP which every beginner should know and when we work on real-world projects Spacy is used in a production environment. Spacy also supports Deep learning workflow in Convolutional Neural Network in performing text processing.
Spacy Setup
If you are working on Google Colab then you did not need to install it, but many of us like to work on a local system itself so you need to install the spacy library before use. Visit the spacy official documentation site, and in the install the spacy tab you will need to create a command according to your system configuration and requirement. It will ask you to select an operating system, package manager, language, and some additional details if you want and get the command to install Spacy which you need to run on your command-line interface(CMD).
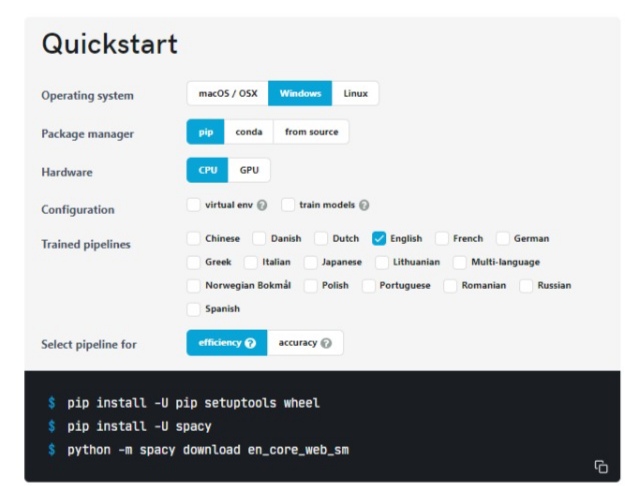
Now you can copy the second command to install spacy or 3rd command to install a specific model of spacy.
Spacy Basics
As you import the spacy module, before working with it we also need to load the model. The model name includes the language we want to use, web interface, and model type.
import spacy
npl = spacy.load('en_core_web_sm')
here, en_core is a language that represents English, web means web interface and sm means small model. now let us define any text document which is in Unicode format. then we will tokenize the text.
doc = npl(u'Microsoft is trying to buy France based startup at $7 Million') for token in doc: print(token.text)
have you observe how intelligent Spacy is, it has tokenized 7 million dollars differently saying this all says different meaning. we can also see part of speech of each token in text using simply one argument, every part of speech is given a unique code in space.
for token in doc: print(token, token.pos_)
Microsoft PROPN is AUX trying VERB to PART buy VERB France PROPN based VERB startup NOUN at ADP $ SYM 7 NUM Million NUM
If we slice some part of the document then it is known as span.
We can also tokenize according to sentences and analyze or verify it using different methods.
Spacy in Action
Now we will make our hands dirty by applying spacy to perform some advanced NLP techniques that the NLTK library does not provide like dependency parsing, named entity recognition, and text visualizations in different ways.
1) Tokenization
Tokenization is a technique in which complete text or document is divided into small chunks to better understand the data. Spacy keeps expertise in tokenizing the text because it better understands the punctuations, links in a text which we have seen in the above example. But the thing is text document is not mutable, which means you cannot replace any text in the document with new text because spacy considers the document to consist of important information.
Tokenization is a basic technique so, we should know this before studying further techniques.
Chunking
If we have complex text then we tokenize it based on chunks. for example, if we have more noun chunks in a document so we can easily extract them.
doc4 = nlp("tesla is a automobile based endorsed with high tech work for implimenting the electric cars")
for chunks in doc4.noun_chunks:
print(chunks)
tesla high tech work the electric cars
These all are the noun chunks in the document.
How to visualize Tokenized data
Spacy provide us extra features to visualize the text data so we can understand the relationship between different words expressed in the document. let us visualize synthetic dependency between tokens in documents.
from spacy import displacy
doc = nlp(u'Tesla to build solar electric startup in gujrat for $70 million')
displacy.render(doc, style='dep', jupyter=True, options = {'distance':100})
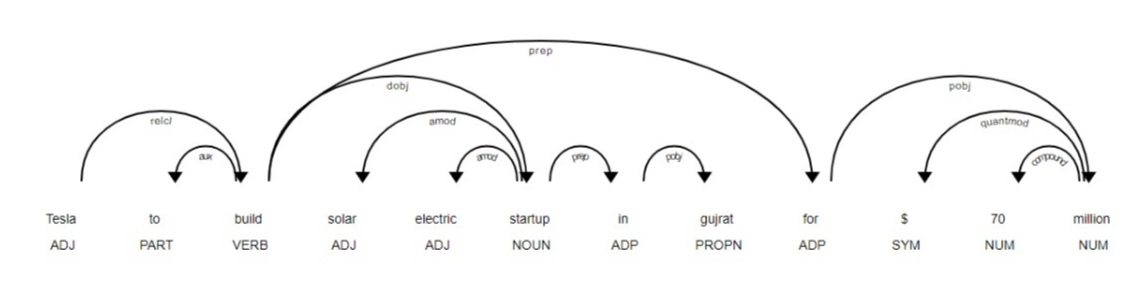
displacy is used as a display function to display a spacy graph. style is defined as dep which means synthetic dependency, we are working in a jupyter notebook and if we want to see the graph in jupyter itself then initialize it as True, and other parameters like the distance between the tokens.
If you want to see the graph on web service rather in jupyter then we can also do this.
2) Phrase Matching
Phase Matching is a similar concept as a regular expression in which you can find the phrase in the document as per your created phrases. If you want to use patterns that you have created then you have to use vocabulary Matching. Phrase Matching is also known as Rule-Based Matching.
from spacy.matcher import Matcher
matcher = Matcher(nlp.vocab)
#solarpower
pattern1 = [{'LOWER':'solarpower'}]
#solar power
pattern2 = [{'LOWER':'solar'},{'LOWER':'power'}]
#solar-power
pattern3 = [{'LOWER':'solar'},{"IS_PUNCT": True},{'LOWER':'power'}]
matcher.add('SolarPower',None,pattern1,pattern2,pattern3)
doc = nlp(u'The Solar Power industry continues to grow as demand for solarpower increases. solar-power operated products are popularity')
found_matches = matcher(doc)
print(found_matches)
we have imported the spacy vocabulary Matcher object and created our own three different patterns which we need to match in our document. when you print the output you will get the id of pattern, start and end position of matched phrase. Now I will show you by printing each pattern with its id which it has matched.
for match_id, start, end in found_matches: string_id = nlp.vocab.strings[match_id] span = doc[start:end] print(match_id, string_id, start, end, span.text)
8656102463236116519 SolarPower 1 3 Solar Power 8656102463236116519 SolarPower 10 11 solarpower 8656102463236116519 SolarPower 13 16 solar-power
How’s it? is it awesome to use Spacy for Analyzing text data?
3) Part of Speech(POS) Tagging
In English Grammar, part of speech tells us what is the function of a word and how it is used in a sentence. some of the common parts of speech are Noun, Pronoun, verb, adjective, adverb, etc.
POS tagging is a method of automatically assigning POS tags to all the words of a document. POS tagging is of 2 types. one is a course in which normal words come like nouns, verbs, and adjectives. Second is a fine-grained text which includes words that provide some special information like plural noun, past or present tense, superlative adjective, etc.
Now let us practice POS tagging practically, we will define the document and assign its part of speech and tags as well we will print a description of each tag it assigns.
doc = nlp(u'The quick brown fox, snatch the piece of cube from mouth of black crow')
for token in doc:
print(f"{token.text:{10}} {token.pos_:{10}} {token.tag_:{10}} {spacy.explain(token.tag_)}")

You can see how smartly Spacy has to assign correct POS tags to each token and we can read its description as well. we can also count how many words of each POS tag occur in our document and it will display each POS code and its count. And from vocabulary, we can check the exact POS.
pos_counts = doc.count_by(spacy.attrs.POS) print(pos_counts) print(doc.vocab[92].text) #check which POS
{90: 1, 96: 2, 92: 6, 100: 3, 94: 1, 98: 1, 85: 1, 84: 2, 97: 2, 87: 1}
NOUN
Visualizing Part of Speech
We have visualized the Graph of synthetic dependency, and a similar Graph you can visualize of POS tag. Now I will show your Graph with some advanced options to make the graph look attractive and easy to understand.
options = {'distance':110,'compact':'True','color':'#F20835','bg':'#ADD8E6','font':'arial'}
displacy.render(doc, style='dep', jupyter=True, options=options)
here, we have defined some additional Graph styling and the Graph will look something like this.

4) Named Entity Recognition(NER)
Entities are the words or groups which represent some special information about common things such as country, state, organization, person, etc. Spacy is a well-known library to perform entity recognition. It can identify entities and explain them saying what it means. so let’s try this out.
doc3 = nlp(u"Ambani good to go at Gujrat to start a agro based industry in jio Mart for $70 million")
for entity in doc3.ents:
print(entity)
print(entity.label_)
print(str(spacy.explain(entity.label_)))
print("n")

you can observe how smartly it identifies the entities and define them with proper explanation and this is only what we refer to as Named entity recognition.
Visualizing NER
Now we will visualize output for the Named entity and understand what information it reflects.
doc = nlp(u” over the last quarter Amazon has raised its profit from 20 thousand diilivery for a profit of $7 Million.”
u”By contract JBL only sold out 10 thousand Walkman Product Bluetooth speakers.”)

we can observe, Spacy has highlighted entities with different color and shown what exactly each entity represent whether it is Date, organization or Money information.
End Notes
This was a Quick go-through text Analysis technique with Spacy to give you a taste of what Spacy can do. Spacy makes it to easy to analyze the text in different ways and prepare the text data and build a generalized model on top of text data. After going through this article I am sure that you are going to use the Spacy library for performing lots of NLP tasks. I encourage you to play around with the code and try different text, documents, and styling.
If you are new to NLP and want to know more about Text processing techniques then I would request you to check my previous article about all the techniques for text preprocessing.
About the Author
Raghav Agrawal
I am pursuing my bachelor’s in computer science. I am very fond of Data science and big data. I love to work with data and learn new technologies. Please feel free to connect with me on Linkedin.
The media shown in this article on Deploying Machine Learning Models leveraging CherryPy and Docker are not owned by Analytics Vidhya and are used at the Author’s discretion.
Raghav Agrawal
23 Jun, 2021
I am a final year undergraduate who loves to learn and write about technology. I am a passionate learner, and a data science enthusiast. I am learning and working in data science field from past 2 years, and aspire to grow as Big data architect.







