This article was published as a part of the Data Science Blogathon
Introduction
Biographies of many famous personalities are very insightful and inspiring. Although, one may not want to read the whole document. In order to just get the important points from the biography, one can generate a summary of the biography. The summary is generated by giving weights to all the words. Sometimes, anaphoras can be predicted by the machine as a separate word which in return produces a less accurate result. For example, Jai is playing tennis. He plays very well. Here, Jai is taken as one word and he as another in the machine by semantic analysis when both he and Jai are referring to the same person.
Another scenario could be that one is reading a biography and they leave it in between. When they revisit the document, they do not remember who he refers to. Thus, they have no choice but to read the above lines again to understand the references. Anaphora resolution saves time for individuals and is also used in pre-processing these biographies.

source: https://meta-guide.com/wp-content/uploads/2020/06/storygenerator19.jpg
Concept
The reason for limiting the document input to biographies is that biographies focus on named entities, i.e real-world objects. Biographies consist of the name of the person whose biography it is, where he/she was born or where he/she moved to and where did he/she study or work. These refer to named entities name, location, and organization respectively.
If we talk about essays or text documents in general, there may or may not exist named entities in them. For example, there could be a story about a boy where the boy’s name is never disclosed. Anaphora resolution, in this case, requires the building of a corpus to identify the type of noun and then referring the pronoun attached to it. Using named entity recognition requires no pre-built corpus as whenever a named entity is identified, it is stored in the local storage and along with its subcategory, and when the pronoun of that category is read, it is automatically assigned to the named entity recognized.
For example, ‘Jai is playing tennis. He plays very well. Here Jai is identified as a named entity, it is stored in local storage as ‘Jai, Person’ where the person is the type of entity. When the next line is read, he is identified as a pronoun that is assigned to a person. After checking the local storage, he will be assigned to Jai.

source: https://www.adl.org/sites/default/files/styles/open_graph_image_1200_x_628_/public/2021-01/pronouns-in-english-language-istock-modified.jpg?itok=_3GxxCPw
There are many types of named entities but the ones used in biographies are person names, organization names, and location names. All these three can be identified using Stanford NER which can be downloaded from the link given below:
Code
The python code for anaphora resolution and co-reference resolution of biographies is mentioned below. It can be used directly after changing the path of the Stanford NER file downloaded if required.
Description
The code above creates two lists for each entity (name, organization, location). The lists refer to the named entities mentioned in the previous and current sentences respectively. These lists are maintained because sometimes the anaphora refers to the named entity mentioned in the previous line. For example, Jai is playing and he loved to play. Here, he refers to Jai which is mentioned in the current sentence. But the same sentence can be written as: Jai is playing. He loved to play. Here also, he refers to Jai but Jai is mentioned in the previous sentence.
Two other lists are maintained for a co-reference list and co-reference solutions. Co-reference resolution can be explained with the help of an example. Mary Lee is referred to as Mary sometimes and Lee sometimes. Identifying that Mary and Lee refer to the same person is co-reference resolution. Thus, if the sentence is: Lee loves to read. She is a bookworm. Here, if we run this sentence through Stanford NER tagger, it will store Lee as a person and when the machine reads the pronoun she, it resolves it to Lee.
If the co-reference resolution is included in the code, the machine will resolve she to Mary Lee, which is much better for understanding. Thus the lists stored for this purpose as per our code are [‘Mary’, ‘Lee’] and [‘Mary Lee’, ‘Mary Lee’] which implies that Mary is resolved to Mary Lee and Lee is also resolved to Mary Lee so that the machine is able to interpret that we are talking about the same person.
A hardcoded list for many possible pronouns is created in the code. If an element of the list occurs in the sentence, it is resolved. A special case used in the code is the word ‘There’. There is only resolved if it has a comma after in the sentence. This is to avoid errors as there can have two meanings:
1. There is no doubt that he is a great man.
2. He moved to Delhi. There, he learned music.
The ‘there’ in the second case needs to be resolved it refers to a location. The text string taken from the biography is also hardcoded. It can be changed according to requirements.
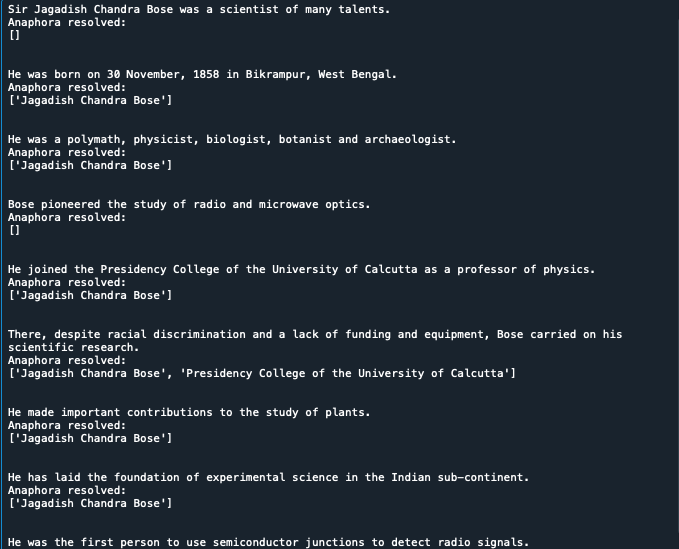
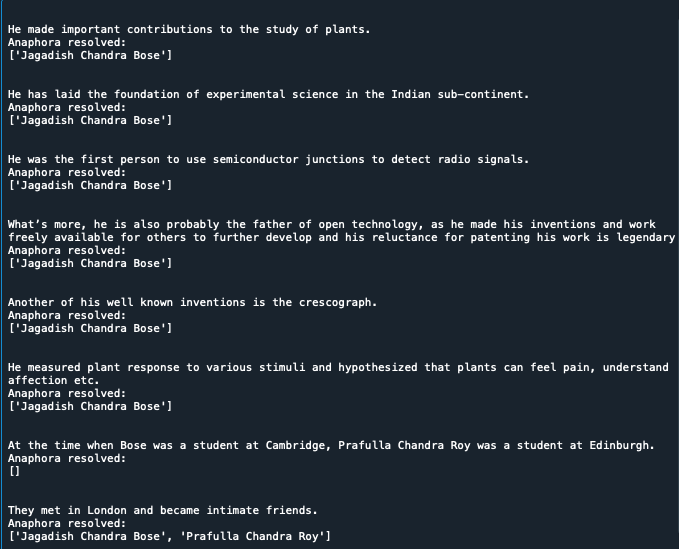
Output
The code output is shared below in the form of screenshots. It can be seen that ‘he’, ‘his’ has been resolved to Jagadish Chandra Bose in all sentences. In many places, the name Jagadish Chandra Bose was referred to as Bose in the text string, it has been resolved to its full name while generating the desired output. ‘There has been resolved to an organization. ‘They’ has been resolved to Jagadish Chandra Bose and his friend. An empty list is returned where nothing had to be resolved.
Conclusion
The algorithm used in the code above gives better accuracy with respect to many algorithms used for anaphora resolution. For example, Jai is eating. Mary Joins him. They enjoy dinner. Here, using the Lapin and Lease algorithm, They will be resolved as null when it refers to Jai and Mary. This algorithm has been designed in a way such that it is best suited for biographies as mostly named entities are used and facts are provided.
Author name: Pearl Miglani
Contact info: [email protected]
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.







