Cleaning and Pre-processing textual data with NeatText library
Introduction
Unstructured text data can be a problem while solving NLP problems. There is a need to pre-process any unstructured text data in order for us to build an effective NLP model. Hence pre-processing textual data is an important step while building any NLP model. Converting text into numbers is important as the machine learning models take only numbers as inputs. Therefore converting string objects(text) into ‘int’ objects is necessary. There are many ways to pre-process text. One way is to hard code every step and processes the text data through that code. Another way is to use any Natural Language Processing package that does the work for us using simple commands. One such package is NeatText.
Table of Contents
- What is NeatText
- Components of NeatText
- Installation
- Using TextFrame
- Using TextExtractor
- Using Functions
- Using Explainer
- Conclusion
What is NeatText
NeatText is a simple Natural Language Processing package for cleaning text data and pre-processing text data. It can be used to clean sentences, extract emails, phone numbers, weblinks, and emojis from sentences. It can also be used to set up text pre-processing pipelines.
This library is intended to solve the following problems :
- Cleaning unstructured text data.
- Reducing noise in text.
- Avoid repetition of the same code for pre-processing.
In this article, we shall explore the different components and functionalities of this package using examples. First, let us see the different components in this package.
Components of NeatText
This library offers four components also called objects. They are:
- TextFrame: It’s a frame-like object for cleaning and analyzing text.
- TextExtractor: It’s also a frame-like object that is used to extract different entities in a given sentence.
- Functions: These facilitate us to do different tasks at the same time saving lines of code.
- Explainer: This object is used to deal with emojis in sentences.

We shall go through each object in the rest of the article from installing the library to pre-processing text data.
Installation of NeatText
pip install neattext
Now that we have installed the NeatText library let’s import and use it.
import neattext as nt
We shall see the functionality of different objects of this library in a sentence.
Let’s create a sentence.
my_text = 'His name is Donald trump 😆. He is former president of USA !!!! 😎 . He abused women. His contact number is 0123456789. His email is [email protected]. His website is https://www.donaldjtrump.com/'
The above sentence contains so much noise like emojis, emails, weblinks, and some special characters. So we will clean that sentence.
Using TextFrame in NeatText
Generally, sentences scrapped from the internet contain a lot of noise like punctuations, emojis, and other special characters. These can be a problem if not removed from the sentence. TextFrame object enables us to remove all this noise and help us get a cleaned sentence.
This object keeps the text as a TextFrame object which will allow us to do more with text. To use the TextFrame object we have to create an instance of TextFrame on the given sentence. Let’s create an instance called sentx.
sentx = nt.TextFrame(text=my_text)
Let’s print the text from the instance.
sentx.text

Now we have an instance sentx, let’s use describe() command.
sentx.describe()
output:
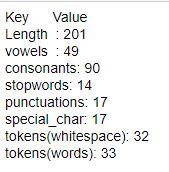
We can see that this command outputs a detailed description of sentences like the length of sentence, number of stopwords present in the sentence, etc.,
To count the number of vowels in the sentence –
sentx.count_vowels()
Output:
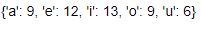
To count the number of stopwords in the sentence –
sentx.count_stopwords()
Output:
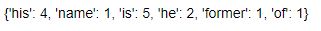
Now that we have seen some basic text metrics that this library has to offer, let’s see some text cleaning methods.
To remove punctuations in the sentence –
print(sentx.remove_puncts())
Output:

we can see that all punctuations like exclamatory marks and full stops are removed from the sentence.
To remove stopwords in the sentence –
print(sentx.remove_stopwords())
Output:
We can see that the sentence is free of punctuations and stopwords.
Next, we remove emojis. To do that use this simple command –
print(sentx.remove_emojis())
Output:
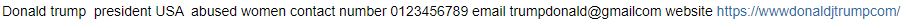
In the same way, we can remove emails and numbers
Using TextExtractor in NeatText
So far we have seen some simple commands to remove punctuations, stopwords, and emojis in a given sentence using the TextFrame object.
Sometimes sentences contain valuable data like emails, phone numbers, emojis. For example in a given tweet emoji can give us valuable information like the sentiment of the tweet. So Let us use TextExtractor to extract some valuable information from the sentence.
First, we shall extract the email from the sentence. To do that we have to import TextExtractor and create an instance of it.
from neattext import TextExtractor sentx1 = TextExtractor(text=my_text)
Now that we have created an instance of it let’s use it to extract email –
sentx1.extract_emails()
Output:
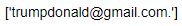
We have extracted the email in the sentence with just one single command. Now let’s extract the emojis from the sentence –
sentx1.extract_emojis()
Output:

Using Functions in Neattext
Functions offer a unique way to pre-process the sentence. We can do all activities that we did above in one line using functions that will save some lines of code.
Now let’s use functions to process the sentence. To do that we have to import necessary modules –
from neattext.functions import clean_text
Now we will use this to remove URLs, stopwords from the original sentence my_text as follows –
clean_text(my_text, urls=True, stopwords=True)
Output:
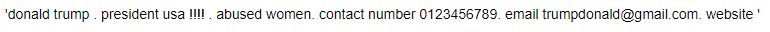
We can see that the given sentence doesn’t contain any URL or stopwords.
Using Explainer
So far we have seen TextFrame, TextExtractor, and Functions. Now let us see another object of the NeatText library i.e., Explainer.
Sometimes we might get confused regarding what an emoji could mean and also sometimes we want to create an emoji based on a given expression and in some applications we might want to use Unicode instead of emojis. So there is a need to convert these Unicodes into emojis in the output. Explainer object does all these for us.
The explainer can do three kinds of activities. They are
- emojify() – It creates an emoji based on a given emotional expression.
- emoji_explainer() – It explains the meaning behind the given emoji.
- unicode_2_emoji() – It converts Unicode to emoji.
Let’s see how each one works. Firstly we will import these functions from the explainer in the following way –
from neattext.explainer import emojify, emoji_explainer, unicode_2_emoji
Now that we have imported them let’s use them. First, we will see emojify()
emojify('cry')
Output:

We can see that it has produced an emoji based on the emotion we gave to it.
Now let’s see emoji_explainer() –
emoji_explainer('😍')
Output:
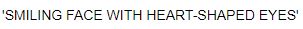
The output shows the description of the given emoji.
Let’s see unicode_2_emoji()
unicode_2_emoji('0x1f49b')
Output:

Conclusion
We have seen all the components of the NeatText library. We have removed several unwanted things from the sentence and made it ready for further processing. We also saved a lot of time writing functions for pre-processing. This library comes in handy to do any kind of pre-processing on text data.
Image Source-
Image 1: https://jcharis.github.io/neattext/







