This article was published as a part of the Data Science Blogathon
Bow to the might of NLP. There is no denying the power and evolution we have witnessed in the field of Natural Language Processing and what further advancements we will have the fortune to witness, learn, and implement. NLP is used in a wide area and has is almost omnipresent in today’s world. In my journey of familiarizing myself with NLP and the pertaining techniques, I’ve learned tremendously from the community along with being able to address certain requirements and challenges. And since the content of this article is about the same and even though it will mostly be descriptive, hopefully, some content will be helpful in learning NLP.

The data being used here is a subset of Company Reviews scraped from Indeed. The intention or objective is to analyze the text data (specifically the reviews) to find:
- – Frequency of reviews
- – Descriptive and action indicating terms/words – Tags
- – Sentiment score
- – Create a list of unique terms/words from all the review text
- – Frequently occurring terms/words for a certain subset of the data
- – The n-grams and to create a DataFrame of the n-grams
Later we will check the spell-checking functionality and one of the ways I have used it is by assigning it to a separate spell-checked column.
Libraries and Reading the file
Here we load the libraries for our analysis and we will be using TextBlob library to check the spelling, create Sentiment_Score , and while creating separate columns for specific POS Tags.
import pandas as pd
import numpy as np
import re
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize, word_tokenize
nltk.download('stopwords')
nltk.download('punkt')
nltk.download('wordnet')
nltk.download('averaged_perceptron_tagger')
import textblob from textblob import TextBlob from sklearn.feature_extraction.text import CountVectorizer
from functools import reduce import operator import collections from collections import Counter
import datetime as dt
import seaborn as sns import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
df = pd.read_excel("Reviews_from_Indeed.xlsx", index_col=0)
df.head()
Function for cleaning the text content
Since, almost every time we do not get the data we want to analyze in the format we want, the data requires wrangling, cleaning, or if I may choose one word over others – pre-processing. So, will pre-process our review content by removing punctuations, unwanted characters, converting to lowercase, tokenizing, and lemmatizing. Text cleaning is an important part of nlp.
def preprocessing(text):
# removing punctuations, unwanted characters and converting to lowercase
text = re.sub("[^-9A-Za-z ]", "", text).lower()
# removing stopwords and tokenizing
stop = stopwords.words("english")
tokens = [word for word in (token for token in word_tokenize(text)) if word not in stop]
# lemmatizing
lmtzr = nltk.WordNetLemmatizer()
preprocessed_text = ' '.join([lmtzr.lemmatize(word) for word in tokens])
return preprocessed_text
– Applying the ‘preprocessing’ function to our ‘Review’ column:
df['Review'] = df['Review'].astype(str) df['PP_Review'] = df['Review'].apply(preprocessing)
Frequency of Reviews
To start our analysis we will check the frequency distribution of reviews by “month”, first for the entire data and then for 2020 and 2021. For this we will extract the “month”, and “year” portions from our ‘Date’ column.
df['Date'] = pd.to_datetime(df['Date'])
df['Month'] = df['Date'].dt.month df['Year'] = df['Date'].dt.year
We group the review data by month, which we will then use in our plots:
revbymonth = df.groupby('Month').agg(Count=('Review','count')).sort_values('Month', ascending=True)
sns.catplot(data=revbymonth.reset_index(), kind='bar', x='Month', y='Count',
alpha=0.9, height=3, aspect=4)
ax=plt.gca()
for p in ax.patches:
ax.text(p.get_x() + p.get_width()/5., p.get_height(), '%d' % int(p.get_height()),
fontsize=12, color ='blue', ha='center', va='bottom')
plt.title('Frequency of Reviews by Month', fontsize=15, color='Black')
plt.tick_params(axis='x', rotation=-15, labelsize=10)
plt.show()
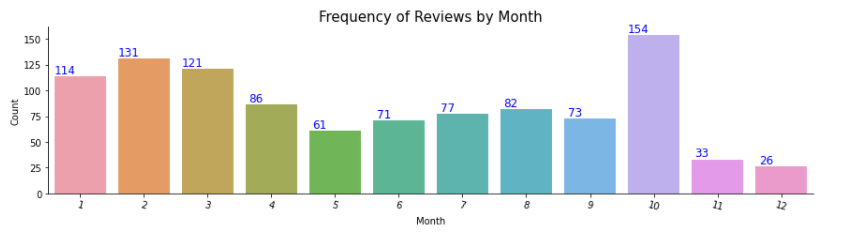
We can see relatively lesser review frequencies towards the year-end which could be due to factors like holidays and annual enrollments.
Similarly below we group the review data by month, for 2020 and 2021 to facilitate their respective plots:
revbymonth_2020 = df[df['Year']==2020].groupby('Month').agg(Count = ('Review','count')).sort_values('Month', ascending=True)
revbymonth_2021 = df[df['Year']==2021].groupby('Month').agg(Count = ('Review','count')).sort_values('Month', ascending=True)
sns.catplot(data=revbymonth_2020.reset_index(), kind='bar', x='Month', y='Count',
alpha=0.9, height=3, aspect=4)
ax=plt.gca()
for p in ax.patches:
ax.text(p.get_x() + p.get_width()/5., p.get_height(), '%d' % int(p.get_height()),
fontsize=12, color ='blue', ha='center', va='bottom')
plt.title('Frequency of Reviews by Month for 2020', fontsize=15, color='Black')
plt.tick_params(axis='x', rotation=-15, labelsize=10)
plt.show()
sns.catplot(data=revbymonth_2021.reset_index(), kind='bar', x='Month', y='Count',
alpha=0.9, height=3, aspect=4)
ax=plt.gca()
for p in ax.patches:
ax.text(p.get_x() + p.get_width()/5., p.get_height(), '%d' % int(p.get_height()),
fontsize=12, color ='blue', ha='center', va='bottom')
plt.title('Frequency of Reviews by Month for 2021', fontsize=15, color='Black')
plt.tick_params(axis='x', rotation=-15, labelsize=10)
plt.show()
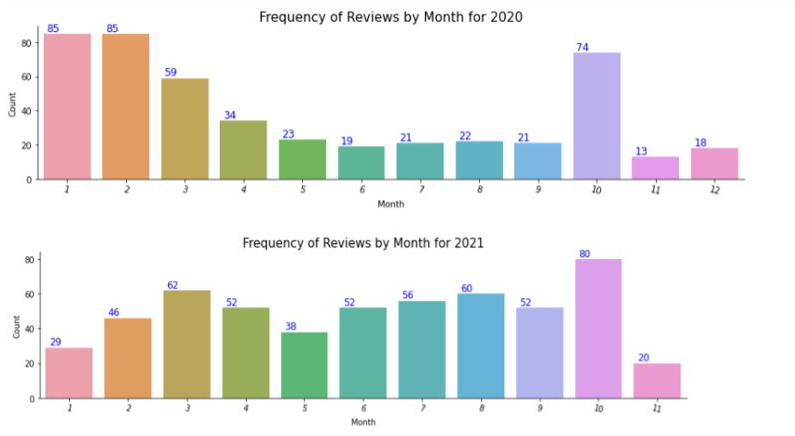
Next, we look into the review frequency by top 10 locations for 2020 and 2021:
revbyloc_2020 = df[df['Year']==2020].groupby('Location').agg(Count = ('Review','count')).sort_values('Count', ascending=False).nlargest(10, 'Count')
revbyloc_2021 = df[df['Year']==2021].groupby('Location').agg(Count = ('Review','count')).sort_values('Count', ascending=False).nlargest(10, 'Count')
sns.catplot(data=revbyloc_2020.reset_index(), kind='bar', x='Location', y='Count',
alpha=0.9, height=3, aspect=5)
ax=plt.gca()
for p in ax.patches:
ax.text(p.get_x() + p.get_width()/5., p.get_height(), '%d' % int(p.get_height()),
fontsize=12, color ='blue', ha='center', va='bottom')
plt.title('Frequency of Reviews by Location for 2020', fontsize=15, color='Black')
plt.tick_params(axis='y', rotation=0, labelsize=10)
plt.show()
sns.catplot(data=revbyloc_2021.reset_index(), kind='bar', x='Location', y='Count',
alpha=0.9, height=3, aspect=5)
ax=plt.gca()
for p in ax.patches:
ax.text(p.get_x() + p.get_width()/5., p.get_height(), '%d' % int(p.get_height()),
fontsize=12, color ='blue', ha='center', va='bottom')
plt.title('Frequency of Reviews by Location for 2021', fontsize=15, color='Black')
plt.tick_params(axis='y', rotation=0, labelsize=10)
plt.show()
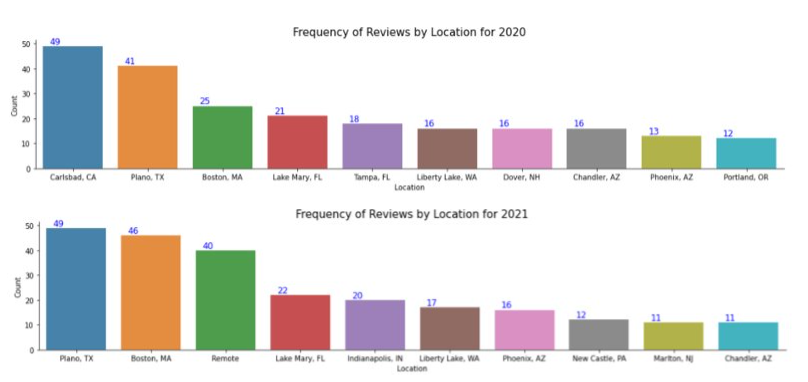
We can see Plano, TX and Boston, MA leading and the entry of “Remote” in 2021 due to obvious reasons.
Descriptive and action indicating terms/words – Tags
Continuing with our objective, we focus on terms/words or tags and further drill down to descriptive (adjectives) and action-indicating (verbs, adverbs) words. Then we could draw insights for specific subsets of data based on the respective terms listed for them.
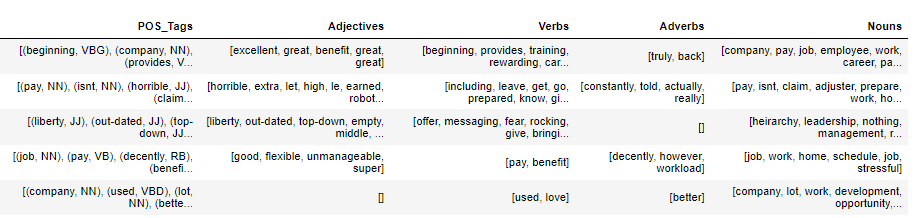
As stated earlier using TextBlob and the below set of functions we create corresponding columns for adjectives, verbs, adverbs, and nouns (this can be used if we have a specific name of interest).
df['t_PP_Review'] = df.apply(lambda row: nltk.word_tokenize(row['PP_Review']), axis=1) df['POS_Tags'] = df.apply(lambda row: nltk.pos_tag(row['t_PP_Review']), axis=1)
# functions for separating the POS Tags
def adjectives(text):
blob = TextBlob(text)
return [word for (word,tag) in blob.tags if tag == 'JJ']
def verbs(text):
blob = TextBlob(text)
return [word for (word,tag) in blob.tags if tag.startswith('VB')]
def adverbs(text):
blob = TextBlob(text)
return [word for (word,tag) in blob.tags if tag.startswith('RB')]
def nouns(text):
blob = TextBlob(text)
return [word for (word,tag) in blob.tags if tag.startswith('NN')]
df['Adjectives'] = df['PP_Review'].apply(adjectives) df['Verbs'] = df['PP_Review'].apply(verbs) df['Adverbs'] = df['PP_Review'].apply(adverbs) df['Nouns'] = df['PP_Review'].apply(nouns)
df[['POS_Tags', 'Adjectives', 'Verbs', 'Adverbs', 'Nouns']].head()
Now, let’s see some adjectives occurring for Location like ‘Remote’ since most of the operations went into that mode post-pandemic situation.
adj_remote=df[['Adjectives']][(df['Location'].str.contains("Remote"))&(df.astype(str)['Adjectives']!='[]')]
We can then use the below function to generate a list of adjectives. Please note we will be using the termfreq() function later as well when we get into creating term-frequency.
# function to convert token to list and unpack def termfreq(x): dlist = x.tolist() return (reduce(operator.add, dlist))
termfreq(adj_remote['Adjectives'])

Sentiment Score and creating a column of Unique_Terms/Words
Moving on, we create a Sentiment_Score column using TextBlob. Since the Sentiment_Score range is from –1 to +1, we can always include a multiplier to the Sentiment Score column for visual purposes, as applicable. In addition, we also created a column containing unique terms from the entire dataset. This information can then in turn be used to tag a unique set of words to categories of your interest or based on business requirements. The advantage is that each word will be tagged to only a specific category. If a certain word needs to be assigned to another category than what it is originally assigned to, the uniqueness is maintained and can help create dashboards where you want the tagging information to be unique. Hence NLP is very useful.
df['Sentiment_Score'] = df['PP_Review'].apply(lambda x: TextBlob(x).sentiment[0]) df['Unique Terms'] = df['PP_Review'].str.split().explode().drop_duplicates().groupby(level=0).apply(list)
df[['Review', 'Rating','Month', 'Year', 'Sentiment_Score', 'Unique Terms']].head()
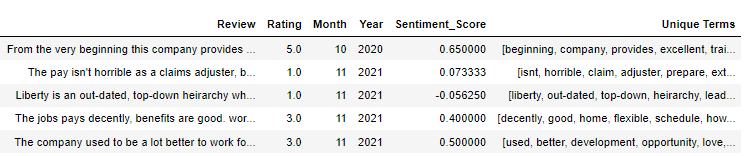
Now, checking the correlation between Rating and Sentiment_Score is one thing we can do, and taking, 0.8 to be the threshold both ways and based on the value we get, we can further look into the Review vs Rating aspect of the data.
df['Rating'].corr(df['Sentiment_Score'])
Function for term/word frequency
Next, we establish a function to give us term/word frequency based on certain conditions for a specific subset of data. This function will also save the files by their respective names that are controlled by the ‘y’ value in the ‘counting(x, y)’ function below:
# function to convert token to list and unpack
def termfreq(x):
dlist = x.tolist()
return (reduce(operator.add, dlist))
# function to count the term/word and create a dataframe for frequencies
def counting(x, y):
from collections import Counter
Counter = Counter(x)
most_occurrences = Counter.most_common()
count_df = pd.DataFrame(most_occurrences, columns = ['Word', 'Count'])
print(count_df.shape)
display(count_df.head(15))
count_df.to_excel(f'Frequency{y}.xlsx')
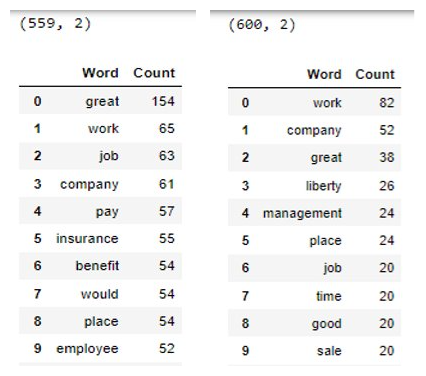
We can, not only, build WordClouds , but it also gives a quick and effective snapshot of important terms/words about the data in question. For instance, below is the illustration for October of 2020 and 2021 taking note that it is applied to the tokenized column (t_PP_Review in Step-5), where we see some common positive terms like “great”, “place”, and “work”; and then different terms like “insurance” and “benefit” in 2020 along with “management” and “sale” in 2021. Please note, below is just a snapshot (of output reference to the code), and based on the output we can further clean the data. NLP is a great tool for text processing.
freq_2020_10 = df[(df['Year']==2020)&(df['Month']==10)] counting(termfreq(freq_2020_10['t_PP_Review']), 1)
freq_2021_10 = df[(df['Year']==2021)&(df['Month']==10)] counting(termfreq(freq_2021_10['t_PP_Review']), 2)
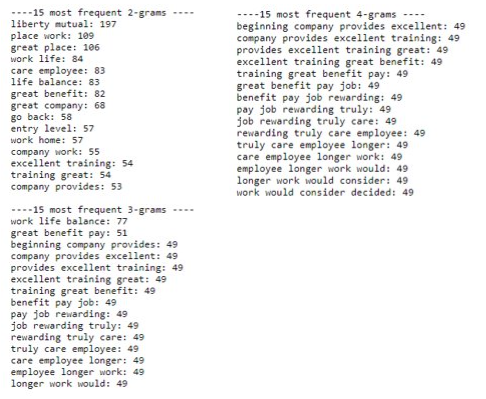
n-grams
Lastly, our analysis rounds up with the addition of n-grams analysis, where we create bi-, tri-, and quad-grams.
Refence for n-grams function:
def listandtokenize(data):
yourlist = data.tolist()
string = ' '.join(map(str, yourlist))
return re.findall(r'w+', string.lower())
# function to prepare n-grams
def count_ngrams(lines, min_length=2, max_length=4):
lengths = range(min_length, max_length+1)
ngrams = {length: collections.Counter() for length in lengths}
queue = collections.deque(maxlen = max_length)
def add_queue():
current = tuple(queue)
for length in lengths:
if len(current)>= length:
ngrams[length][current[:length]] +=1
for line in lines:
for word in nltk.word_tokenize(line):
queue.append(word)
if len(queue) >= max_length:
add_queue()
while len(queue) > min_length:
queue.popleft()
add_queue()
return ngrams
We can use the below function if we only want to print the n-grams and as illustrated:
# function to print 15 most frequent n-grams
# change the print number as applicable
def print_most_freq_ng(ngrams, num=15):
for n in sorted(ngrams):
print('----{} most frequent {}-grams ----'.format(num, n))
for gram, count in ngrams[n].most_common(num):
print('{0}: {1}'.format(' '.join(gram), count))
print('')
print_most_freq_ng(count_ngrams(listandtokenize(df['PP_Review'])))
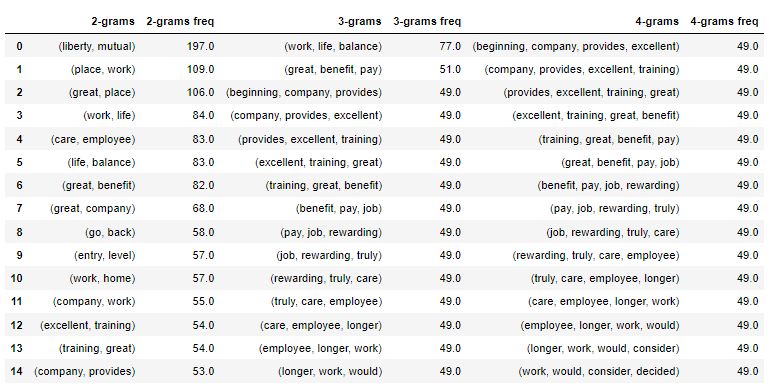
I also wanted the n-grams output to be fed into a DataFrame for dashboard purpose and for that added the components within the “print_most_freq_ng” function to save the n-grams data into a DataFrame. First, let’s define respective DataFrames:
bigramtodf = pd.DataFrame({'2-grams': [], '2-grams freq': []})
trigramtodf = pd.DataFrame({'3-grams': [], '3-grams freq': []})
quadgramtodf = pd.DataFrame({'4-grams': [], '4-grams freq': []})
Then we modify the function as follows and apply it:
def print_most_freq_ng(ngrams, num=15):
global bigramtodf, trigramtodf, quadgramtodf
for n in sorted(ngrams):
print('----{} most frequent {}-grams ----'.format(num, n))
for gram, count in ngrams[n].most_common(num):
print('{0}: {1}'.format(' '.join(gram), count))
if n == 2:
bigramtodf = bigramtodf.append({'2-grams': gram, '2-grams freq': count}, ignore_index=True)
elif n == 3:
trigramtodf = trigramtodf.append({'3-grams': gram, '3-grams freq': count}, ignore_index=True)
else:
quadgramtodf = quadgramtodf.append({'4-grams': gram, '4-grams freq': count}, ignore_index=True)
print('')
print_most_freq_ng(count_ngrams(listandtokenize(df['PP_Review'])))
ngramdf = pd.concat([bigramtodf, trigramtodf, quadgramtodf], axis=1) ngramdf
Spell-checked column
As stated earlier here is a brief share of creating a separate column for spell-checked review using the below code and why:
df['PP_Review'] = df['PP_Review'].astype(str) df['SC_PP_Review'] = df['PP_Review'].apply(lambda x: str(TextBlob(x).correct()))

One of the purposes (not a major one) for having a separate column with spell-check is for comparison and to capture certain terms/words that we want and spelling errors could render them to be missed and can be seen concerning entries like above. For the ‘Review’ we have a word ‘wver’ (which most probably is an error) and after spell-check becomes ‘over’ (though most certain it could be ‘ever’). Let’s say we were looking for the word ‘over’ and the reviewer did mean to write ‘over’ instead of ‘wver’, then spell-check helps us to capture such words.
EndNote
There will be instances of the same word appearing across n-grams especially on the higher-grams (if I may call it so) which we can remove using ‘set’ and ‘len’. Something for the next content.
Carpe diem! Thank you very much!







