AWS Redshift: Cloud Data Warehouse Service
This article was published as a part of the Data Science Blogathon.
Introduction
Amazon’s Redshift Database is a cloud-based large data warehousing solution. Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system.
The datasets range in size from a few 100 megabytes to a petabyte. The first step in building a data warehouse is to launch a collection of computational resources known as nodes, which are arranged into clusters. We can then proceed to process our requests.
How does Redshift work?
Amazon Redshift analyses structured and semi-structured data across data warehouses, operational databases, and data lakes with SQL leveraging AWS-designed technology and machine learning to provide the best pricing performance at any scale.
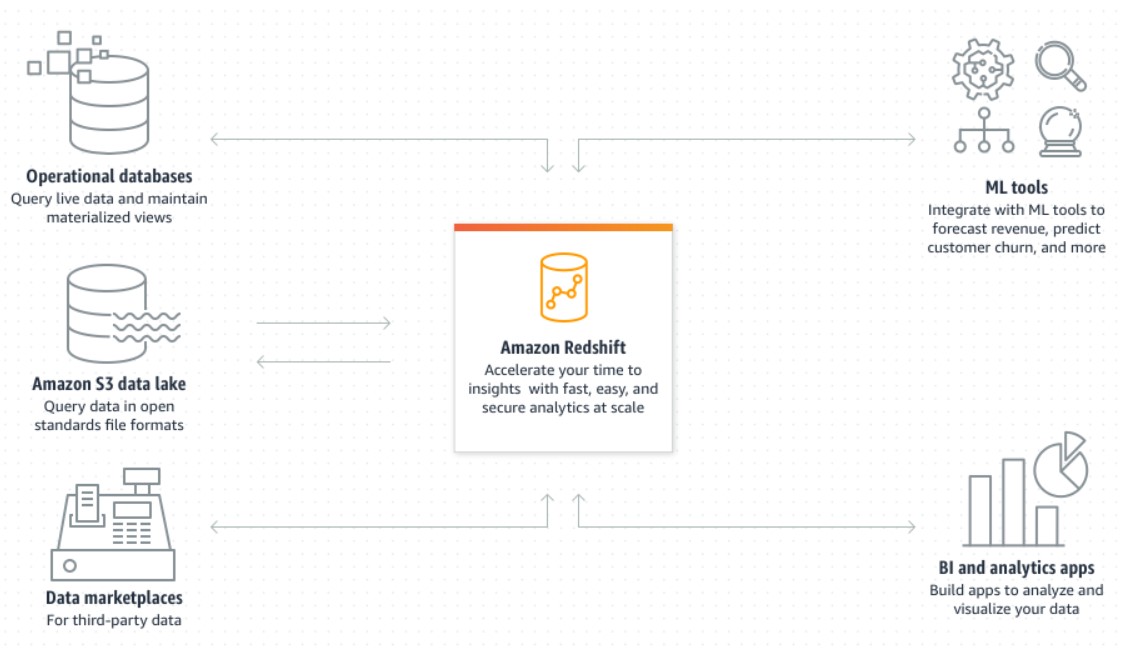
Source: https://aws.amazon.com/redshift/
Administrative operations such as configuration, maintenance backups, and security are totally automated in every Redshift data warehouse. Because of its modular node design, Redshift is intended for massive data and can scale quickly. Redshift’s multi-layered structure allows numerous requests to be performed simultaneously, minimising wait times.
Furthermore, Redshift clusters may be further separated into slices, allowing for more detailed insights into data sets. Redshift databases also entirely use Amazon’s cloud server architecture, including access to Amazon S3 for data backup.
We can use Amazon Redshift to access data with a variety of conventional, cloud-native, and containerized serverless web services and event-driven applications. The Amazon Redshift Data API makes data access, intake, and egress easier from AWS SDK-supported programming languages and platforms like Python, Go, Java, Node.js, PHP, Ruby, and C++. The Data API eliminates the requirement for drivers to be configured and database connections to be managed. Instead, we can use the Data API to access a secured API endpoint to perform SQL queries on an Amazon Redshift cluster.
Features and Characteristics of Redshift
- VPC support allows users to run Redshift within a VPC and control cluster access using the virtual networking environment.
- Encryption Redshift data may be encrypted and customised when tables are being created.
- SSL encryption is used to encrypt client-to-Redshift communications.
- The number of nodes in the Redshift data warehouse may be quickly scaled as needed with a few easy clicks. It also enables the expansion of storage capacity without sacrificing performance.
- Amazon Redshift is a less expensive alternative to standard data warehousing techniques. There are no upfront expenses, no long-term obligations, and a pricing system that is based on demand.
Why is Redshift unique?
Redshift is a column-oriented OLAP (Online Analytical Processing) database. It is built using the PostgreSQL 8.0.2 database. This implies that Redshift can be used with standard SQL queries. However, this is not what distinguishes it from other services. Redshift distinguishes itself by responding quickly to queries conducted on a big database containing exabytes of data.
Redshift, like any other clustered or distributed database model, operates in a clustered paradigm with a leader node and numerous working nodes. Because it is based on Postgres, it has many similarities with Postgres, notably the query language, which is nearly identical to Structured Query Language (SQL). This Redshift version allows you to create practically all important database objects, including databases, tables, views, and even stored procedures. In this post, we will look at how to set up and run your first Redshift cluster on AWS.
The Massively Parallel Processing architecture, or MPP, enables fast querying. ParAccel invented the technology. MPP uses a high number of computer processors working in parallel to do the necessary computations. Processes can sometimes be delivered by processors distributed across different servers.
Amazon Redshift analyses user workloads and use advanced algorithms to modify the physical structure of data in order to increase query performance. Automatic Table Optimization chooses the optimum sort and distribution keys to improve performance for the workload on the cluster. If Amazon Redshift believes that using a key will enhance cluster performance, tables will be changed automatically without the need for administrator interaction. The added capabilities Automatic Vacuum Delete, Automatic Table Sort, and Automatic Analyze minimise the need for human Redshift cluster maintenance and tuning to get the optimal performance for new clusters and production workloads.
Amazon offers data encryption for any aspect of the Redshift process. You, as the user, may choose which actions require encryption and which do not. Data encryption adds an extra degree of protection.
PostgreSQL is the foundation of Redshift. It is compatible with all SQL queries. We may also use any SQL, ETL (Extract, Transform, Load), and Business Intelligence (BI) tools that we are acquainted with. It is not necessary to use the tools offered by Amazon.
There would be several ways to query data with the same parameters for a huge data collection. The data usage levels of the various instructions will vary. AWS Redshift gives you the tools and data you need to optimise your searches. It will also automatically make suggestions for improving the database. These can be used for a more efficient procedure that uses fewer resources.
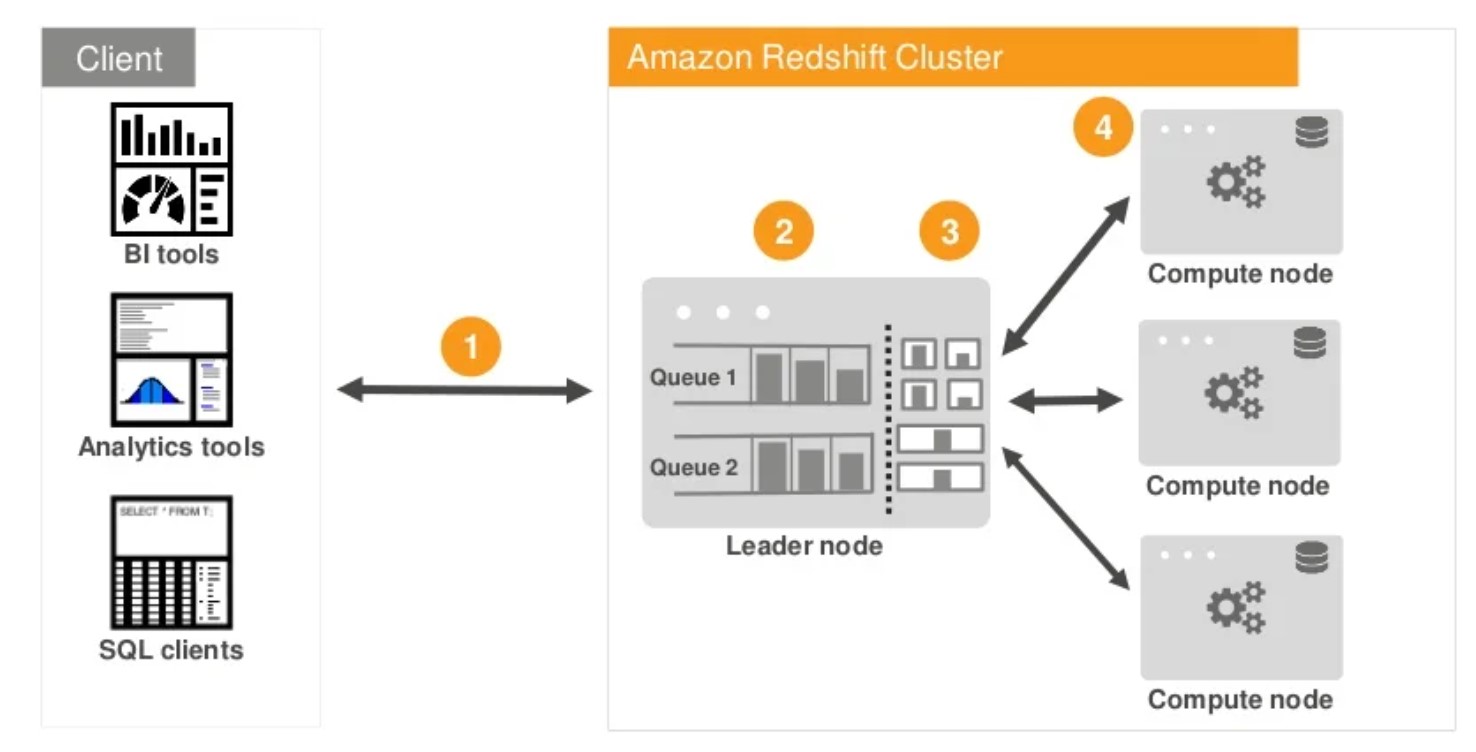
Source: https://aws.amazon.com/redshift/
Amazon Redshift data sharing enables us to extend Amazon Redshift’s ease of use, performance, and cost benefits from a single cluster to multi-cluster deployments while exchanging data. Data sharing allows Redshift clusters to access data instantly, granularly, and quickly without having to copy or relocate it. Data sharing allows the users to have real-time access to data, ensuring that they view the most up-to-date and consistent information as it is updated in the data warehouse.
Even with shifting workloads or concurrent user activity, Amazon Redshift’s advanced machine learning capabilities ensure great throughput and performance. To dynamically manage speed and concurrency while also helping you prioritise your business-critical workloads, Amazon Redshift employs advanced algorithms to forecast and classify incoming queries based on their run times and resource requirements. Brief query acceleration (SQA) routes short queries from dashboard apps to an express queue for quick processing, rather than being slowed down by big queries. Automatic workload management (WLM) uses machine learning to optimise query speed by dynamically managing memory and parallelism. Furthermore, even when hundreds of questions are filed, you can now quickly adjust the priority of your most critical requests.
Limitations of Redshift
Redshift is a great data warehousing platform. The entire service has been adjusted and optimised for one sort of workload and analytics processing. However, it has some limitations.
- When Redshift is utilised for data warehousing, indexing becomes a challenge. To index and store data, Redshift employs distribution and sort keys. To work on the database, you’ll need to understand the ideas underlying the keys. AWS does not provide a way for changing or managing keys with only rudimentary expertise.
- AWS Redshift does not include any tools or methods for ensuring data uniqueness. There will be duplicate data points when moving overlapping data from several sources to Redshift.
- Redshift is utilised when a large amount of data has to be stored or processed. It will at the very least be in the petabyte range. Bandwidth becomes an issue at this point. Before you can begin the project, we’ll need to transfer these data to AWS locations.
Conclusion
Every day, more data is generated, stored and collected. Redshift is a safeguard against the growing volume of data and the increasing analytical complexity. It may be utilised to develop and build long-lasting infrastructure.
Some important highlights about Amazon Redshift are:
- Amazon Redshift has a Massively Parallel Processing Architecture. The MPP Architecture enables Redshift to distribute and parallelize queries across multiple nodes.
- Apart from queries, the MPP architecture also enables parallel operations for data loads, backups and restores.
- Database Constraints and Indexes are neither enforced nor supported by Redshift.
- Redshift, like all other AWS services, comes with a variety of security protections.
- Although Amazon’s tools lessen the demand for a full-time database administrator, it does not eliminate the necessity for one.
- In an environment with frequent deletes, Amazon Redshift is known to struggle with storage management.
Furthermore, Redshift provides best-in-class performance for a fraction of the price of competitors. Using Redshift seems to be a very good value proposition for any small firm or startup who wants their web app up and running and get good results. The importance of Redshift lies in the fact that it is very easy to use and versatile.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Prateek is a final year engineering student from Institute of Engineering and Management, Kolkata. He likes to code, study about analytics and Data Science and watch Science Fiction movies. His favourite Sci-Fi franchise is Star Wars. He is also an active Kaggler and part of many student communities in College.







