Prompt Engineering in GPT-3
This article was published as a part of the Data Science Blogathon.
Introduction
What are Large Language Models(LLM)?
Most of you definitely faced this question in your data science journey. Large Language Models are often tens of terabytes in size and are trained on massive volumes of text data, occasionally reaching petabytes. They’re also among the models with the most parameters, where a “parameter” is a value that the model may alter independently as it learns.
LLM is the most searched topic by data scientists and data science enthusiasts for the last few years. Different language models can be used to do different NLP and ML tasks such as classification, summarization, translation, question answering, etc. A probability distribution over word sequences is a statistical language model(Language Model). It assigns a probability P to the entire series given a sequence of length m. The language model gives context for distinguishing between phonetically identical words and phrases. Each year a number of new language models are evolving by creating a new benchmark. The number of parameters is also increasing in each model.
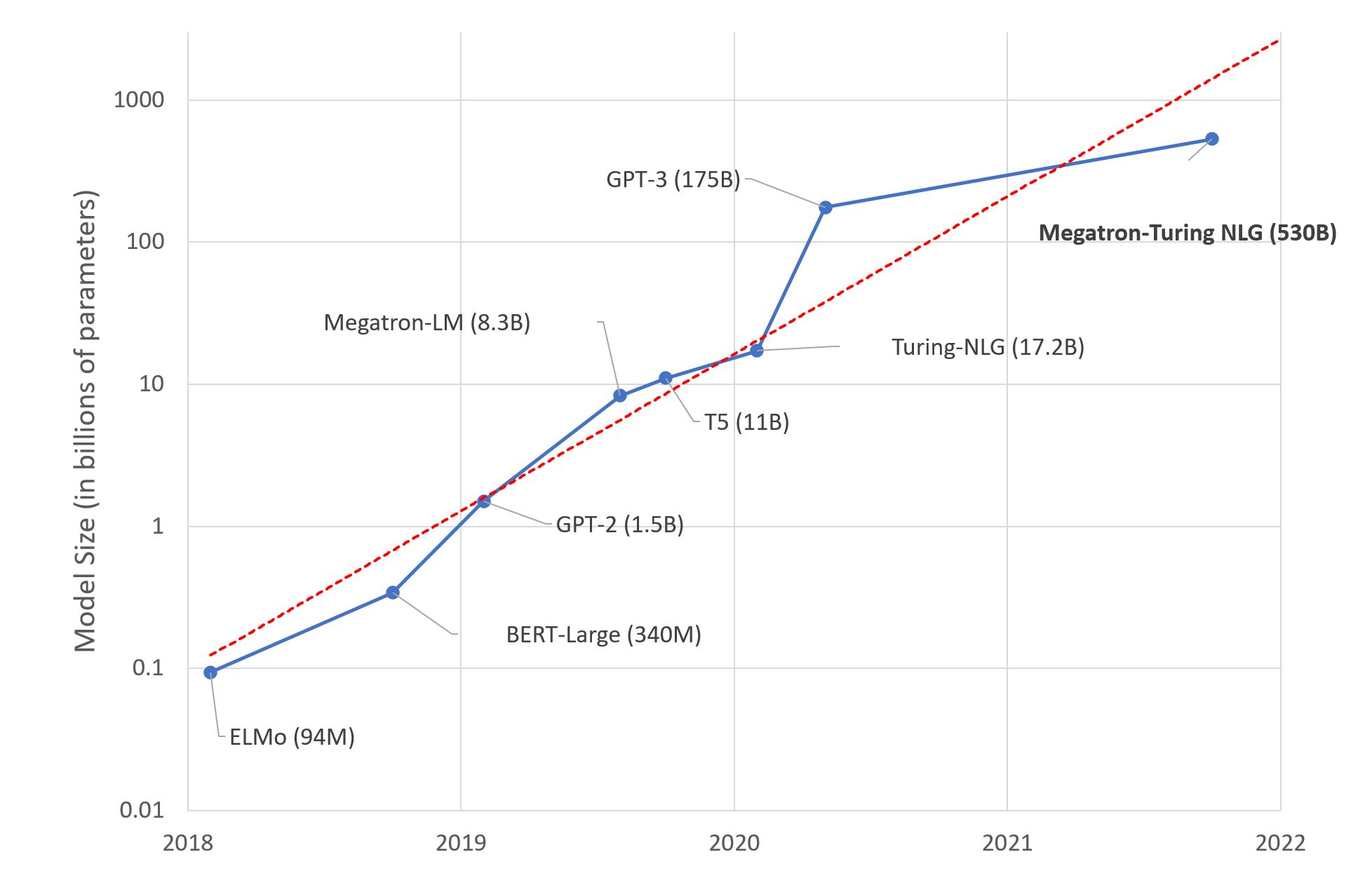
For the past few years, the size of large language models has increased by a factor of ten per year. It’s beginning to resemble another Moore’s Law.
Even though we have enough language models now itself, all the data science enthusiasts are eagerly waiting for the arrival of the new superhero- who is none other than GPT-4.
The day for the release of GPT-4 is getting closer. According to current projections, the model will be released in 2022, most likely in July or August. So before that royal entry, we should make our hands dirty by playing with the current GPT model which is GPT-3. In this article, I am trying to explain to you a very fundamental concept that we need to understand before moving to play with GPT models, which is – Prompt engineering.

Prompts in GPT-3
Due to security reasons, GPT-3 is not open source and will be available only through an API. OpenAI’s OpenAI API service, a cloud-based application programming interface with usage-based billing, makes GPT-3 available to developers. Natural language processing includes natural language generation as one of its primary components, which focuses on creating human language natural text. The main purpose of GPT-3 is natural language generation. Along with natural language generation, it supports lots of other tasks. Some of those are listed below.
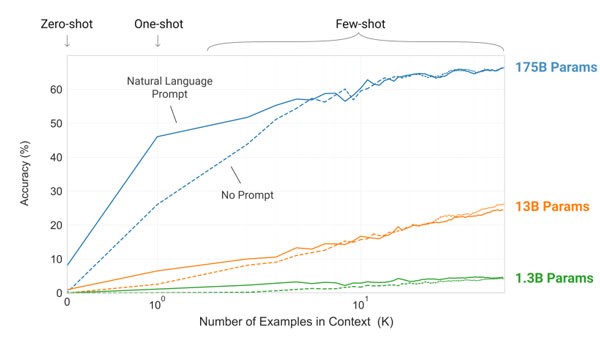
GPT-3 adds 175 billion parameters to the GPT-2 design, as well as altered initialization, pre-normalization, and configurable tokenization. It displays strong performance on a variety of NLP tasks and benchmarks in three different scenarios: zero-shot, one-shot, and few-shot. Among that one-shot learning and few-shot learning, the user needs to provide some expected input and output of the specific use-case to the API. After that, the user needs to provide a sample trigger to generate the required output. This trigger is called the prompt in GPT-3. In GPT-3’s API, a ‘prompt‘ is a parameter that is provided to the API so that it is able to identify the context of the problem to be solved. Depending on how the prompt is written, the returned text will attempt to match the pattern accordingly. The below graph shows the accuracy of GPT-3 with prompt and without prompt in the models with different numbers of parameters. From this chart, we can clearly identify the importance prompt based modeling in GPT-3.
Next, we will discuss how to create the prompts for different tasks in GPT-3, which is called prompt engineering.
From creating original stories to doing intricate text analysis, GPT-3 can do it all. Because they can accomplish so many things, you must be specific in your instructions. A excellent prompt generally relies on showing rather than telling. Prompt creation follows three main guidelines:
Show and tell: Make your intentions obvious by using instructions, examples, or a combination of the two.
Provide quality data: Make sure there are enough samples if you’re trying to develop a classifier or get the model to follow a pattern.
Check your settings: The top_p and temperature settings determine how predictable the model is in providing a response.
As I mentioned at the beginning, due to the security purpose GPT-3 is not open source yet. It is available only through the API now. For getting the API you should signup into the openAI platform. In the early times, there was a waiting list for getting the API key. Thank God..!! but now the wishlist has been removed by the openAI team and you will get the key at the signup time itself. For understanding more about the portal, check the official webpage here.
You can use the openAI python wrapper library(check here for more details)to work with GPT-3. This can be used in other methods like curl, JSON, and node.js also. But here I am going to show you the examples in the GPT-3 basic playground terminal which is provided on the openAI website.
Next, we are going to check the different types of prompt design for various tasks in Natural Language Processing using GPT-3.
Text Classification
Prompt:
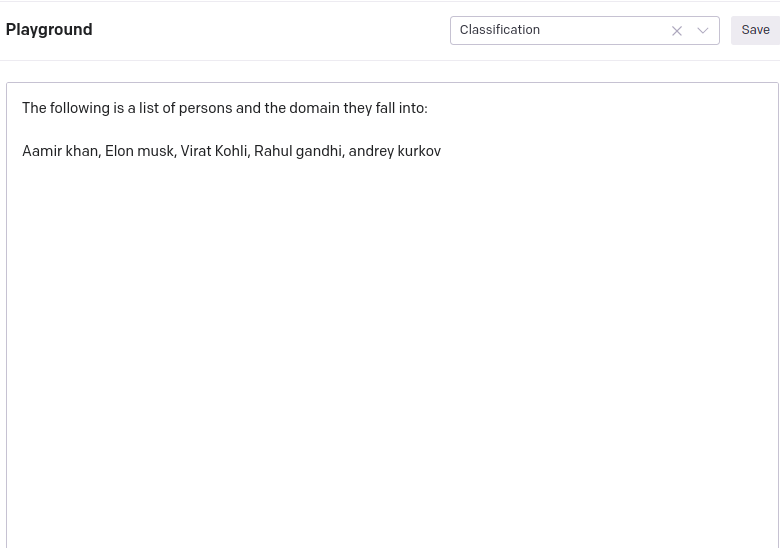
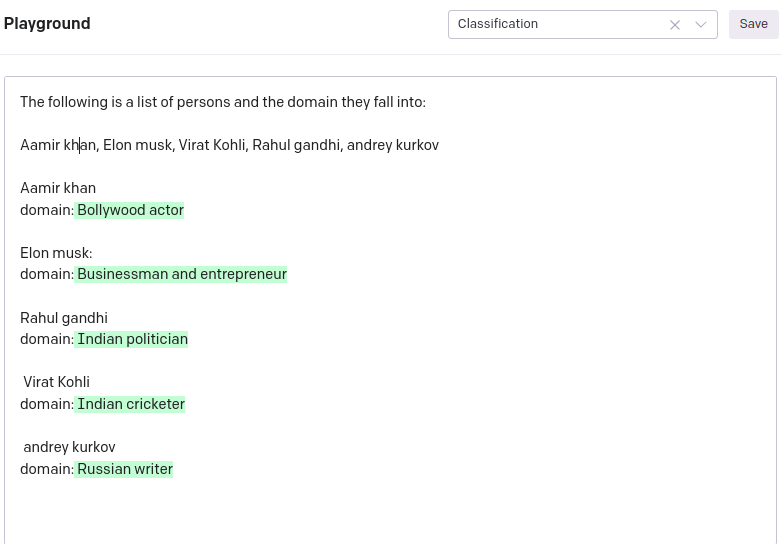
The following is a list of persons and the domain they fall into: Aamir khan, Elon musk, Virat Kohli, Rahul gandhi, Andrey kurkov
Description:
Here we are showing some celebrities’ names, who are popular in their domains, and asking the GPT-3 engine to classify them according to their domain. This is the perfect example of zero-shot classification. That is system is classifying the names based on its own trained world knowledge. We are not providing any sample examples to train the system.
GPT-3 playground image:
Output:
Entity Extractor
Prompt:
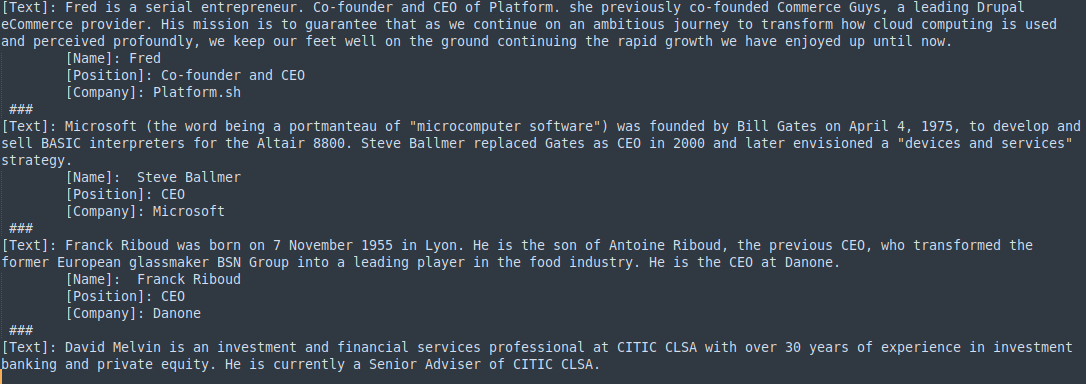
Here is the perfect example of few-shot learning. We need to extract some entities from a passage. So we are feeding some examples to the system and training the system to learn from those few examples. The ### token is used to differentiate between different training examples. Finally, the testing sentence will be given and the system will be able to extract the entities from the text. We can modify/alter the outputs by changing the configurations like temperature, Top p..etc showing at the left panel of the window.
GPT-3 Playground image:

Output:

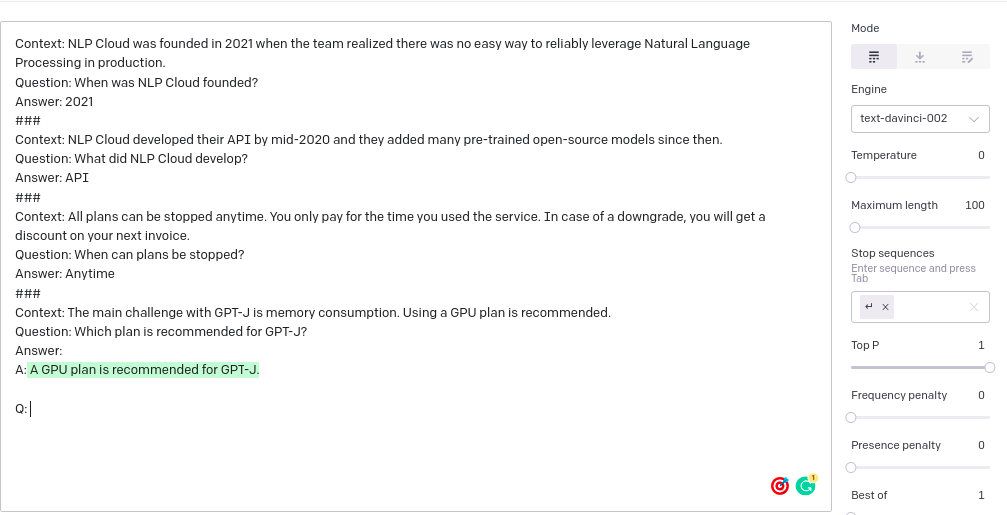
Question Answering
Prompt:
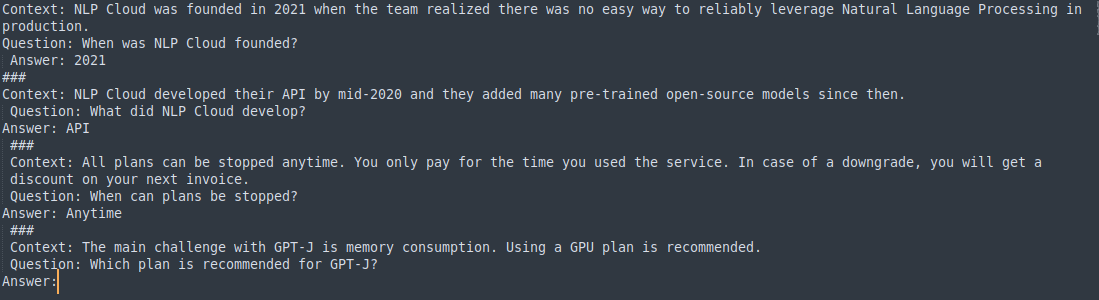
Description:
This is also an example of few-shot learning. The task we are going to handle is unstructured question answering. By providing a context with a question, we are training the model to predict the answer to the question from the context. Some examples are passed to the model for training purposes. Every example is distinguished with the token – ###. If you are not satisfied with the GPT-3 provided answer, you can change the engine(current engine is – text-davinci-002) and other hyperparameters (temperature and top_p, etc) for generating other answers.
GPT-3 Playground image:
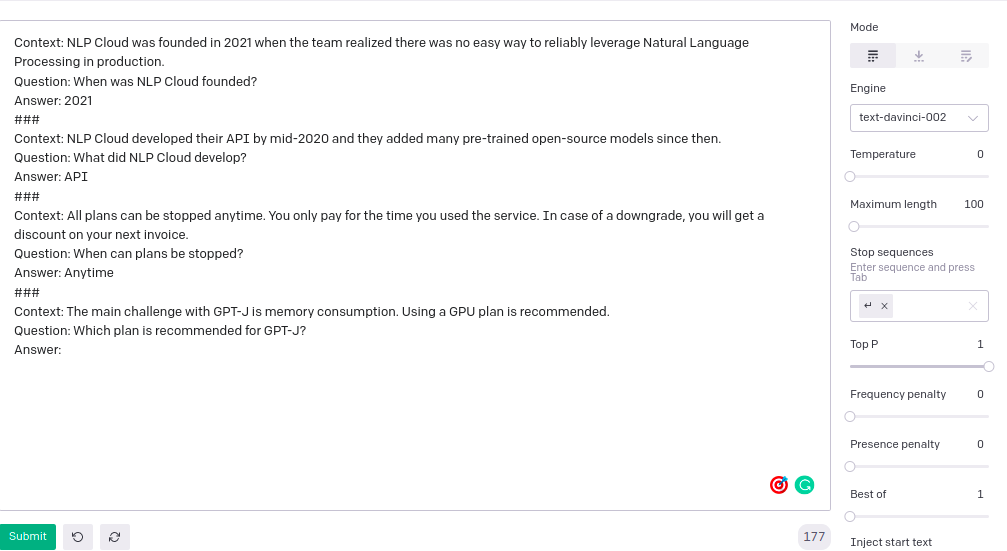
Output:
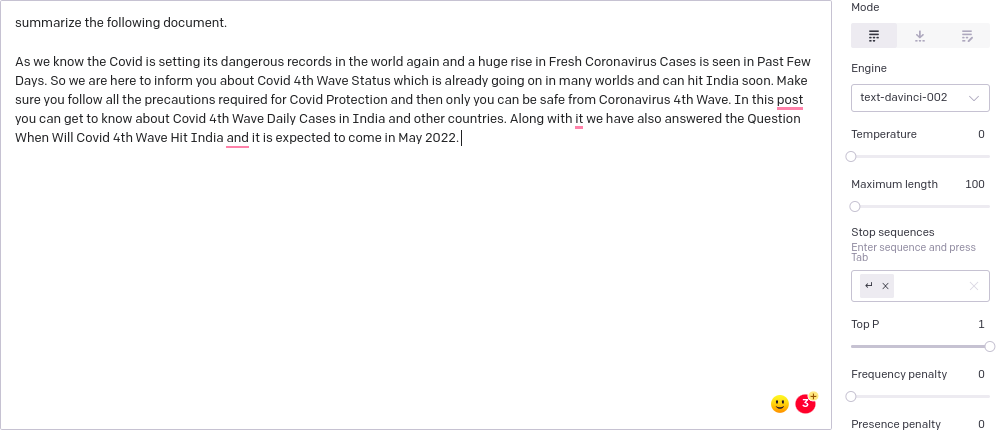
Text Summarization
Prompt:

Description:
The process performed here is automatic text summarization, one of the popular activity in natural language processing. GPT-3 handles the task as a zero-shot learning strategy. Here in the prompt, we are just telling that, summarize the following document and provide a sample paragraph as input. No sample training examples are given since it is zero-shot learning, not few-shot learning. After triggering the API, we will get the summarized format of the input paragraph. If you are not satisfied with this summarization result you can improve the accuracy by either changing the model parameters as discussed above section or providing some examples as few-shot learning.
GPT-3 Playground image:
Output:

Text Completion
Prompt:

Description:
While all prompts result in completions, in situations where you want the API to start up where you left off, it’s useful to conceive of text completion as its own task. For example, if this query is given, the API will continue thinking about long lining. You can lower the temperature setting to keep the API focused on the prompt’s intent, or raise it to allow it to wander.
GPT-3 Playground image:

Output:

Conclusion
From creating original stories to doing intricate text analysis, openAI GPT-3 can do it all. Because they can accomplish so many things, you must be specific in your instructions. Various NLP tasks such as text classification, text summarization, sentence completion, etc can be done using GPT-3 by prompting. An excellent prompt generally relies on showing rather than telling.
Prompt creation follows three main guidelines:
Show and tell, Provide Quality data, and Change settings.
Along with that, we can get the outputs in three ways
Zero-shot learning: Where no examples are given for training.
One-shot learning: Here only one example is provided for the training purpose
Few-shot learning: Where we can provide a few examples to train the model along with the prompt.
GPT-3 is not open source yet and is only available via the openAI API. Here I have showcased to you the examples in the GPT-3 basic playground terminal which is provided on the openAI website, rather than any programming language wrapper of openAI.
The simplest kind of Artificial General Intelligence is GPT-3. Because a single model can perform multiple types of Natural Language Processing jobs. It operates on the basis of prompts, and a strong prompt can help the model provide the best results. I tried to explain some approaches for creating good prompts in GPT-3 playground using examples in this article. I hope this article has helped you learn more about GPT-3 prompts and how to create your own. Please share any problems you experience while creating the prompts, as well as any thoughts, suggestions, or comments, in the section below.
Happy coding..😊
Frequently Asked Questions
A. Prompt engineering in GPT refers to the process of carefully designing or modifying the input prompt to influence the behavior or output of the language model. It involves constructing specific instructions, adding context, or providing example inputs to guide the model’s response. Prompt engineering is used to improve the relevance, accuracy, or style of generated text by steering the model towards desired outputs.
A. GPT-3 prompt refers to a specific type of input used to generate text using the Generative Pre-trained Transformer 3 (GPT-3) language model. A prompt is a short piece of text that is used to initiate the language model’s text generation process.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







