This article was published as a part of the Data Science Blogathon.

Introduction
- Description of Data
- Pre-processing
- Embedding Layers
- Model Architecture
- Results
Description of Data
The data for this task is taken from a Kaggle dataset of around 45K news articles. Around half of the data are fake articles pulled from various US-based websites that have been deemed unreliable by fact-checking organisations, with the other half being true articles pulled from Reuters, a US news website.
An example of what these articles look like can be seen below.

Given that all of the articles are coming from US sources and that all of the true articles are coming from the same US source, this is clearly not a perfect fake news dataset. Others have also identified some leakage in the dataset. Leakage is when information is available in the training data for a model to predict with that it wouldn’t have access to in the real world. Steps will be taken in the pre-processing to try and minimise the impacts of this leakage.
Despite these shortcomings, the original paper that the dataset was produced in has nearly 200 citations on Google Scholar and it appears to be one of the only fake news datasets that is publicly available.
CAVEAT: The approach outlined here may work for this particular dataset, but would perhaps generalise poorly to other collections of fake/real news.
Pre-processing
The first step in pre-processing is to load the data in and create a field to indicate whether the article was fake (1) or true (0). Both title and text fields (of each article) are used to de-duplicate the data and are then merged into one long “all_text” field. To address previously identified leakages the date and subject columns are dropped, as are a number of informative keywords (“reuters”, “politifact” etc).
Python Code:
The next step in pre-processing is to tidy up our text data and convert it into sequences of numbers. Neural networks need numbers to be able to learn/predict with, so each unique word in the dataset needs to be converted into a number first.
The Keras
Tokenizerandpad_sequencesfunction can take care of this for us extremely easily.
The Tokenizer filters out special characters and converts text to lowercase. It then maps each unique word (a.k.a. token) to a number such that each word in all our articles can now be represented by a single number. pad_sequences ensures that all of the sequences of these numbers are the same length (500 tokens long) by either pre-padding articles that are too short with whitespace/zeroes or by post-truncating articles that are too long. This is necessary as Keras requires inputs to be of the same length (for a fuller discussion, see here).
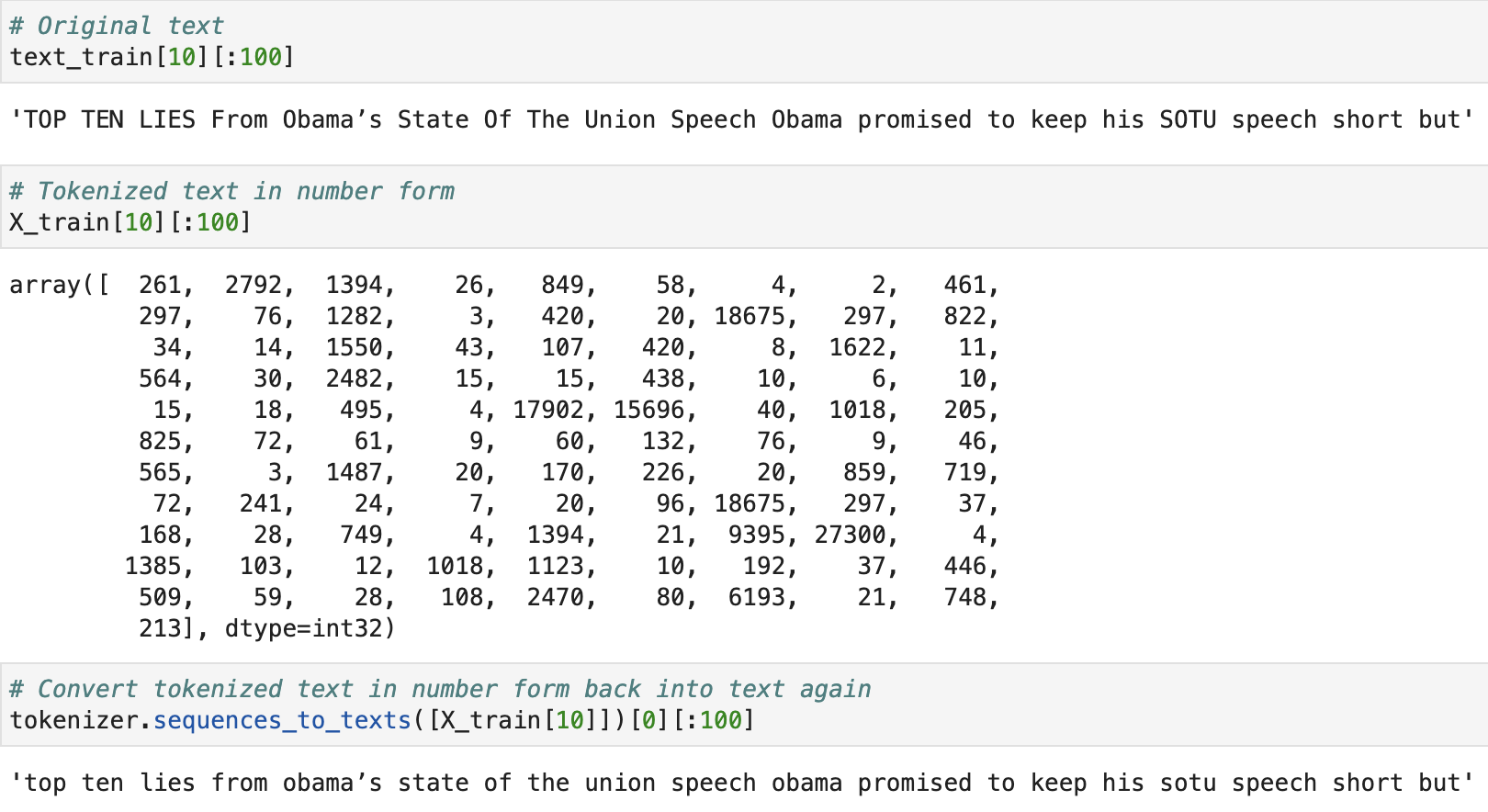
We can check that everything went to plan by examining one of our articles. We can compare the 1st 100 tokens for the (e.g.) 10th article in the training data with the 1st 100 tokens of the 10th article in the tokenized training data. We can then use the sequences_to_texts method from our Tokenizer object to convert the sequence of numbers back into words and check that it matches the original article (minus special characters and uppercase).
It seems to have worked!
Embedding Layers
Embedding is a technique often used in Natural Language Processing to represent words in a reduced number of dimensions. For example, if our fake news dataset contained a vocabulary of only 1000 words (e.g. only 1000 unique words) then each word could be represented by a vector of 999 0s and a single 1. 999 instances of it not being one of our 1000 words and 1 instance of it being 1 of our 1000 words. This is known as one-hot encoding.
While this is a relatively easy way of handling text data, it is inefficient. The resulting vectors would be highly sparse- in our example each vector is entirely sparse except for the single 1. Furthermore, none of the information on the relationships between words is preserved. This is where embedding layers demonstrate their value- they can take sparse, high-dimensional, one-hot encoded vectors and represent them in a more dense, low-dimensional space. The added benefit of this approach is that words that have a similar meaning will now have a similar representation in our embedding of them.
Word embeddings can take sparse, high-dimensional, one-hot encoded vectors and represent them in a more dense, low-dimensional space
spaCy
spaCy is an open-source library for NLP in Python. We will be using the en_core_web_sm package from it, which is a small English-language pipeline that has been trained on blogs, news and comments (so is appropriate to our task). We’ll use the package’s pre-trained embedding with our data, e.g. to represent our text data in spaCy’s embedding. We’ll be using it statically, by setting trainable=False as seen in the code below. Alternatively, we could just use the spaCy embedding to seed our model with and then have it be updated throughout training. However, it perhaps makes for a more interesting comparison with the custom, Keras embedding if the spaCy embedding remains fixed.
Keras / Custom
Keras can also be used to generate a word embedding that is specific to your training data and that will be learned along with your model during training. This may be able to more flexibly learn the text data we have, but would probably not generalise as well to new data as a model learned with the spaCy embedding.
Model Architecture
Since our data is sequential (e.g. words in a sentence) a Gated Recurrent Unit could be used in the neural network we’re building (see here or here for more details). GRUs have been found to perform similarly to other recurrent units such as the long short-term memory (LSTM) unit (Chung et al., 2014) but with the added advantage that they can be faster to train.
Additionally, we will be using the Keras Bidirectional layer. Whereas a standard GRU trains only once on the input sequence, a bidirectional GRU will train twice- once on the input sequence and once again on a reversed copy of the input sequence. The hope is that this will provide extra context to the network that yields faster and better learning. Indeed, bidirectional models have been shown to outperform unidirectional models in other fake news detection research (Bahad et al., 2019).
For the network with a Keras embedding, our model summary will look like this:
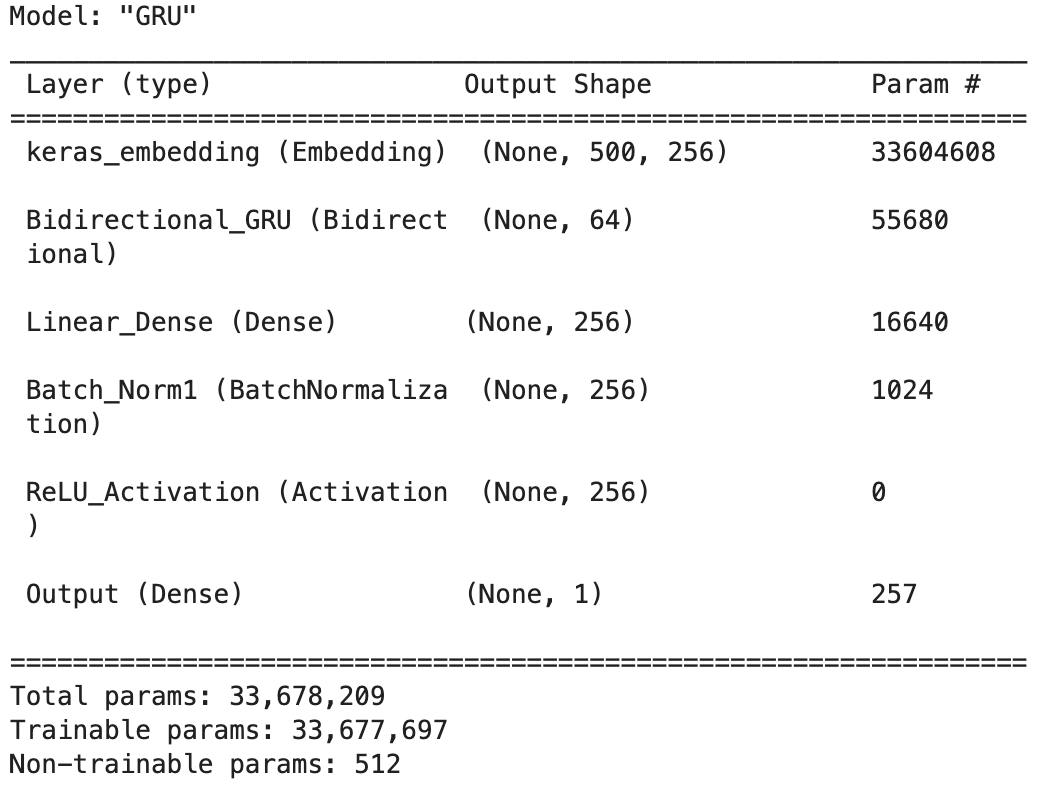
Batch normalization is implemented (if desired) as outlined in the original paper that introduced it, i.e. after the Dense linear transformation but before the non-linear (ReLU) activation. The output layer is just a standard Dense layer with 1 neuron and a sigmoid activation function (that squishes predictions to between 0 and 1), such that our model is ultimately predicting 0 or 1, fake or true.
Batch normalization can help speed up training and provides a mild regularizing effect.
embedding_layer = "spacy" in line 73.Results
Both the Keras- and spaCy-embedded models will take a good amount of time to train, but ultimately we’ll end up with something that we can evaluate on our test data with.
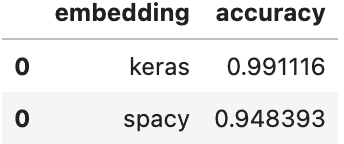
Overall, the Keras-embedded model performed better– achieving a test accuracy of 99.1% vs the spaCy model’s 94.8%.
Conclusion
To conclude, I would like to share the below key takeaways with you all:
- Pre-process your text data with Keras Tokenizer and the pad_sequences function
- Decide on an embedding to use; either pre-trained/transfer learning or a custom one learned from your dataset
- Add in a bi-directional GRU to your network (after the embedding), along with a batch normalized Dense layer and a sigmoid-activated output layer
- Train and fit your model – it may take a while to train, but will eventually achieve high test accuracies on the fake news dataset
For full code and a demo notebook please check out the GitHub repo!
Links
- LinkedIn : Louis Magowan
- GitHub: fake_news_classifier
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







