A Detailed Introduction on Data Lakes and Delta Lakes
This article was published as a part of the Data Science Blogathon.
Introduction
A data lake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. You may run different types of analytics, from dashboards and visualizations to big data processing, real-time analytics, and machine learning to help you make better decisions without first structuring your data.
A data lake uses a flat design to store data, generally in files or object storage, as opposed to a traditional data warehouse, which stores data in hierarchical dimensions and tables. Users now have more options for managing, storing, and using their data.
Development of Data Lakes
As a result of data warehouses’ shortcomings, data lakes were created. Although data warehouses offer businesses very effective and scalable analytics, they are costly, proprietary, and unable to handle the contemporary use cases that the majority of businesses are looking to address. In contrast to a data warehouse, which imposes a schema (i.e., a formal framework for how the data is arranged) up front, data lakes allow for storing all of an organisation’s data in a single, central location where it can be kept as is.
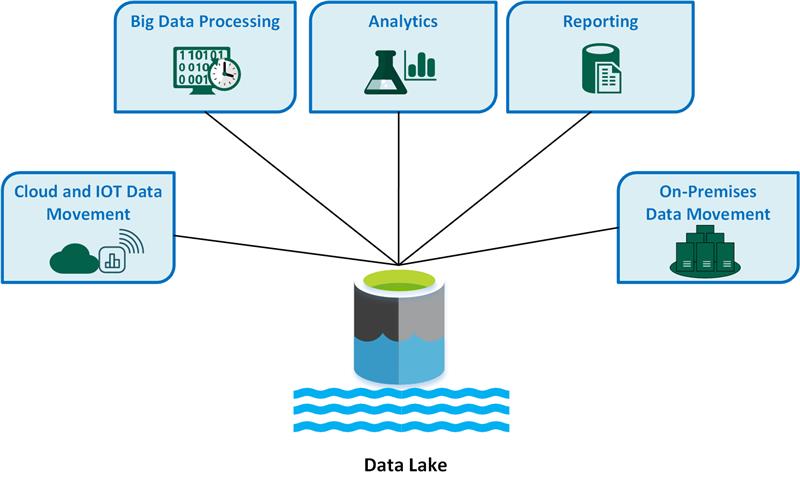
Image: https://docs.microsoft.com/en-us/azure/architecture/data-guide/scenarios/data-lake
A data lake can hold data at all phases of the refinement process, including intermediate data tables created during the refinement of raw data. Raw data can be ingested and stored alongside an organisation’s structured, tabular data sources (such as database tables). Data lakes can process all data kinds, including unstructured and semi-structured data like photos, video, audio, and documents, which is essential for today’s machine learning and advanced analytics use cases. This is in contrast to most databases and data warehouses.
Why should we use Data Lakes?
Data Lakes are very useful and convenient, let us analyse the need and use for Data Lakes.
- Hadoop systems and data lakes are frequently mentioned together. Data is loaded into the Hadoop Distributed File System (HDFS) and stored on the many computer nodes of a Hadoop cluster in deployments based on the distributed processing architecture. However, data lakes are increasingly being constructed using cloud object storage services instead of using Hadoop. Some NoSQL databases are also used as platforms for data lakes.
- Big data sets that include structured, unstructured and semi-structured data are frequently stored in data lakes. The relational databases that the majority of data warehouses are constructed on are not well suited for such situations. Relational systems can only normally store structured transaction data since they need a fixed data schema. Data lakes don’t require any upfront definition and support a variety of schemas. They can now manage various data kinds in distinct forms as a result.
- Data lakes are therefore a crucial part of many firms’ data architectures. They are typically used by businesses as a platform for big data analytics and other data science applications that involve advanced analytics methods like data mining, predictive modelling, and machine learning and call for massive volumes of data.
- For data scientists and analysts, a data lake offers a central area where they can locate, prepare, and analyse pertinent data. That process is more difficult without one. Additionally, it is more difficult for firms to fully utilise their data assets to support more informed business decisions and strategies.

Image: https://www.computerweekly.com/feature/Data-lake-storage-Cloud-vs-on-premise-data-lakes
Data Lakes have many abilities. The Abilities of Data Lakes are:
- With little latency, data lakes enable the transformation of unstructured raw data into structured data that is ready for SQL analytics, data science, and machine learning. For usage in machine learning and analytics, raw data can be stored for an unlimited amount of time at a cheap cost.
- A centralised data lake provides downstream users with a single location to search for all sources of data, solving the issues associated with data silos (such as data duplication, numerous security rules, and trouble with cooperation).
- Any and all data kinds, including batch and streaming data, video, images, binary files, and more, can be gathered and stored indefinitely in a data lake. Additionally, it is always up to date because the data lake serves as a landing spot for fresh data.
- With the help of data lakes, people with a wide range of abilities, tools, and languages can simultaneously conduct a variety of analytical jobs.
What is a Delta Lake?
The dependability of Data Lakes is guaranteed by the open-source data storage layer known as Delta Lake. It integrates batch and streaming data processing, scalable metadata management, and ACID transactions. The Delta Lake design integrates with Apache Spark APIs and sits above your current Data Lake. Delta Lake supports scalable metadata handling, ACID transactions, and the unification of batch and streaming data processing. It utilises your current data lake and is completely compatible with the Apache Spark APIs.
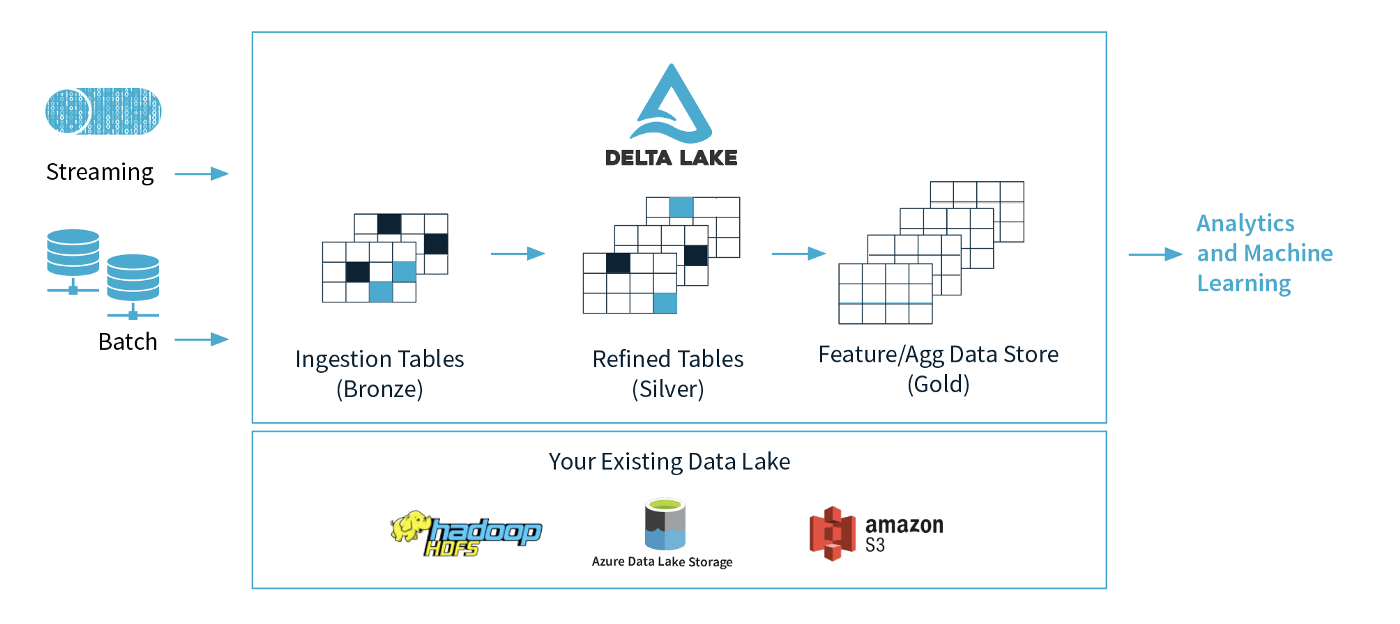 Image: https://mageswaran1989.medium.com/databricks-delta-lake-6756dd3a4bf9
Image: https://mageswaran1989.medium.com/databricks-delta-lake-6756dd3a4bf9Features of Data Lakes
Let us know more about the features of Delta Lakes.
- Scalable Metadata Handling:
Even petabytes of data may be handled with ease by Delta Lakes. Users can access the metadata using the Describe Detail feature, and it is stored in the same way as other data.
- Schema Enforcement:
Companies frequently utilise Delta Lakes because it upholds the schema. It examines each column, data type, etc. in the Schema, which is read as part of the metadata.
- Unified Batch and Streaming:
A single architecture is offered by Delta Lakes for reading both batch and stream data.
- Upserts and Deletes:
You may easily perform upserts using Delta. These upserts or merges into the Delta table are comparable to SQL Merges. It enables you to apply updates, inserts and deletes as well as integrate data from another data frame into your table.
What do we use Delta Lake?
Big Data architecture is currently challenging to develop, run, and maintain. Streaming systems, data lakes, and data warehouses are typically employed in at least three ways in modern data architectures. Business Data is transmitted through streaming networks, such as Amazon Kinesis and Apache Kafka, which prioritise quicker delivery.
- The data is subsequently collected in Data Lakes, which are made for large-scale, inexpensive storage and include Apache Hadoop or Amazon S3. The most important data is uploaded to data warehouses since, regrettably, data lakes cannot support high-end business applications on their own in terms of performance or quality. These have significantly higher storage costs than Data Lakes but are tuned for considerable Performance, Concurrency, and Security.
- A batch and streaming systems prepare records simultaneously in a lambda architecture, a common record-preparation technique. The outcomes are then combined during inquiry time to provide a comprehensive response. Due to the stringent latency requirements for processing both recently produced events and older events, this architecture gained notoriety.
- The primary drawback of this architecture is the development and operational burden of maintaining two independent systems. In the past, attempts have been made to integrate batch and streaming into a single system. Companies haven’t always been successful in their attempts, on the other hand.
- A key component of the vast majority of databases is ACID. However, it is challenging to offer the same level of dependability ACID Databases give when it comes to HDFS or S3. Delta Lake implements ACID Transactions in a Transaction Log by keeping track of all the commits made to the record directory. The Delta Lake Architecture offers serializable isolation levels to guarantee data consistency among numerous users.
Why is Delta Lake important?
The power to establish the schema and aid in its execution provided by Delta Lake helps stop hazardous material from reaching your data lakes. By preventing faulty data from entering the system before it is digested into the Data Lake and by presenting logical Failure Signals, it prevents Data Corruption.
- Data Versioning offers Rollbacks, Full Audit Trails, and repeatable Machine Learning procedures when using Delta Lake.
- The Delta Lake Architecture, which supports merge, update, and delete operations, enables complicated Use Cases such as Change-Data-Capture, Slowly-Changing-Dimension (SCD) activities, Streaming Upserts, and others.
- Organizations have opted for Delta Lake, an open format data management and governance layer incorporating the finest features of both data lakes and data warehouses, to construct a successful lakehouse. Businesses are using Delta Lake across industries to power collaboration by offering a dependable, single source of truth.
- Delta Lake eliminates data silos and makes analytics available throughout the organisation by delivering quality, stability, security, and performance on your data lake – for both streaming and batch operations. Customers may create a highly scalable, cost-effective lakehouse with Delta Lake that eliminates data silos and offers end users self-serving analytics.
Conclusion
We read about Data Lakes and Delta Lakes, now to Conclude:
- Applications for data science and advanced analytics are built on data lakes. As a result, they assist firms in better managing corporate operations and spotting market trends and opportunities. For instance, a business can enhance its online advertising and marketing campaigns by using predictive models on client purchasing behavior. Data lake analytics might also benefit from risk management, fraud detection, equipment maintenance, and other business processes.
- By merging data sets from several systems in a single repository, data lakes, like data warehouses, assist in dismantling data silos. This streamlines the process of locating pertinent data and getting it ready for analytics usage while providing data science teams with a complete perspective of the data that is accessible. Removing redundant data platforms from a business, it can also assist lower IT and data management expenditures.
- As corporate needs and concerns evolve, so does the form of data. However, Delta Lake makes it easy to add additional Dimensions as the data changes. Data Lakes’ performance, dependability, and manageability are all enhanced by Delta Lakes.
Delta Lakes offers a unified platform to accommodate both Batch Processing and Stream Processing workloads on a single platform. Hence, Delta Lakes are essential for Data Operations.
Do you want to learn how to build your data lakes in AWS? Read here.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Prateek is a final year engineering student from Institute of Engineering and Management, Kolkata. He likes to code, study about analytics and Data Science and watch Science Fiction movies. His favourite Sci-Fi franchise is Star Wars. He is also an active Kaggler and part of many student communities in College.







