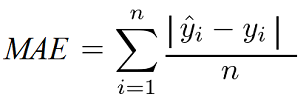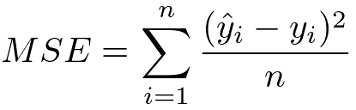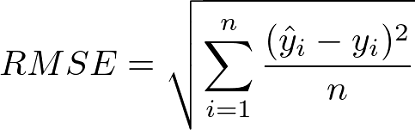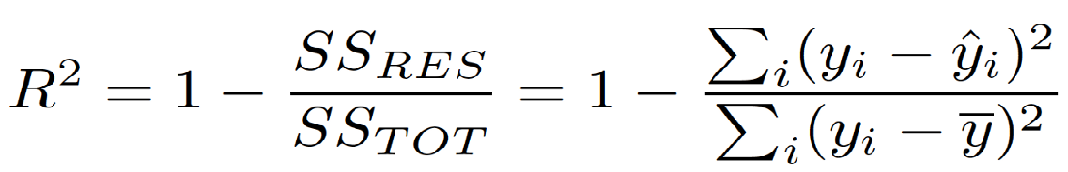This article was published as a part of the Data Science Blogathon.
Introduction
Evaluation metrics are used to measure the quality of the model. Selecting an appropriate evaluation metric is important because it can impact your selection of a model or decide whether to put your model into production.

The mportance of cross-validation: Are evaluation metrics enough? Read more here.
Evaluation Metrics for Classification
To understand Classification evaluation metrics, let’s first understand the confusion metric,
Confusion Metric:
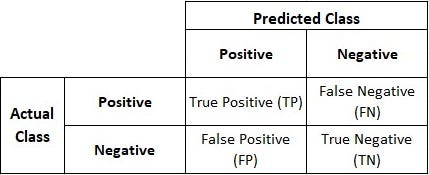
- It is a tabular data format used to visualize classification problems’ performance.
- It is also known as Error Matrix and is used for Supervised Classification algorithms, typically for Binary-Classification algorithms, though it can be used for any classification algorithm.
- It compares how your prediction has fared in comparison to actual values.