This article was published as a part of the Data Science Blogathon.
Introduction
The field of meta-learning, or learning-to-learn, has seen a dramatic increase in interest in recent years. Unlike conventional approaches to AI, where tasks are solved from scratch using a fixed learning algorithm, meta-learning aims to improve the algorithm, considering the experience of multiple learning episodes. This paradigm provides an opportunity to address many of the conventional challenges of deep learning, including data and computational bottlenecks and generalization. This survey describes the current landscape of meta-learning. We first discuss definitions of meta-learning and situate them concerning related fields such as transfer learning and hyperparameter optimization. We then propose a new taxonomy that provides a more comprehensive partitioning of the space of today’s meta-learning methods. We explore meta-learning’s promising applications and achievements, such as multiple trials and reinforcement learning.
The performance of a learning model depends on its training dataset, algorithm, and parameters. Many experiments are needed to find the best performing algorithm and algorithm parameters. Meta-learning approaches help them find and optimize the number of experiments. The result is better predictions in less time.
Meta-learning can be used for various machine learning models (e.g.,
few-shot,
Reinforcement Learning, natural language processing, etc.). Meta-learning algorithms make predictions by inputting the outputs and metadata of machine learning algorithms. Meta-learning algorithms can learn to use the best predictions from machine learning algorithms to make better predictions. In computer science, meta-learning studies and approaches started in the 1980s and became popular after the works of Jürgen Schmidhuber and Yoshua Bengio on the subject.
What is Meta-learning?
Meta-learning, described as “learning to learn”, is a subset of machine learning in the field of computer science. It is used to improve the results and performance of the learning algorithm by changing some aspects of the learning algorithm based on the results of the experiment. Meta-learning helps researchers understand which algorithms generate the best/better predictions from datasets.
Meta-learning algorithms use learning algorithm metadata as input. They then make predictions and provide information about the performance of these learning algorithms as output. An image’s metadata in a learning model can include, for example, its size, resolution, style, creation date, and owner.
Systematic experiment design in meta-learning is the most important challenge.
Source: GitHub
Importance of Meta-learning in Present Scenario
Machine learning algorithms have some problems, such as
- The need for large datasets for training
- High operating costs due to many trials/experiments during the training phase
- Experiments/trials take a long time to find the best model that performs best for a given data set.
Meta-learning can help machine learning algorithms deal with these challenges by optimizing and finding learning algorithms that perform better.
What is Interest in Meta-learning?
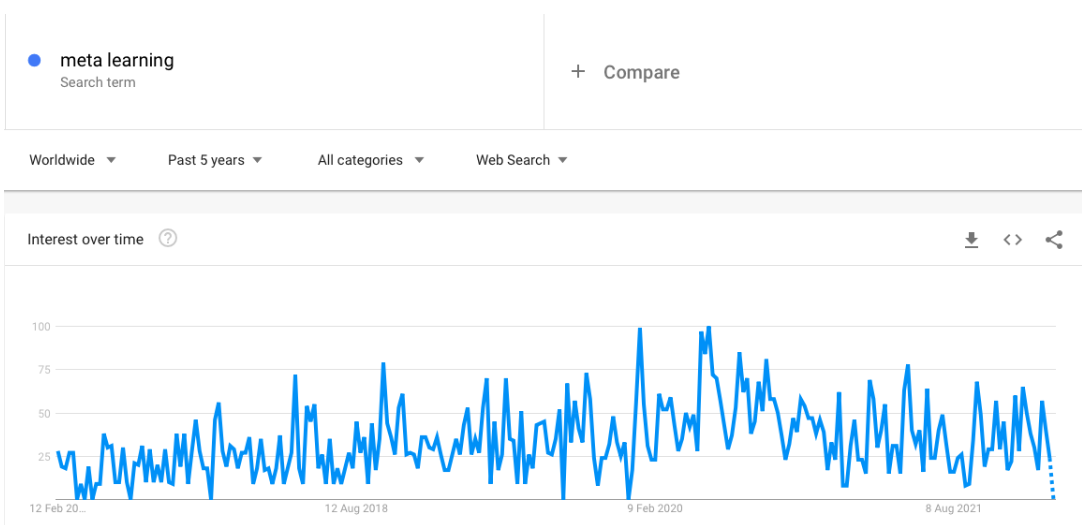
Interest in meta-learning has been growing over the last five years, especially after 2017, it accelerated. As the use of deep learning and advanced machine learning algorithms has increased, the difficulty of training these algorithms has increased interest in meta-learning studies.
Source: aimultiple
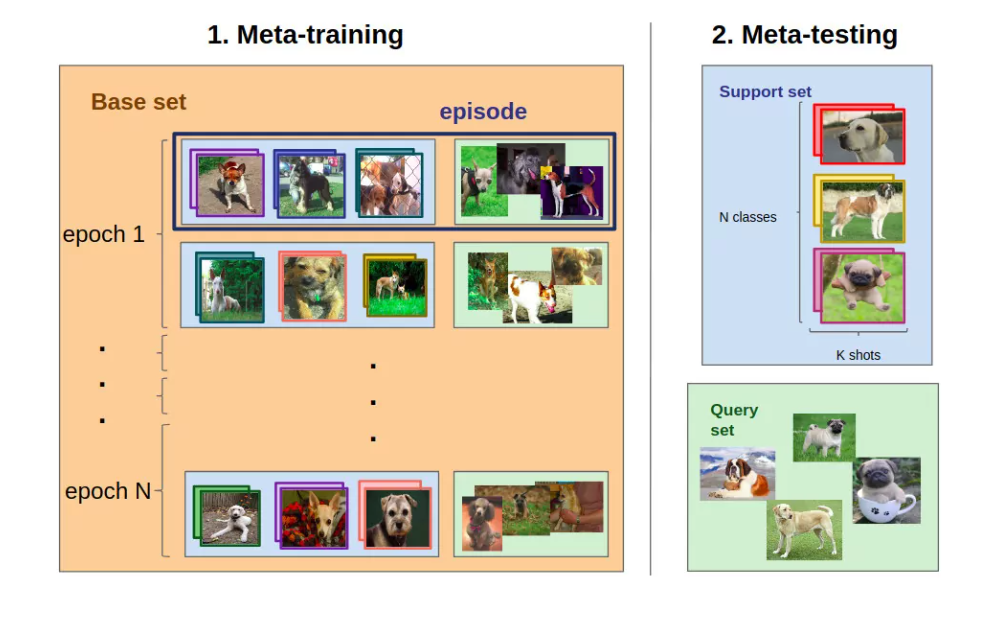
Working of Meta-learning
In general, a meta-learning algorithm is trained using the outputs (i.e., model predictions) and metadata of machine learning algorithms. After training is done, its skills are sent for testing and used to make end/final predictions.
Meta-learning includes tasks such as
- Observing the performance of different machine learning models on learning tasks
- Learning from metadata
- The faster learning process for new tasks
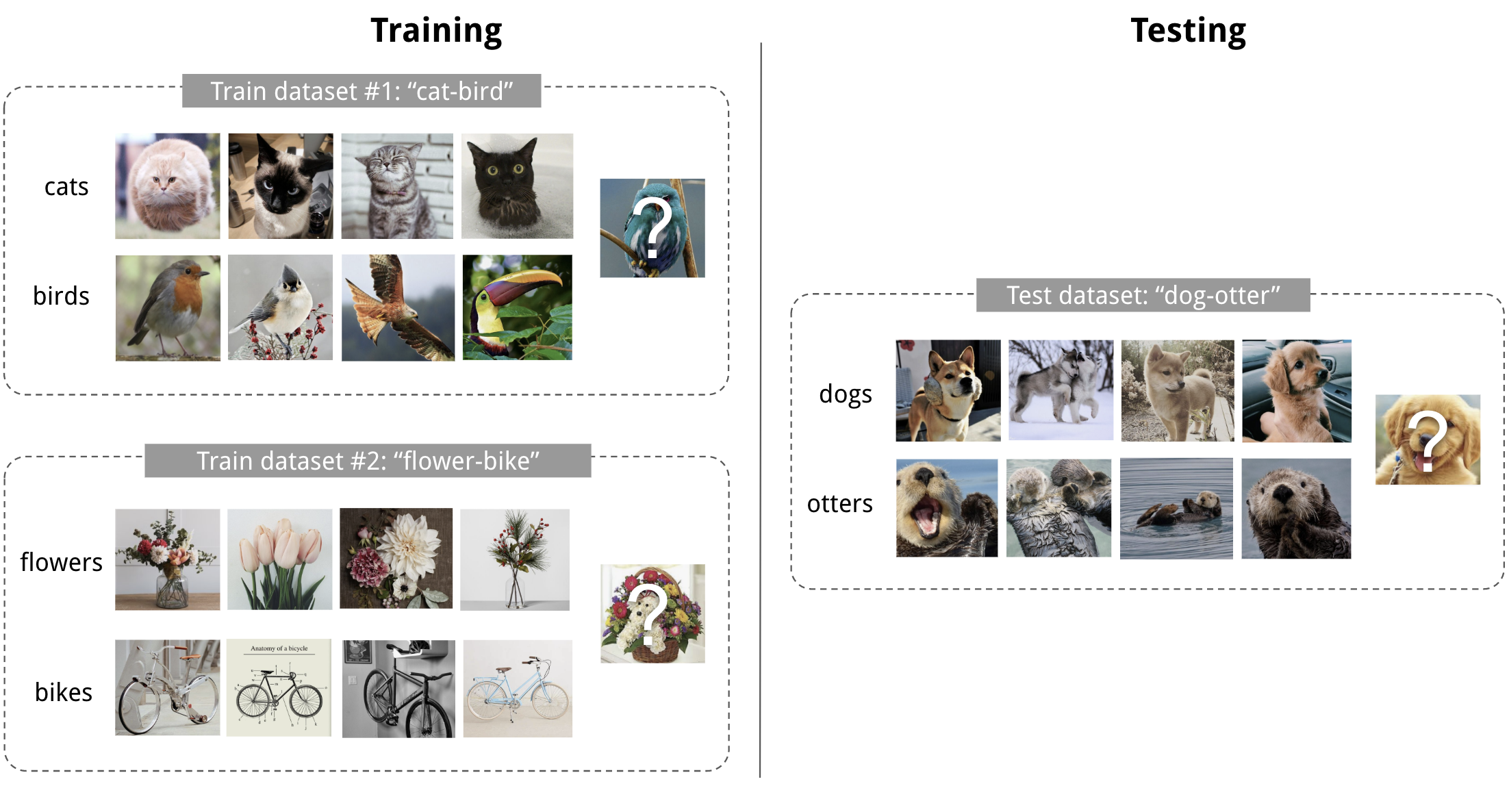
For example, we may want to train a machine learning model to label discrete breeds of dogs.
- First, we need an annotated dataset.
- Different ML models are built on the training set. They could only focus on certain parts of the dataset.
- A meta-training process is used to improve the performance of these models
- Finally, the meta-training model can be used to build a new model from several examples based on its experience with the previous training process
Source: Springer
Meta-Learning Approaches and Applications
Meta-learning is utilized in various fields of machine learning-specific domains. There are different approaches in meta-learning such as model-based, metrics-based, and optimization-based approaches. Below we have briefly explained some common approaches and methods in the field of meta-learning.
Metric Learning
Metric learning means learning the metric space for predictions. This model provides good results in multiple classification tasks.
Model-Agnostic Meta-Learning (MAML)
The neural network is trained using several examples so that the model adapts to new tasks more quickly. MAML is a general optimization and task-agnostic algorithm that trains model parameters for fast learning with few gradient updates.
Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNNs) are a class/type of artificial neural network. They are used for various machine learning problems such as problems that have sequential data or time series data. RNN models are generally used for translation of Languages, speech recognition, and handwriting recognition. In meta-learning, RNNs are used as an alternative to creating a recurrent model that can collect data sequentially from datasets and process them as new inputs.
Stacking Generalization
Stacking is a subfield of ensemble learning and is used in meta-learning models. Supervised and unsupervised learning models also benefit from compounding. Stacking involves the following steps:
- Learning algorithms are trained using available data
- A merging algorithm (e.g., a meta-learning model or a logistic regression model) is created to combine all the predictions of these learning algorithms, which are called ensemble members.
- A merging algorithm is used to produce the final predictions.
Meta-learning algorithms are widely used to enhance machine learning solutions. The benefits of meta-learning are
higher model prediction accuracy:
- Optimization of learning algorithms: For example, optimization of hyperparameters to achieve the best results. Thus, this optimization task, which is normally performed by a human, is performed using a meta-learning algorithm.
- Helps to learn algorithms better adapt to changing conditions
- Identifying clues for designing better learning algorithms
The faster and cheaper training process
- Supporting learning from fewer examples
- Increase the speed of learning processes by limiting the necessary experiments
Building more generalized models: learning to solve many tasks, not just one task: meta-learning does not focus on training one model on one specific data set
Optimization of Meta-learning
A hyperparameter is a parameter whose value guides the learning process. It is a parameter that is defined before the learning process begins. Hyperparameters have a direct effect on the quality of the training process. Hyperparameters can be tuned. A representative case of a hyperparameter is the number of branches in the decision tree.
Many machine learning models have many hyperparameters that can be optimized. We mentioned that hyperparameters have a great influence on the training process. The hyperparameter selection process dramatically affects how well the algorithm learns.
However, a challenge arises with the ever-increasing complexity of models or neural networks. Because of the complexity of the models, they are increasingly difficult to configure. Consider a neural network. Human engineers can optimize several parameters for the configuration. This is done through experimentation. Yet deep neural networks have a various number of hyperparameters. Such a system has become too complicated for humans to optimize fully.
There are many ways to optimize hyperparameters.
Grid Search: This method uses manually predefined hyperparameters. A group of predefined parameters is searched for the most powerful. Grid search involves trying all possible combinations of hyperparameter values. The model then decides on the most appropriate hyperparameter value. However, this method is considered traditional because it is time-consuming and inefficient.
Random Search: Grid search is an exhaustive method. It involves binding all possible combinations of values. This method takes the place of this exhaustive process with a random search. The model creates random combinations and tries to fit the data set to test the accuracy. Since the search is random, there is a possibility that the model will miss several potentially optimal combinations. On the other hand, it uses much less time than grid search and often provides the ideal solution. A random search can outperform a grid search. This is under the condition that several hyperparameters are needed to optimize the algorithm.
We will cover these two and other optimization methods in another article. However, if you want to learn more about grid search and random search now, check out this hyperparameter tuning conceptual guide.
Conclusion
In this particular tutorial, you explored meta-learning in machine learning.
Specifically, you learned:
- Meta-learning describes machine learning algorithms that acquire the knowledge and understanding from the outcome of other machine learning algorithms.
- Meta-learning algorithms typically refer to ensemble learning algorithms, such as layering, that learn how to combine predictions from ensemble members.
- Meta-learning also refers to algorithms that learn how to learn over a set of related prediction tasks, referred to as multi-task learning.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.