Introduction
This article studies binary sentiment analysis on the IMDb movie reviews dataset. The dataset has 25000 positive and negative reviews in the training set and 25000 positive and negative reviews in the test set.
Source: https://www.predictiveanalyticstoday.com/top-sentiment-analysis-software/
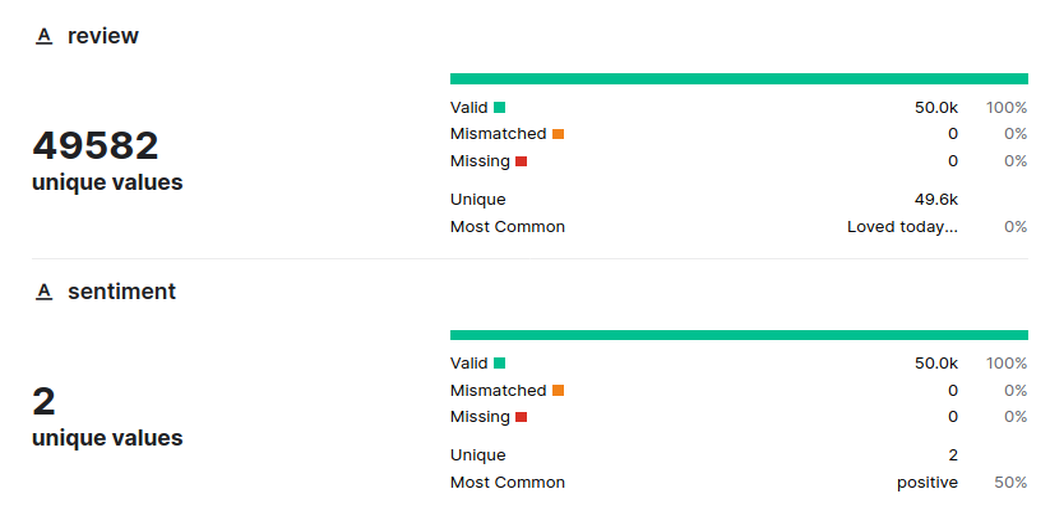
The image below shows the number of unique reviews and unique sentiment values in the dataset. The movie reviews are classified as having either a positive sentiment or a negative sentiment.
Source: https://www.kaggle.com/datasets/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews
The image below takes a peek at four reviews and their target sentiments. As can be seen from the keywords of the first three reviews – hooked, wonderful, unassuming, wonderful – lend the review a positive connotation. The keywords for the fourth review are difficult to find. However, the absence of strongly positive keywords in the first sentence combined with the keyword – zombie – indicates negative sentiment. Based on this preliminary dataset assessment, we proceed to the background and the theory behind text sentiment analysis.

Source: https://www.kaggle.com/datasets/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews
Natural Language Processing (NLP)
Natural language processing is the study of languages using computational-statistical and/or mathematical-logical reasoning to extract meaningful responses from written – machine printed, typewritten, or handwritten – text.
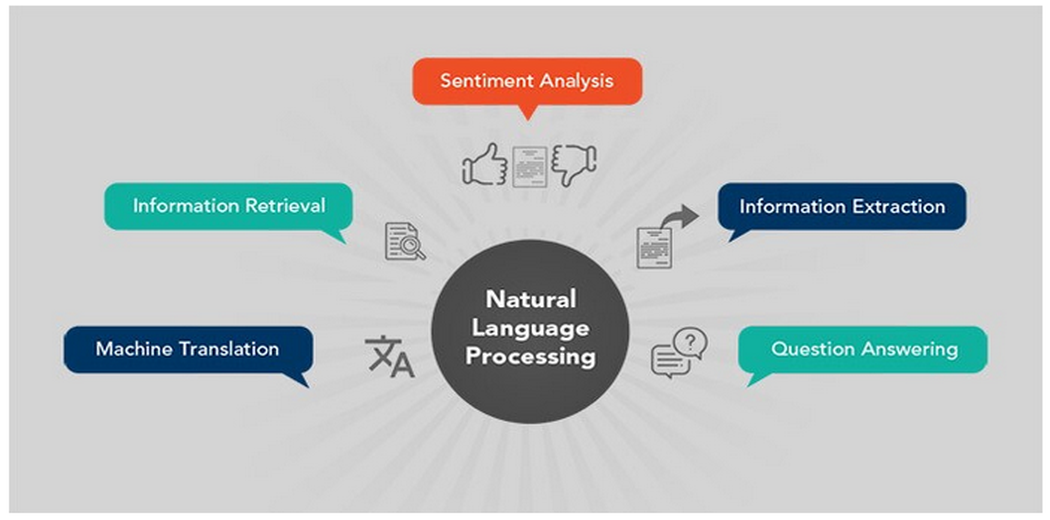
As shown in the image below, natural language processing or computational linguistics can be broadly classified into the following five categories:
1. Machine translation
2. Information retrieval
3. Sentiment analysis
4. Information Extraction
5. Question Answering
Machine translation: This task involves classifying text from one language to another. Speech processing tools can be used to convert spoken language to written text before translating the text. Encoder-decoder models are prevalent in this area of study. An example of a machine translation system is Google translate.
Information retrieval: Systems implementing web search engines typically employ this field of study. Keywords corresponding to web pages are indexed. The top few relevant documents are returned using these keywords based on keyword matching with the query string. An example of a web search engine is the Microsoft Bing search engine.
Sentiment analysis: This field of study involves analyzing the emotions expressed by the author of a piece of text. The feelings can be positive or negative, sadness, anger, happiness, etc. This field of Natural Language Processing is the topic of our study in this article.
Information extraction: This field is employed for extracting relevant and essential information from typed, machine-printed, or handwritten text. This field of study is common in the Intelligent document processing (IDP) industry. Typical examples include carrying out OCR on documents like ID cards and invoices and using NLP to extract relevant information like names and amounts from these documents.
Question answering: This field is concerned with answering questions based on the paragraph or text. An ML model is trained on textual data containing answers to questions. A typical example of this kind of model is the BERT question-answering model. BERT is a transformer-based model where an encoder encrypts the textual data in an n-dimensional vector space while a decoder decrypts the encoded data.
A use case of this field of study can be finding answers to questions like “What is the LIBOR rate?” from a given contract document. We start by extracting the relevant top-N (top-ranked) candidate paragraphs for the given question from the provided contract document using keyword-based queries. This can be achieved by open-source tools such as Elasticsearch or Solr. These paragraphs can then be passed to the Bert question-answering model to find answers specific to the question.
Source: https://cogitotech.medium.com/sentiment-analysis-how-it-works-types-everything-you-need-to-know-822a1f2ddeaf
Sentiment Analysis
Sentiment analysis is the study of identifying the emotions attached to the given text. These emotions give additional information about the attitude of the writer of the text towards the object of the text. These emotions can be of various types – positive, negative, neutral, angry, happy, sad, etc. The intensity of these emotions is determined by a polarity score, which is beyond the scope of this study.
As seen in the cover image (at the top), sentiment analysis is generally carried out using:
1. Knowledge-based systems
2. Statistical systems
3. Hybrid approaches
4. Classification
Knowledge-based systems: These systems typically employ grammar, syntax, and word-meaning rules as a knowledge dictionary to construct hand-crafted features for the dataset. These features can then be used to build an NLP classifier for categorizing the text into target sentiments.
Statistical systems: These systems employ statistical measures to construct features while training. Statistical features include uni-gram, bi-gram, and tri-gram probability statistics and word embedding in a multi-dimensional vector space associated with a given target sentiment. These statistical features can then be used to build a probabilistic model to predict the sentiment for the given text.
Hybrid approaches: These approaches combine hand-crafted features with statistical features, which can then be used to train a Machine learning model as an NLP classifier.
Classification: This step usually involves a machine learning classifier trained on the given text data and used to predict the test data.
Sentiment Analysis Workflow
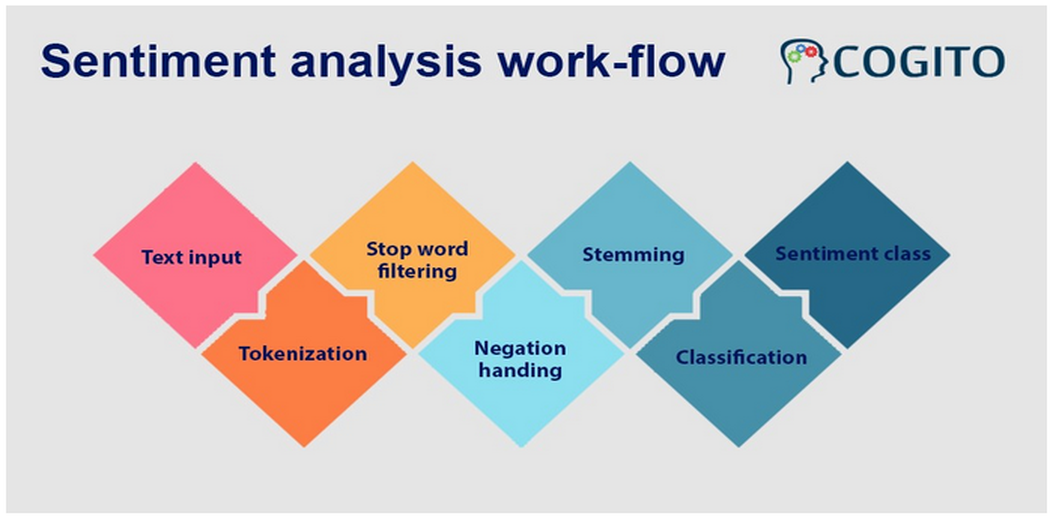
The typical workflow for the sentiment analysis task is depicted in the figure below. The various steps are:
Text input: This step involves ingesting text for the sentiment analysis application. The text can be obtained by Optical character recognition techniques when applicable, e.g., when *PDF and image files are uploaded.
Tokenization: Tokenization involves splitting the text into individual words or tokens.
Stop word filtering: This phase removes frequently occurring words in the English language as they do not provide distinguishing features to the text being analyzed.
Negation handling: This phase involves finding negations and reversing the polarity of the words in the vicinity. For E.g. “I am not happy today” can be misconstrued as a positive sentiment-bearing sentence. So we detect the negation token “not” and reverse the polarity of all (3 to 6) the words in its neighborhood.
Stemming: Stemming involves finding the root of the tokens in the given text. This is achieved by removing the last few alphabets in the word, e.g., “representation” and “represented” will be converted to “represent.” Stemming can result in words without meaning, too, e.g., “analysis” and “analyze” can result in “analysis.”
Classification: We convert the tokens obtained from the preprocessing steps to feature vectors. These feature vectors are then used to build a machine learning classifier to classify the text as either positive or negative.
Sentiment class: The output obtained from the classification step is input in downstream tasks.
Source: https://cogitotech.medium.com/sentiment-analysis-how-it-works-types-everything-you-need-to-know-822a1f2ddeaf
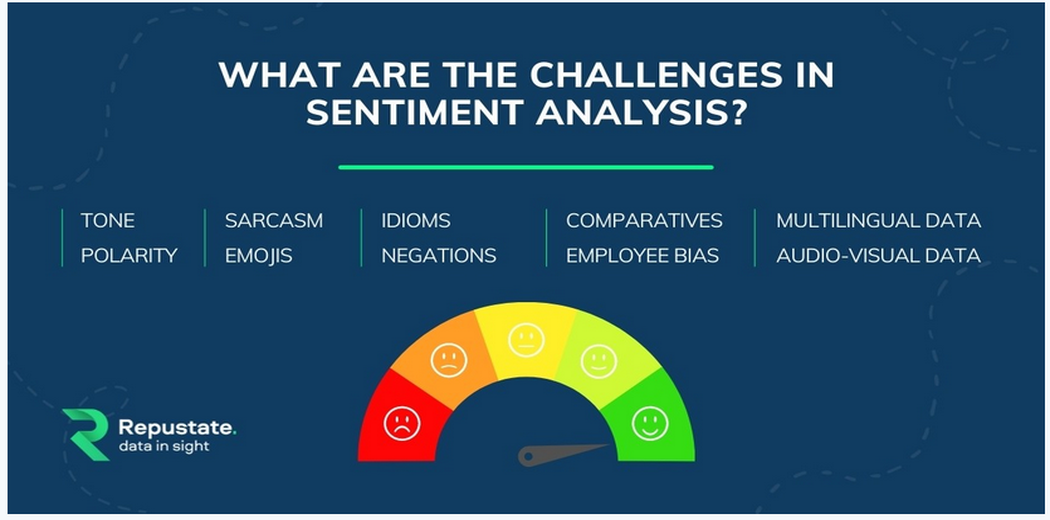
Challenges in Sentiment Analysis
As seen in the figure below, the challenges in sentiment analysis are:
Tone: The text can contain an underlying emotion of the author, e.g., anger, sadness, etc. This expression will not be explicit in general and usually involves reading the subtext. This is called the text’s tone and requires thorough training on sufficient data of a good quality to model the behavior in sentiment analysis software.
Polarity: Sometimes, the polarity (positive, neutral, or negative sentiment) of a sentence is context-dependent. E.g., “I like ice-creams” is positive for most people, while the same sentence is negative for older people. Identifying polarity and, thus, the sentiment becomes challenging in such context-dependent scenarios.
Sarcasm: Sarcastic comments are difficult to comprehend for human beings too. Such text is difficult to handle for sentiment analysis software.
Emojis: Emojis in a text convey the emotions the author feels towards a topic and the emotions the author wants to convey to the reader. Purely text-based methods can fail to analyze these sentiments.
Idioms: Authors use idioms to convey a meaning different from the meanings of the individual words. Such text elements need context-dependent analysis and are challenging to handle in sentiment analysis software.
Negations: As discussed earlier, negations change the polarity of the words in their vicinity. Provisions should be made for negation handling in Sentiment-analysis software.
Comparatives: Comparatives are used to compare two or more objects, and the sentiment analysis model needs to know the root words and their comparative forms and usage.
Bias: Bias may be introduced in the system while annotating data for training purposes and making assumptions in formulating the ML model for sentiment analysis.
Multilingual data: Multi-lingual data is common in English language text. Such data should be handled carefully in sentiment analysis software. An example of multi-lingual data is “joie de vivre” in English language sentences.
Audio-visual data: Audio-visual data is used by authors to communicate their feelings about a topic to the reader. Examples include GIFs, images, videos, etc. It is challenging to handle such data in sentiment analysis software. However, such data can be handled with the advancement of multi-modal modeling techniques (e.g., coupled text-image analysis).
Source: https://www.repustate.com/blog/sentiment-analysis-challenges-with-solutions/
Conclusion
This brings us to the end of the article. We started by introducing the IMDb movie reviews dataset for sentiment analysis. The dataset contains 25000 positive and negative reviews in the train set and 25000 positive and negative reviews in the test set.
We introduced Natural language processing and studied the five prominent use cases in NLP viz Machine translation, Information retrieval, Sentiment analysis, Information Extraction, and Question Answering.
Next, we studied the theory behind sentiment analysis and the approaches used in solving the sentiment analysis problem. The commonly used approaches are knowledge-based, statistical, and hybrid. These approaches involve a classification step.
We concluded the article by studying the sentiment analysis workflow and the challenges faced in building sentiment analysis software.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Arvind N
04 Sep, 2022







