Demystifying NoSQL: Your Complete Interview Guide
This article was published as a part of the Data Science Blogathon.
Introduction
In data science, learning about databases is inevitable. In fact, as a data science expert, you have to learn how to work with databases, run queries quickly, and more. There is no way around it!
He has two things to know. Learn as much as possible about database administration and understand how to approach it efficiently. Trust me; you’ll come a long way in data science. Data engineers must work with all databases, especially SQL and NoSQL. But most of us already have a fair amount of experience with SQL databases. Where we stumble is when we need to move to a NoSQL database. It can be a little confusing at first. Getting started is always the hardest step.

(Source: src)
This article describes the essential differences between these two types of databases to clear this roadblock. This will give you two overviews and make it easier to start your journey. Let’s start
Interview Question on NoSQL
1. What do you understand and know about NoSQL in databases?
Contrary to the literal translation of the meaning, NoSQL stands for “Not Only SQL.” It is a new way of thinking about databases, which can handle many structured, semi-structured, and complicated data. It refers to various database technologies created in response to increased data being saved about individuals, things, and goods. Performance and processing requirements, as well as the frequency of access to this data. Contrarily, relational databases were not created to handle the size and agility issues that plague modern applications, nor were they meant to benefit from the affordable storage and processing power available today. So the main target of NoSQL is to create an alternate database in SQL -where textual data can be stored easily in a less-structured manner.
2. What are the features and advantages of NoSQL?
Unlike RDBMS, NoSQL is far more easily scalable and provides superior performance. Additionally, it helps address the issues that RDBMS failed to address:
- NoSQL is capable of handling large amounts of structured, semi-structured, and unstructured data
- OOPs can easily be used and integrated with NoSQL
- Provides efficient scale-out architectures while RDBMS mainly operates on monolithic architectures
- It provides agile sprints, and the iterations are quick because the in-memory caching option is available to increase the performance of queries.
- It provides good support for Analytic tools on top of Bigdata
- It is capable of being hosted on cheaper hardware machines
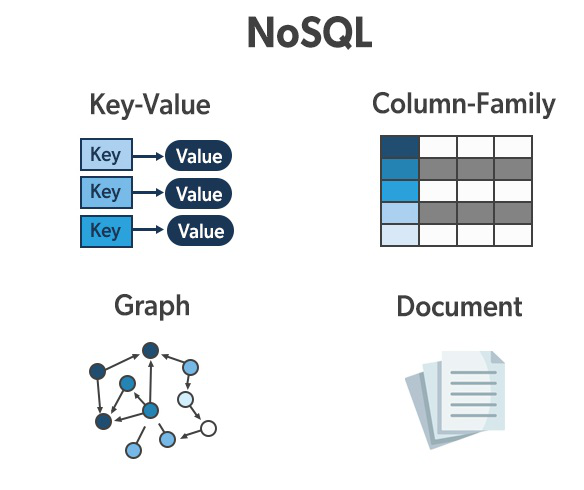
3. What are the different types of databases available under NoSQL?
NoSQL databases come in the following types:
- Document Oriented DB – One of the characteristics of the NoSQL database is this. The data should be stored without schema. As a result, scalability will be higher, and JavaScript object notation will be used. The job will be completed more quickly and for less money. Example -MongoDB
- Key-Value Stores – The data is often stored in tables in the RDBMS database, while hash tables are used in NoSQL to store data. Each of these tables has its own identity. Working with a key-value store is preferable to utilizing joins if you are looking for data. This key value will retrieve data from the hash table more quickly. Examples – Riak, Voldemort, and Redis.
- Graph DB – A graph database is one of the most crucial databases in NoSQL. It is primarily tailored for navigating and storing data relationships. Edges will contain data relationships, and the idea is entity information. Banks, social media, new channels, etc., use this database. Example – Neo4J and HyperGraphDB.
- Column Oriented Stores- This gives NoSQL much more flexibility. Keyspace is a concept in column databases that functions somewhat similarly to a relational model’s schema. All column families are contained in this keyspace, which in turn comprises rows and columns. It takes a little while to get your head around, but it’s not too difficult. Example -Cassandra and HBase.
4. What is the difference between Vertical and Horizontal Databases?
|
|
| The physical layout of data is column by column. Vertical ScalingScalingus be added, thereby adding more power to the PC. | The physical layout of data is row by row. Thus horizontal scaling is achieved, thereby adding more equipment. |
| All data is stored in a single node. | Only part data is stored in all nodes. |
| Multi-core scaling will be done. | Single-core scaling done. |
| Example – Amazon Cloud | Example – MongoDB |
5. What do you understand by Polyglot Persistence in NoSQL?
The term “Polyglot Persistence” is used to represent the notion that applications ought to be written in a variety of languages. As is common knowledge, difficulties can occur in every application. Therefore, when an application is written in various languages, those languages can be used to address or solve multiple issues. The term “polyglot persistence” describes this. Instead of encompassing all facets of a problem in a single language, choosing the appropriate language for that situation can be more beneficial. Therefore, this hybrid approach to Persistence is referred to as polyglot Persistence.
Polyglot Persistence suggests that database engineers/architects should determine how they want to manipulate the data and then choose the database technology that best suits their needs. This approach solves data storage efficiency problems, simplifies operations, and eliminates fragmentation.
6. When should NoSQL be used over RDBMS?
You can utilize NoSQL if you seek key-value stores with extremely high-performance levels because ACID transactions are used in relational databases. The schema-based process will slow down the database performance once we employ this transaction.
Possible scenarios of potential usage of NoSQL are:
- In situations of the need for multiple JOIN queries
- For high-traffic websites
- While using denormalized data
7. Explain the CAP theorem in NoSQL.
It is the most reliable of the three guarantees for a NoSQL database. CAP is the fundamental value of consistency, availability, and partition tolerance. The nodes will be working in tandem in the network. As a result, the entire functioning of the database will work faster.
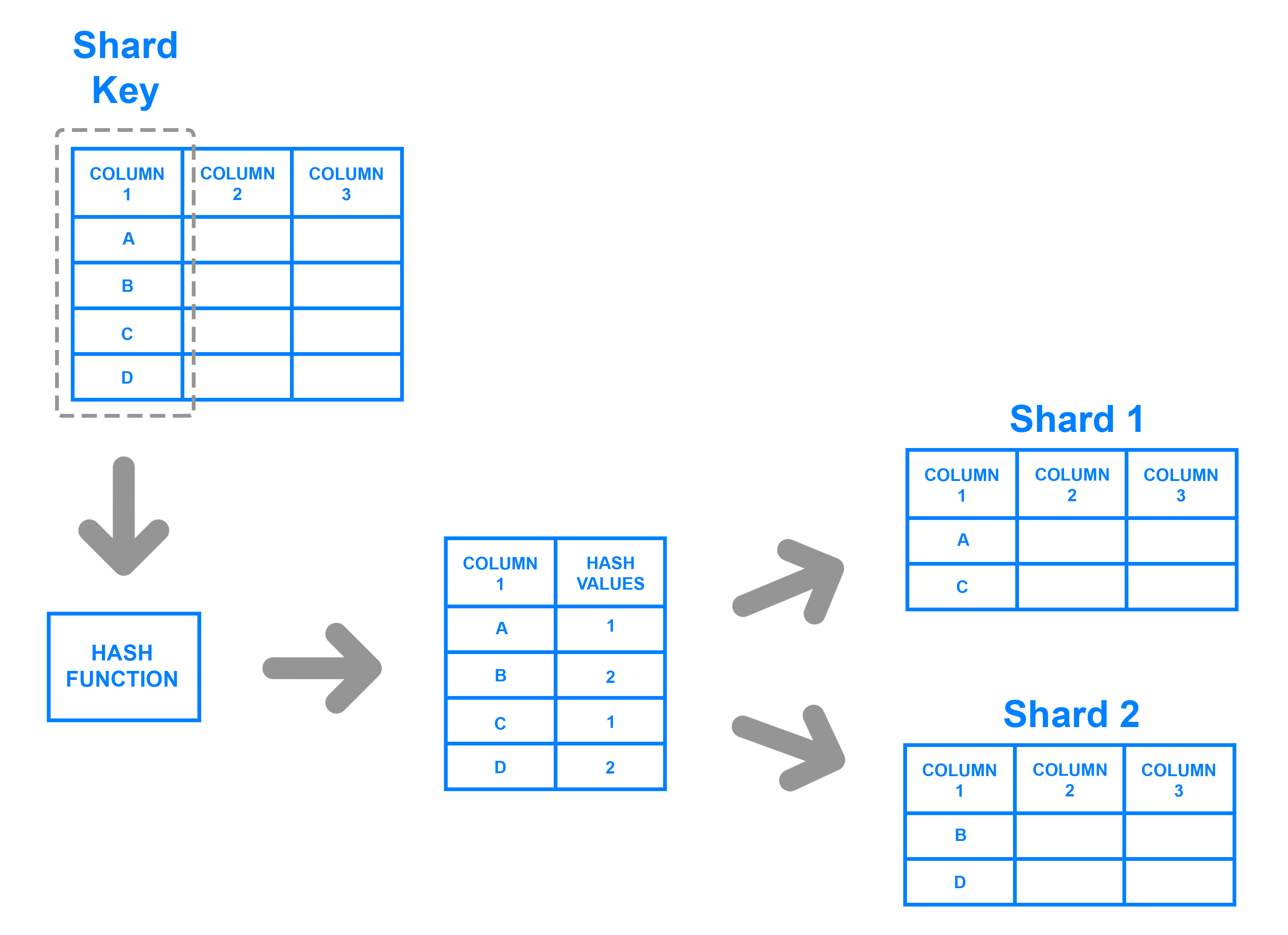
8. What is understood by Database Sharding in NoSQL?
Database sharding in NoSQL refers to splitting the database according to NoSQL time-appropriate patterns. Data can be stored by sharding over numerous, possibly independent servers worldwide. A database administrator can readily retrieve this data from anywhere in the world with excellent data speed characteristics.
9. What are the ways to track data record relations in NoSQL?
The possible steps are as follows:
- Embed all data into any user-object
- Create the user-id credential
- Using the login id, you will be needed to give the value of the comments with a list of comments.
- Following these three steps will lead to the desired information retrieval.
10. Explain the BASE Characteristic of NoSQL.
The BASE model, which is a softer approach, is used by NoSQL. The BASE stands for Basically Available, Soft state, Eventual consistency.
- Available: Assures the data’s accessibility. Any inquiry will receive a response (it can be a failure too).
- Soft state: Over time, the system’s state might change.
- Eventually Consistent – It assumes that once it stops accepting input, the system will finally achieve consistency.
NoSQL databases sacrifice the A, C, and D requirements for greater scalability.
Conclusion
Throughout the ten questions, we have covered the essential concepts of NoSQL as a DBMS. Key takeaways from today’s blog include –
- The general idea of NoSQL and why it originated and came into popularity
- The key features and different types of databases in NoSQL
- Key concepts like Polyglot Persistence, CAP Theorem, Database Sharding
- When you should be using NoSQL over the existing RDBMS
- The BASE characteristics of NoSQL over ACID characteristics of RDMBS
If thoroughly well versed with the above ideas and questions will surely give you an edge in the interview. Hope you liked today’s topic of discussion and you managed to add new concepts to your existing knowledge. Wishing you great luck with your future goals and aspirations!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







