Most existing research on Twitter spam focuses on account blocking or identifying and blocking spam users or spammers. To detect spam users, we can use traditional machine learning algorithms that use information from users’ tweets, demographics, shared URLs, and social connections as features. Social networks have become popular as a tool for internet users to communicate with friends and family, read news, and discuss current events. Users spend more time saving and sharing their personal information on well-known social platforms (e.g., Facebook, Twitter, etc.).
What is Natural Language Processing?
Natural Language Processing is a computer science approach to understanding natural language. The field of language processing is the study of human language and communication in various forms. The area includes systems that take input and transform the information into the desired output. It can range from a simple tool like Spam Detection to more complex programs like Google Translate. Google Translate is a translation algorithm that uses a set of input languages to generate a translation of the input.
Source – searchenginejournal
In this article, we will discuss how we can make a spam text detector to detect the spam messages which are flooded on various social media platforms like Twitter. We use famous machine learning classification algorithms, such as Support Vector Machines (SVM) and different Naïve Bayesian (NB) techniques, to evaluate the proposed characteristics.
Natural Language Processing Pipeline
We will follow the below pipeline, which includes the loading and preprocessing of the Dataset, model training, testing, etc.:
1. We will create a Semi-supervised learning Naive Bayes Support Vector Machine model to classify spam tweets.
2. Clean & Preprocess data (in this case, tweets dataset) obtained from Kaggle. Preprocessing involves the seven stages of natural language processing.
3. Pictorial/Graphical representation of this Data.
4. Vectorize the preprocessed data so that we can apply various machine learning algorithms to the data.
5. Calculate various error measurement parameters like F1-Score, Accuracy, etc., and depict these in the form of confusion matrices.
6. Conclude the best algorithm based on the previously calculated error measurement parameters.
7. Apply the final algorithm over live tweets on Twitter using API.
Experiments on a large dataset suggest that the system adapts to new spam patterns and maintains high accuracy for spam identification in a Twitter stream without constantly updating the semi-supervised model’s corpus. However, we can discover by the time a rogue user may have infected many additional users. We feel that spam detection at the tweet level complements spam detection at the user level. We employed a simple strategy to deal with user-level spam detection due to the minimal user information in our data set.
Past Literature Survey
This section will discuss past papers on Natural Language Processing techniques, their findings, limitations, future scope, etc.
Paper-1
Title:
Semi-Supervised Spam Detection in Twitter Stream (IEEE Explore 2017)
Findings:
It offers S3D, a semi-Supervised spam detection framework, in this paper. S3D uses four lightweight detectors to detect spam tweets in real-time and regularly update the models in batch mode. The experiment’s findings show that our spam detection framework works well with a semi-supervised technique. They discovered that the method is excellent at capturing novel spamming trends when clusters and tweets are confidently identified.
Limitations:
Spam detection at the tweet level is an acceptable-grained method for detecting spam tweets in real-time. However, only we can glean so much information from a single tweet. On the other hand, we can obtain more discriminative traits from a user’s account, historical tweets, and social graphs. However, when a rogue user is discovered, they may have infected many additional users.
Future Scope:
Although tweet-level spam detection may work in tandem with user-level spam detection, they employed an essential strategy to cope with it due to the low user information in their Dataset. Nonetheless, we could argue that we can implement user-level spam detection can be implemented into S3D, which we’ll be working on in the future.
Paper-2
Title:
Spam Detection in Twitter Stream (IJSDR Paper 2019)
Findings:
In this spam detection framework, the experiment shows that the offered outcome strategy of semi-supervised is effective. We discovered that mining data makes a simple concept for detecting spam tweets on Twitter. It also consists of confidently labeled clusters and tweets, making the system effective in capturing new spamming patterns. The Porter Stemmer algorithm can also represent the social graph for spam detection on Twitter.
Limitations:
A fine-grained method for detecting spam tweets in real time is spam detection at the tweet level. A single tweet, on the other hand, can only provide so much information. On the other hand, a user’s account, history of tweets, and social graph can provide more discriminative qualities. By the time a rogue user is found, however, they may have infected many other users.
Future Scope:
Although it’s feasible that spam detection at the tweet level will function in tandem with spam detection at the user level. Due to the limited user information in their Dataset, they used a simple technique to deal with user-level spam detection. However, we could argue that we can include user-level spam detection in S3D, which we’ll be pursuing in the future.
Paper-3
Title:
A Neural Network-Based Ensemble Approach for Spam Detection in Twitter (IEEE Xplore 2018)
Findings:
This paper presents a neural network-based ensemble strategy that combines deep learning and classic feature-based algorithms to detect spam at the tweet level. They used CNN to explore multiple-word embeddings. The suggested technique outperforms all existing methods for the 1KS10KN and HSpam data sets. When applied to many unseen tweets, even the model trained with a small number of instances performed admirably. The proposed strategy’s performance was superior to the baseline methods in all experiments.
Limitations:
Feature-based methods perform poorly compared to deep learning approaches for the HSpam14 data set. The inputs for deep learning-based algorithms were simply tweets with no further information. It would be fascinating to explore if we may enhance the deep learning methods’ performance further by considering other information about the tweets or their authors.
Future Scope:
Feature-based algorithms perform poorly compared to deep learning approaches for the HSpam14 data set. They could develop a better strategy to convey the Data’s characteristics. Tweets with No further information were used as inputs for deep learning-based systems. It would be fascinating to see if the effectiveness of deep learning algorithms could be improved even more by including additional information about the tweets or their writers.
Paper-4
Title:
Detecting spam accounts on Twitter (IEEE Xplore 2018)
Findings:
The following are the main contributions of this paper in summary. They created a collection of innovative graphs and content-based characteristics that effectively detect spam accounts on Twitter. Then detect spam and valid users using seven machine learning algorithms: K-nearest Neighbor (kNN), Decision Tree (DT), Naive Bayesian (NB), Random Forest (RF), Logistic Regression (LR), Support Vector Machine (SVM), and extreme Gradient Boosting (XGBoost). The top 10 most impacting detecting features among all the features employed by state-of-the-art techniques were then ranked using the feature ranking method (i.e., information gain).
Limitations:
In their paper, they created a new and more robust set of features to detect spammers on Twitter. They used seven distinct machine learning algorithms to incorporate both graph-based and tweet content-based information. Random Forest (RF) outperforms the other algorithms in the trial, with an accuracy of 91 per cent, a precision of 92 per cent, and an F1 score of 91 per cent. The performance comparison analysis revealed that the proposed strategy is viable and capable of producing even better outcomes than other state-of-the-art alternatives.
Future Scope:
A more effective model that can quickly classify various sorts of spammers within multiple social networks could be developed in the future. We will also improve machine learning algorithms and apply our technology to various social networks.
Methods Used for Natural Language Processing
Preprocessing: Each Data needs cleaning, like removing redundant variables (variables that do not contribute to the target variable). Then this phase also includes the removal of eradicating duplicates or erroneous values. (eg. ‘Python,” python,” python3.6’,etc. are all in the same categories).
Then further preprocessing of data includes creating N-Gram models, stemming, and Vectorization.
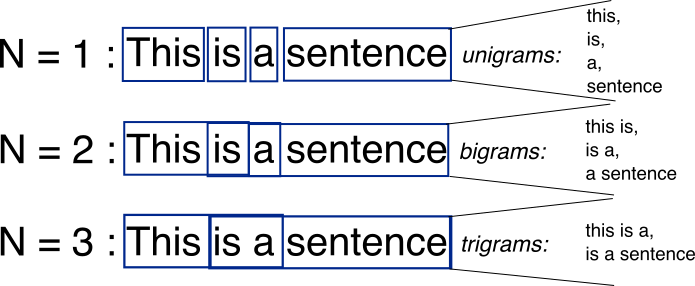
N-Gram Models: Statistical language models, in their most basic form, are models that assign a probability to word sequences. This post will look at the n-gram, the most basic model for assigning probabilities to sentences and word sequences.
Source – deepai.org
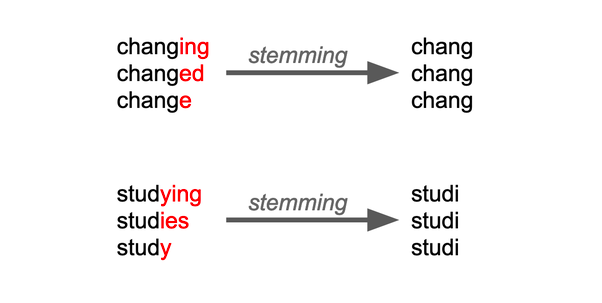
Stemming: The process of developing morphological variants of a root/base word is known as stemming. Stemming algorithms or stemmers are terms used to describe stemming programmers. The phrases “chocolates,” “chocolatey,” and “choco” are reduced to the root word “chocolate,” and “retrieval,” “retrieved,” and “retrieves” are reduced to the stem “retrieve.” In natural language processing, stemming is integral to the pipelining process. Tokenized words are fed into the stemmer.
Source – quora
Vectorization: Vectorization is a jargon term describing a traditional method of turning raw Data (text) into vectors of real numbers. This format is what machine learning models allow. This approach has been used since the start of computing, has proven effective in various disciplines, and is currently being applied in natural language processing. Vectorization is a phase in feature extraction in Machine Learning. The goal of translating text to numerical vectors is to extract some identifiable features from the text for the model to learn.
Source – towardsdatascience.com
Exploratory Data Analysis: This phase divides the data into appropriate data frames based on a particular attribute of the data. This part includes showcasing ‘spam’ & ‘ham’ words in the form of word clouds.
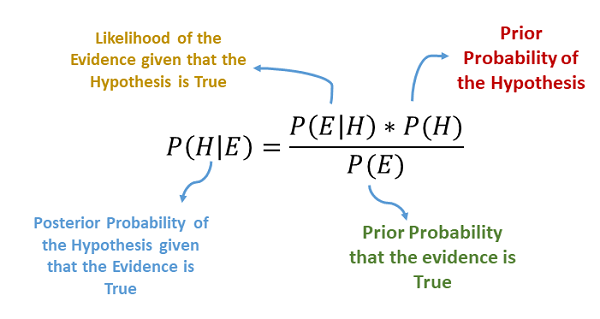
Naive Bayes: Bayes’ Theorem is a famous classification algorithm with an assumption of independence among predictors. In layman’s language, a Naive Bayes classifier assumes that a particular feature in a class is unrelated to the other parts. This theory provides a method of calculating posterior probability P(c|x) by using P(c), P(x), and P(x|c).
Source – medium.com
The below equation justifies it:
Above,
● P(c|x) is the posterior probability of class (c, target) given predictor (x, attributes).
● P(c) is the prior probability of class.
● P(x|c) is the likelihood which is the probability of the predictor given class.
● P(x) is the prior probability of the predictor.
So for naïve bayes we have employed two variations of naïve bayes:
▪ Multinomial naïve bayes
▪ Bernoulli naïve bayes
Source – analyticslearn.com
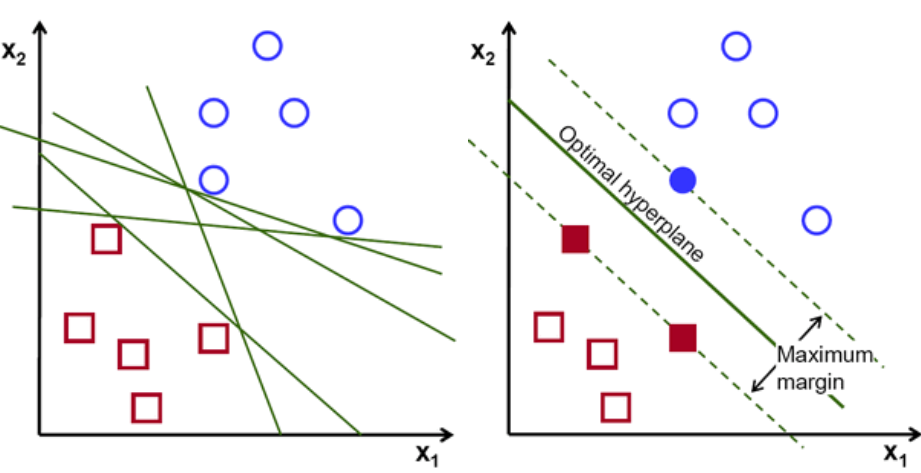
Support Vector Machines: Support vector machine is another simple algorithm every machine learning expert should have in their arsenal. Support vector machine is much preferred. It gives high accuracy even using low computational resources. SVMs can be used for regression and classification tasks. But mainly in classification tasks.
The main motto of this algorithm is to find a hyperplane in N-dimensional space (N — the number of features) that distinctly classifies the data points. We can choose many possible hyperplanes to separate the two data points classes. The algorithm’s objective is to find a plane with the maximum margin, i.e., the maximum distance between data points of both types. Maximizing the margin distance reinforces sous to classify future data points more confidently.
Source – towardsdatascience
Error Measurement
In this section, we will discuss the performance parameters like accuracy score, recall score, etc. Error Measurement is the difference between the observed value and the true value of that variable.
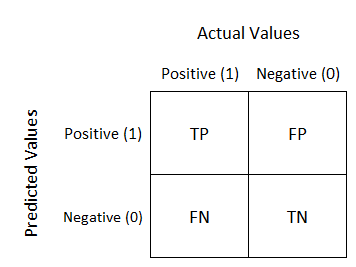
True-Positive: Predicted is positive, and it’s true
True-Negative: Predicted is negative, and it’s true
False-Positive: Predicted is positive, but it’s false
False-Negative: Predicted is negative, but it’s false
Precision: How many of the positive classes that we accurately predicted are positive?
We first send the data to a top-notch model after cleaning, preprocessing, and organizing it, and we naturally get output in probabilities. Keep going, however! How will we assess the effectiveness of our model? Higher energy equates to better performance, and better performance is what we want. The Confusion matrix now assumes a prominent position. A classification performance matrix is the Confusion Matrix. It’s a performance categorization issue with output from two or more classes. This table contains four separate sets of anticipated and actual values.
Source – towardsdatascience.com
Implementation
1. Importing Necessary Libraries:
We will import all the necessary used in this project. It includes Pickle, Pandas, NumPy, SVC, etc.
import pickle as pk
import pandas as pd
# Numpy library to perform various complex mathematical calculations.
import numpy as np
import tweet_catch as tc
# Matplotlib library to draw various plots.
import matplotlib.pyplot as plt
import seaborn as sns
import ps_preprocess as pp
import warnings
# Library to draw the Word Cloud.
from wordcloud import WordCloud
# All Sklearn Related Libraries.
from sklearn.naive_bayes import MultinomialNB, BernoulliNB
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import metrics
from sklearn.metrics import accuracy_score
2. Read & Pre-Process Dataset:
Firstly, we will read the dataset using the read_csv() function of the Pandas library. After that, we will showcase and visualize the dataset. Further, we will create offsets of tweets for training and testing purposes. We will use 80% of our data for training and the remaining 20% of the data for testing. Finally, we will separately visualize the training and testing data.
The complete code for training and pre-processing of the dataset can be found here.
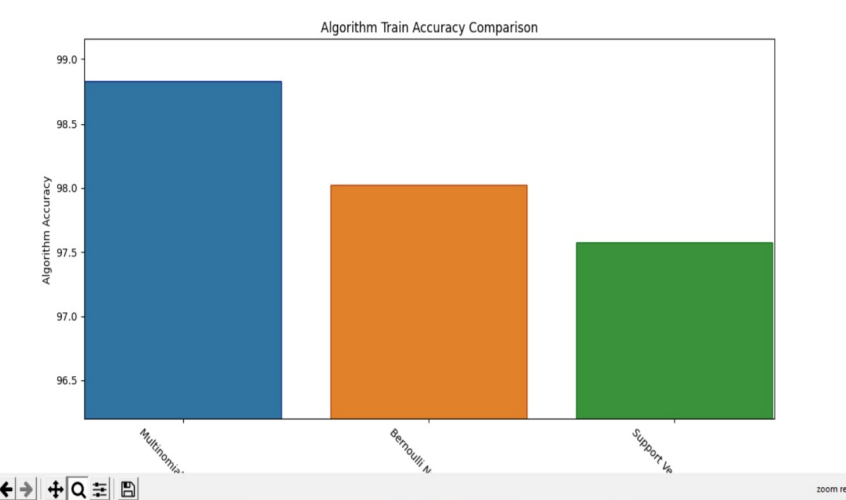
3. Training of Model: This section will see the code used to train our models. We will train our dataset on Multinomial Naive Bayes, BernoulliNB, and Support Vector Machine. In the next section, we will also find the model which gives our best accuracy and precision.
Plotting the Word Clouds for Spam and Normal Messages: A word cloud is a graphical representation of the frequency of words used in a document. The more often a word appears in the document, the larger it is displayed in the word cloud. Word clouds, such as topic modelling, are often used to visualize text analysis results.
The advantages of using word clouds for text analysis are that they can be generated quickly and easily and provide a good overview of the essential topics in a document. The disadvantages of word clouds are that they can be challenging to interpret, and they may not be able to capture all the nuances of a document.
4. Plotting the Graphs: Now, we will plot the graphs of the Accuracy Score and Confusion Matrix for the MNB Classifier. We will use the famous matplotlib library to plot all the required graphs.
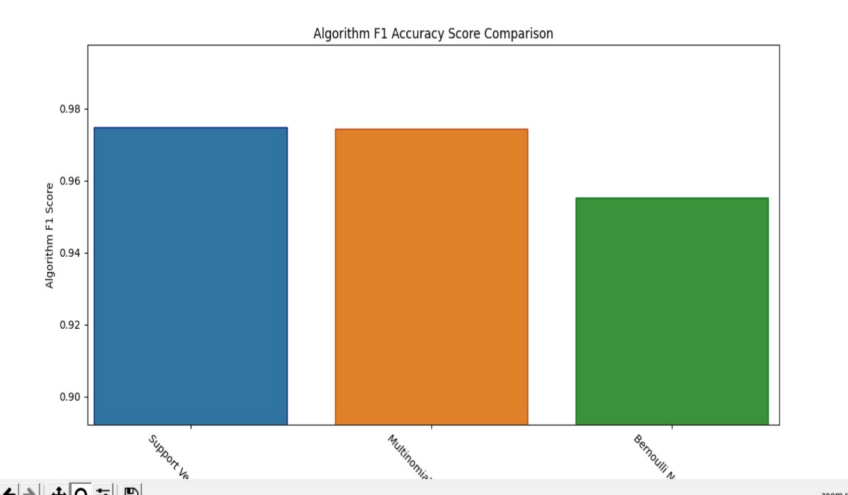
Below we will plot the graphs of the Training Accuracy Score and F1 Score comparison of all three algorithms.
In predictive modelling, accuracy and F1 score are two of the most commonly used metrics. But what do they mean?
Accuracy is the proportion of correct predictions out of all the predictions made.
It’s a good metric, but it can be misleading.
F1 score is a measure of a classifier’s accuracy. It considers both the precision and the recall of the classifier. Precision is the number of correct positive results divided by the number of all positive results, and recall is the number of correct positive results divided by the number of positive results that should have been returned.
Conclusion
Preprocessing the data effectively to include all the relevant sources of spam, as we observe in the case of opinion mining and sentimental analysis where the algorithm gets tricked due to non-identification of These inbuilt parameters and features that social media sites provide due to which the accuracy of any Classifier suffers.
Using N-gram models, stemming, and vectorization further increases the quality of the classifier built to detect malicious and non-malicious data separately. Among all the classifiers we made, the best accuracy was obtained using the multinomial naïve Bayes gives the best accuracy as it employs the use of multiple features, which is the case in any generic malicious dataset taken.
Key takeaways of this article:
1. Firstly, we discussed the basic understanding of Natural Language Processing, its importance, and its main advantages.
2. We have discussed several research papers on natural language processing for Text Analysis from various organizations. The articles we have discussed are on the topics of different spam detection methods on the Twitter dataset.
3. Then, we discussed the code, which includes loading and pre-processing the dataset, and then training several machine learning models. Finally, we have visualized various performance parameters like Accuracy Score, Confusion Matrix, etc.
This is all for today. Thanks for reading.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A verification link has been sent to your email id
If you have not recieved the link please goto
Sign Up page again
Loading...
Please enter the OTP that is sent to your registered email id
Loading...
Please enter the OTP that is sent to your email id
Loading...
Please enter your registered email id
This email id is not registered with us. Please enter your registered email id.
Don't have an account yet?Register here
Loading...
Please enter the OTP that is sent your registered email id
Loading...
Please create the new password here
We use cookies on Analytics Vidhya websites to deliver our services, analyze web traffic, and improve your experience on the site. By using Analytics Vidhya, you agree to our Privacy Policy and Terms of Use.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.