Introduction
Transformers are foundational models that brought a massive revolution in the AI domain. The sheer scale and purview of foundation models in recent years have outpaced our expectations for what is feasible. Given this, it is imperative to prepare this topic thoroughly and have a firm grasp of its fundamentals.
I’ve put together six interview-winning questions in this article to help you become more familiar with the transformer model and ace your next interview!
This article was published as a part of the Data Science Blogathon.
Common Interview Questions on Transformer
The following are the questions with detailed answers.
Q: What are Sequence-to-Sequence Models? What are the Limitations of Sequence-to-Sequence Models?
A: Sequence-to-Sequence Models: Sequence-to-Sequence (Seq2Seq) models are a type of model which takes an input sequence to generate an output sequence. It is a Recurrent Neural Network used for tackling various NLP tasks like Machine Translation, Text Summarization, Question Answering, etc.

Figure 1: Some examples of Sequence-to-sequence tasks (Source: Analytics Vidhya)
Limitations of the Seq2Seq model: Sequence-to-sequence models are effective; however, they have the following limitations:
- Unable to tackle long-term dependencies.
- Unable to parallelize.
Q: Explain the Model Architecture of the Transformer.
A: Transformer architecture was developed to counter the limitations of the Seq2Seq model, which uses an attention mechanism and repetition to handle the dependencies between input and output.
Figure 1 illustrates Transformer architecture which uses stacked self-attention (for computing representations of inputs and outputs), point-wise, and fully connected feed-forward layers for both the encoder and decoder.
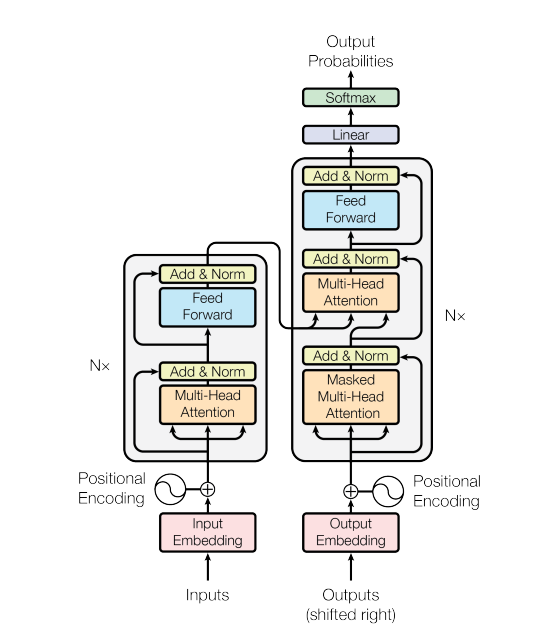
Figure 2: Transformer Architecture (Source: Arxiv)
Let’s take a look at Encoder and Decoder components individually to have more clarity:
Encoder: The encoder consists of a stack of 6 identical layers, each of which has two sub-layers. Sub-layer1 = Multi-head self-attention, and Sub-layer2 = point-wise fully connected feed-forward network (FFN).
A residual connection followed by layer normalization is used around each sub-layers.
The output of each Sub-layer = LayerNorm(x + Sublayer(x))
All sub-layers, along with the embedding layers, generate outputs of dimension (dmodel) = 512 to help with the residual connections.
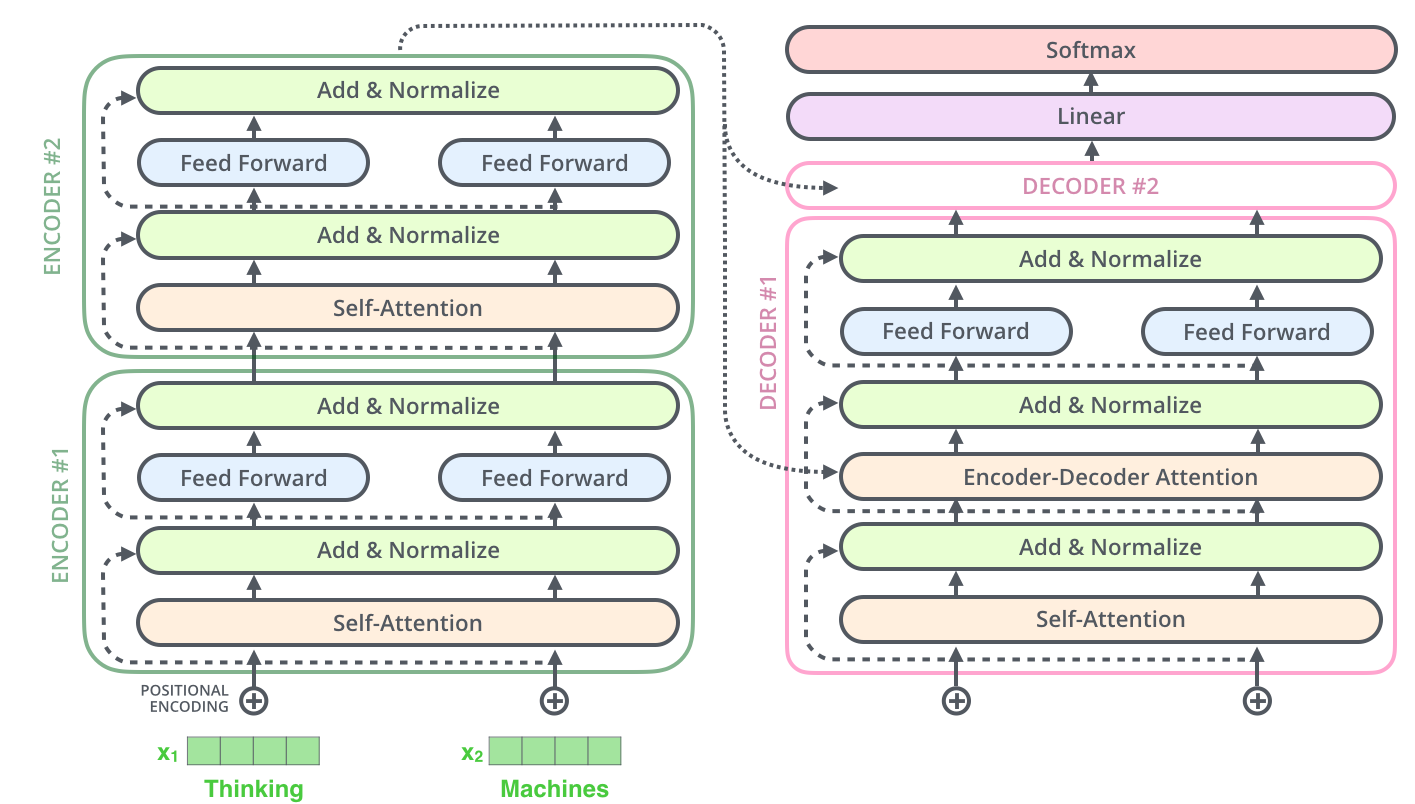
Figure 3: Simplified Transformer Architecture by Jay Alammar. Notably, the encoder and decoder comprise six identical layers (i.e., N=6)
Decoder: Just like the encoder, the decoder also comprises a stack of six identical layers, however besides the two sub-layers in each encoder layer, the decoder employs a third layer that executes multi-head attention on the encoder stack output.
In addition, much like the encoder, the decoder uses residual connection followed by layer normalization around each sub-layers.
Furthermore, the self-attention sub-layer layer is modified in the decoder stack to prevent positions from paying attention to succeeding positions. In this regard, the masking, in addition to output embeddings being offset by one position, ensures that the predictions for position “i” are based on the outputs known to have occurred at positions lower than i. Notably, this is implemented inside the scaled dot product attention. In essence, the leftward information flow is restricted to retain the autoregressive property of the decoder.
In short, the whole process of encoding and decoding can be summed up as follows:
- Step 1: The first encoder receives word input sequences.
- Step 2: Then, the inputs are reshaped and transmitted to the next encoder until the last encoder.
- Step 3: After that, the last encoder in the encoder stack produces an output.
- Step 4: Following that, the output from the last decoder is fed to other decoders in the stack.
Q: What is Attention Function? How scaled Dot Product Attention is calculated?
A: Attention Function is mapping a query and a bunch of key-value pairs to an output. It is calculated as a weighted sum of the values, with the weights assigned to each value determined by how well the query matches its corresponding key.
Scaled Dot product: The scaled dot product is computed as follows:
Input = Queries (of dimension dk) + Keys (of dimension dk) + Values (of dimension dv)
The dot products of the query with each of the keys are calculated, then the obtained dot product for each key is scaled down by dividing it by √ dk, and then a softmax function is applied.

Figure 4: Diagram illustrating Scaled-Dot Product Attention (Source: Arxiv)
Practically, the attention function is calculated on a set of queries concurrently, which is packed together into a matrix [Q]. Similarly, the keys and values are packed together into matrix K and matrix V, respectively.
Final attention is computed as follows:

Q: What is the Difference Between Additive and Multiplicative Attention?
A: Multiplicative Attention: Multiplicative (dot-product) attention is similar to the attention we discussed in the above question, except that it doesn’t employ the scaling factor 1/√ dk.
Additive Attention: Additive attention estimates how well the query matches with the corresponding key (i.e., compatibility function) with the help of a feed-forward network (FFN) with
a single hidden layer.
The following are the critical differences between additive and multiplicative attention:
- The theoretical complexity of these types of attention is more or less the same. However, dot-product attention is relatively faster and more space-efficient in practice due to the highly optimized matrix multiplication code.
- For small values of dk , both of these mechanisms perform similarly.
- For large values of dk, additive attention surpasses dot product attention without scaling.
Q: What is Multi-head Attention?
A: Multi-head attention is an extension of single-head attention (or single attention head), which enables the model to jointly attend to the info from various representation subspaces at different positions.
On examination, it was found that employing a single attention function is less beneficial than linearly projecting the queries, keys, and values h times with different learned linear projections.
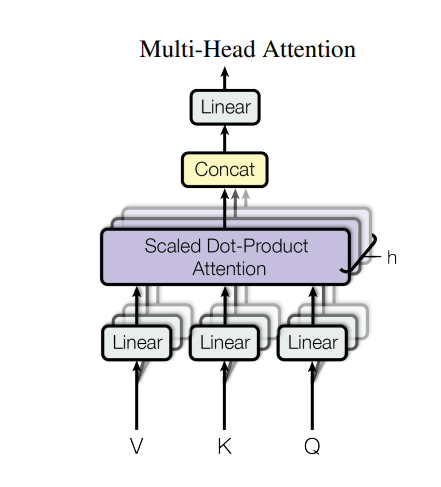
Figure 5: Multi-head Attention (Source: Arxiv)
The attention function is applied concurrently to these projected versions of queries, keys, and values, generating dv-dimensional output values. Figure 5 shows these are then concatenated and projected to obtain final values.

Q: What is the way to account for the order of the words in the input sequence?
A: Given that the transformer neither employs convolution nor recurrence, for the model to use the info related to the order of the sequence, some information about the absolute/relative position of the tokens in the sequence should be injected.
The positional encodings (vectors) are added to the input embeddings at the base of the encoder and decoder stacks (See Figure 6), where they share the same dimension to enable the addition, i.e., dmodel.
It’s worth noting that the positional encodings (vectors) can be learned or fixed. They have a specific characteristic pattern that the model learns, which in turn aids in determining where each word is in the sequence or how far apart the words are from one another. The idea behind this is that including the positional encodings with the input embeddings offers info about the distances between the embedding vectors when they are projected into query/key/value vectors and during dot-product attention.
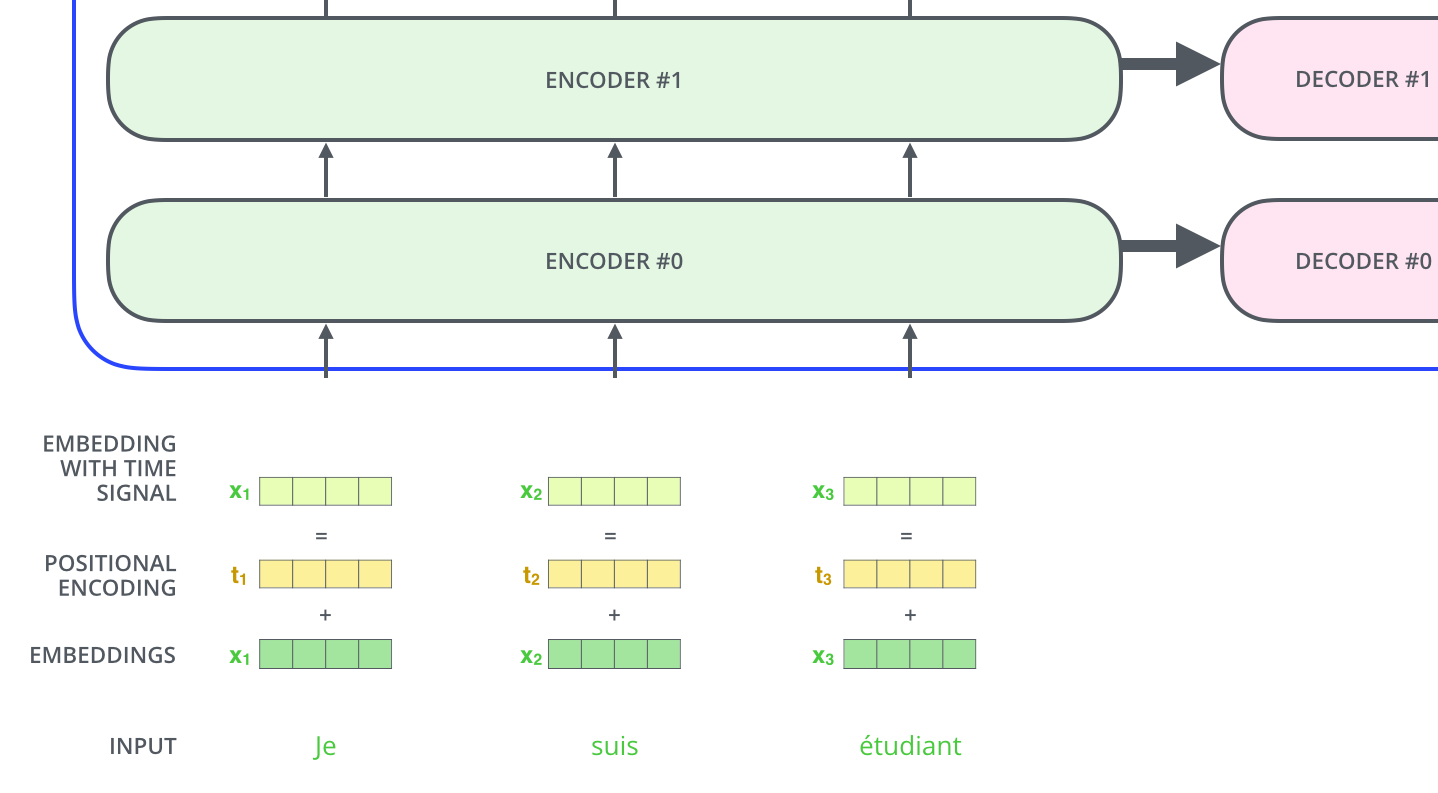
Figure 6: Positional Encodings are added to the input embeddings (Image Credit: Jay Alammar)
Basic Level Questions
Q7: What are Sequence-to-Sequence Models, and what tasks do they address in natural language processing?
A: Sequence-to-Sequence (Seq2Seq) models are a type of Recurrent Neural Network (RNN) used for tasks like Machine Translation, Text Summarization, and Question Answering. They generate an output sequence based on an input sequence.
Q8: What are the limitations of Sequence-to-Sequence Models?
A: Sequence-to-Sequence models struggle with handling long-term dependencies and cannot parallelize effectively.
Q9: Explain the fundamental architecture of the Transformer model.
A: The Transformer architecture employs stacked self-attention and feed-forward layers in both encoder and decoder. It uses multi-head self-attention in the encoder, with residual connections and layer normalization.
Q10: What is the attention function, and how is scaled Dot Product Attention calculated?
A: The attention function maps a query and key-value pairs to an output. Scaled Dot Product Attention involves computing the dot products of queries and keys, scaling them, and applying a softmax function.
Q11: What is the key difference between additive and multiplicative attention?
A: Multiplicative attention uses dot products for similarity, while additive attention employs a feed-forward network. Dot product attention is faster and more space-efficient for large values of dk.
Advanced Level Questions
Q12: Explain the role of positional encodings in the Transformer model.
A: Positional encodings are added to input embeddings to provide information about the absolute or relative position of tokens in a sequence. They help the model understand the order and distance between words.
Q13: What is the significance of multi-head attention in Transformers?
A: Multi-head attention allows the model to jointly attend to information from different representation subspaces at various positions. It enhances the model’s ability to capture diverse patterns in the data.
Q14: How does the Transformer architecture address the limitations of Sequence-to-Sequence Models?
A: The Transformer uses attention mechanisms to capture dependencies effectively, and it employs parallelization for more efficient training. This addresses the long-term dependency and parallelization limitations of Seq2Seq models.
Q15: Discuss the complexity and efficiency differences between dot product and additive attention.
A: Dot product attention is faster and more space-efficient due to optimized matrix multiplication code. Additive attention outperforms dot product attention without scaling for large values of dk.
Q16: Can you outline the steps involved in the encoding and decoding process within the Transformer model?
A: The encoding involves passing input sequences through multiple encoder layers. The decoding includes passing the output of the last encoder to decoder layers. Both encoder and decoder consist of self-attention and feed-forward layers with residual connections.
Conclusion
This article covers some of the most imperative Transformers interview questions that could be asked in data science interviews. Using these interview questions as a guide, you can better understand the concept at hand and formulate effective answers and present them to the interviewer.
To summarize, the following are the key takeaways from this article:
- Sequence-to-Sequence (Seq2Seq) models are a type of RNN model which takes an input sequence to generate an output sequence. These models can’t handle long-term dependencies and can’t parallelize.
- Transformer architecture was developed to counter the limitations of the Seq2Seq model, which uses an attention mechanism and repetition to handle the dependencies between input and output.
- The attention Function maps a query and a bunch of key-value pairs to an output. It is calculated as a weighted sum of the values, with the weights assigned to each value determined by how well the query matches its corresponding key.
- The theoretical complexity of these types of attention is the same. However, dot-product attention is remarkably faster and more space-efficient in practice due to the highly optimized matrix multiplication code.
- Multi-head attention is an extension of single-head attention (or single attention head), which allows the model to jointly attend to the info from various representation subspaces at different positions.
- For the model to use the info related to the order of the sequence, positional encodings (vectors) are added to the input embeddings at the base of the encoder and decoder stacks.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]






