Machine Learning with Limited Data
This article was published as a part of the Data Science Blogathon.
Introduction
In machine learning, the data’s amount and quality are necessary to model training and performance. The amount of data affects machine learning and deep learning algorithms a lot. Most of the algorithm’s behaviors change if the amount of data is increased or decreased. But in the case of limited data, it is necessary to effectively handle machine learning algorithms to get better results and accurate models. Deep learning algorithms are also data-hungry, requiring a large amount of data for better accuracy.

In this article, we will discuss the relationship between the amount and the quality of the data with machine learning and deep learning algorithms, the problem with limited data, and the accuracy of dealing with it. Knowledge about these key concepts will help one understand the algorithm vs. data scenario and will shape one so that one can deal with limited data efficiently.
The “Amount of Data vs. Performace” Graph
In machine learning, a query could be raised to your mind, how strictly is the data required to train a good machine learning or deep learning model? Well, there is no threshold levels or fixed answer to this, as every piece of information is different and has different features and patterns. Still, there are some threshold levels after which the performance of the machine learning or deep learning algorithms tends to be constant.
Most of the time, machine learning and deep learning models tend to perform well as the amount of data fed is increased, but after some point or some amount of data, the behavior of the models becomes constant, and it stops learning from data.
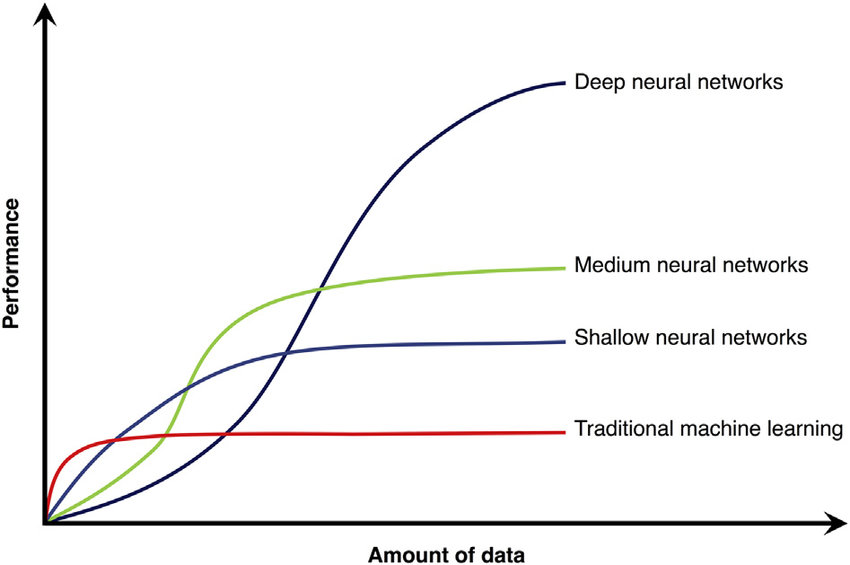
The above pictures show the performance of some famous machine learning and deep learning architectures with the amount of data fed to the algorithms. Here we can see that the traditional machine learning algorithms learn a lot from the data in a preliminary period, where the amount of data fed is increasing, but after some time, when a threshold level comes, the performance becomes constant. Now, if you provide more data to the algorithm, it will not learn anything, and the version will not increase or decrease.
In the case of deep learning algorithms, there are a total of three types of deep learning architectures in the diagram. The shallow ty[e of deep learning stricture is a minor deep learning architecture in terms of depth, meaning that there are few hidden layers and neurons in external deep learning architectures. In the case o deep neural networks, the number of hidden layers and neurons is very high and designed very profoundly.
From the diagram, we can see a total of three deep learning architectures, and all three perform differently when some amount of data is fed and increased. The shallow, deep neural networks tend to function like traditional machine learning algorithms, where the performance becomes constant after some threshold amount of data. At the same time, deep neural networks keep learning from the data when new data is fed.
From the diagram, we can conclude that,
” THE DEEP NEURAL NETWORKS ARE DATA HUNGRY “
What Problems Arise with Limited Data?
Several problems occur with limited data, and the model could perform better if trained with limited data. The common issues that arise with limited data are listed below:
1. Classification:
In classification, if a low amount of data is fed, then the model will classify the observations wrongly, meaning that it will not give the accurate output class for given words.
2. Regression:
In a regression problem, if the model’s accuracy is low, then the model will predict very wrong, meaning that as it is a regression problem, it will be expecting the number. Still, limited data may show a horrifying amount far from the actual output.
3. Clustering:
The model can classify the different points in the wrong clusters in the clustering problems if trained with limited data.
4. Time Series:
In time series analysis, we forecast some data for the future. Still, a low-accurate time series model can give us inferior forecast results, and there may be a lot of errors related to time.
5. Object Detection:
If an object detection model is trained on limited data, it might not detect the object correctly, or it can classify the thing incorrectly.
How to Deal With Problems of Limited Data?
There needs to be an accurate or fixed method for dealing with the limited data. Every machine learning problem is different, and the way of solving the particular problem is other. But some standard techniques are helpful for many cases.

1. Data Augmentation
Data augmentation is the technique in which the existing data is used to generate new data. Here the further information generated will look like the old data, but some of the values and parameters would be different here.
This approach can increase the amount of data, and there is a high likelihood of improving the model’s performance.
Data augmentation is preferred in most deep-learning problems, where there is limited data with images.
2. Don’t Drop and Impute:
In some of the datasets, there is a high fraction of invalid data or empty. Due to that, some amount of data s dropped not to make the process complex, but by doing this, the amount of data is decreased, and several problems can occur.
To deal with it, we can apply the data imputation technique to attribute the data. Although emptying the data is not a simple and accurate method, some advanced attributes like KNNImputer and IterativeImputer can be used for accurate and efficient data imputation.
3. Custom Approach:
If there is a case of limited data, one could search for the data on the internet and find similar data. Once this type of data is obtained, it can be used to generate more data or be merged with the existing data.
The domain knowledge can help lit in this case. The domain expert can advise and guide through this problem very efficiently and accurately.
Conclusion
In this article, we discussed the limited data, the performance of several machine learning and deep learning algorithms, the amount of data increasing and decreasing, the type of problem that can occur due to limited data, and the common ways to deal with limited data. This article will help one understand the process of restricted data, its effects on performance, and how to handle it.
Some Key Takeaways from this article are:
1. Machine Learning and shallow neural networks are the algorithms that are not affected by the amount of data after some threshold level.
2. Deep neural networks are data-hungry algorithms that never stop learning from data.
3. Limited data can cause problems in every field of machine learning applications, e.g., classification, regression, time series, image processing, etc.
4. We can apply Data augmentation, imputation, and some other custom approaches based on domain knowledge to handle the limited data.
Want to Contact the Author?
Follow Parth Shukla @AnalyticsVidhya, LinkedIn, Twitter, and Medium for more content.
Contact Parth Shukla @Parth Shukla | Portfolio or Parth Shukla | Email to contact me.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
UG (PE) @PDEU | 25+ Published Articles on Data Science | Data Science Intern & Freelancer | Amazon ML Summer School '22 | AI/ML/DL Enthusiast | Reach Out @portfolio.parthshukla.live










