Data Mining: The Knowledge Discovery of Data
Introduction
We are living in an era of massive data production. When you think about it, almost every device or service we use generates a large amount of data (for example, Facebook processes approximately 500+ terabytes of data per day). This data is fed back to the product owners, who can then use it to improve the product. This article explains all about Data Mining.
The purpose of scanning big data sets is to look for trends and patterns that are difficult to detect using basic research methods. It analyzes data using sophisticated computational algorithms and then determines the likelihood of potential events based on the results. It is called knowledge discovery of data (KDD) too. It can take many forms, including visual data mining, text mining, internet mining, social networking mining, video and audio mining, etc.
Learning Objectives
- Understanding the fundamental concepts and techniques of data mining, including Anomaly detection, Exploratory data analysis (EDA) and categorization, etc.
- Ability to apply data mining techniques to real-world problems.
- Learning Practical Examples Of Data Mining.
- Understanding different steps of data mining implementation.
- Learning challenges faced by data mining engineers.
- Awareness of current trends and growths in the field of data mining, including advances in deep learning and big data analytics.
This article was published as a part of the Data Science Blogathon.
Table of Contents
Data Mining
Data mining is the process of detecting anomalies, patterns, and correlations within massive databases to forecast future results. This is accomplished by combining three intertwined fields: statistics, artificial intelligence, and machine learning. Data mining is simply sorting through data to find something valuable.
Example: Mining, on a smaller scale, is an activity that involves gathering data in one location in some structure. For example, creating an Excel spreadsheet or summarizing the main points of a text.
Data mining is all about:
- processing data;
- extracting relevant and valuable insights out of it

Source: eduonix.com
Purpose
Data mining can be used for a variety of purposes. The following are some examples of possible use for the data:
- Detecting trends;
- Predicting several types of results.
- Modeling target audience
- Collecting information about the product/service use
Data mining aids in the understanding of certain aspects of customer behavior. This knowledge allows companies to adapt and provide the best services possible.
Working
Data is downloaded, stored, and analyzed for almost every transaction we make in the information economy, from Google searches to online shopping. Today’s benefits of data mining are applicable across industries, from supply chains to healthcare, advertising, and marketing.
Predictive analytics helps companies personalize user interactions, determine the best time to upsell or cross-sell a customer, identify cost inefficiencies in their supply chain, and analyze user behavior to deduce customer pain points.
Data Mining Process In 5 Steps
The data mining process is divided into five steps. Learning more about each process step helps explain how data mining works.
- Collection. Data is stored, organized, and loaded into a data warehouse. The data is stored and handled on in-house servers or in the cloud.
- Understanding. Data Scientists and Business Analysts will inspect the “gross” or “surface” properties of the data. After that, they conduct a more in-depth analysis from the perspective of a problem statement defined by the business. This can be covered using querying, reporting, and visualization.
- Preparation. After confirming the availability of data sources, they must be cleaned, constructed, and formatted into the desired form. This stage may include more in-depth data exploration based on the insights uncovered in the former stage.
- Modeling. At this stage, modeling techniques for the prepared dataset are chosen. A data model is a visual representation of the relationships between several types of information stored in a database. A sales transaction, for example, is divided into related data points that describe the customer, the seller, the object sold, and the payment methods. Each object must be described in detail to be accurately stored and retrieved from a database.
- Evaluation. Finally, the model results are analyzed concerning business objectives. New business requirements may be raised throughout this phase due to new patterns discovered in the model results or other factors.
What is Data Mining Often Confused With?
- Data Mining vs. Data Analysis: The systematic process of finding and identifying hidden patterns and information in massive datasets. Data analysis is a subset of data mining that entails analyzing and visualizing the data to conclude past events and then using these insights to improve future results.
- Data Mining vs. Data science: It is a branch of data science that involves statistics, data visualization, predictive modeling, and big data analytics.

- Data Mining vs. Machine Learning: The design, study, and development of algorithms that allow machines to learn without human interference is called machine learning. Data mining and machine learning are subsets of data science, which is why the two terms are frequently used interchangeably. Machine learning can automate data mining processes, and data mining data can then be used to teach machines.
- Data Mining vs. Data Warehousing: Data warehousing combines data from several sources into a single database. Data warehousing, unlike data mining, does not involve extracting insights from data; rather, it is concerned with the infrastructure for storing, accessing, and maintaining databases.
Common Applications
As such, it finds use across many fields. The three most common data mining applications are marketing, business analytics, and business intelligence.
Marketing

Big data allows businesses to learn more about their customers by extracting critical insights about them from large databases. For example, an e-commerce company could use data analysis to target ads and start making more relevant product recommendations based on former purchases made by customers. Data mining is used to segment markets. Cluster analysis identifies a specific user group based on common features in a database, like age, location, education level, and so on. The market analysis allows a company to target specific groups for promotions, email marketing, online marketing, and other marketing campaigns. Some companies even use predictive analytics to predict implicit or potential customer requirements. Target, for example, uses customer tracking technology to predict the likelihood of a woman being pregnant based on the objects purchased and sends uniquely designed ads to her during her second trimester.
Business Analytics
.png)
The process of converting data into business insights is called business analytics. Business analytics is more prescriptive than business intelligence, which is descriptive (it provides data-driven insights into current business performance). Business analytics is related to identifying patterns, developing models to explain past events, predicting future events, and recommending actions to improve business outcomes.
Business Intelligence
.png)
The term “business intelligence” (BI) refers to the process of turning raw data into useful information. While data science is primarily concerned with analytics, which entails analyzing trends and forecasting the future, business intelligence provides a snapshot of the current state of the business by tracking key operational metrics in real-time. A BI dashboard, for example, could show the number of times customers purchased a specific item during a promotion and how many engagements a social media campaign received.
Key Programming Languages to Work With
To become a data miner, you must learn four programming languages: Python, R, SQL, and SAS.
- Python: One of the most flexible programming languages, Python can handle everything from data mining to website development to running embedded systems in a unified language. Pandas is a Python data management library that can import data from Excel spreadsheets to plot data with a histogram or box plot. The library is intended to make data manipulation, reading, aggregation, and visualization as simple as possible.
- R: R is a software package that includes data manipulation, calculation, and graphical display tools. As the de facto data science programming language, R can be used to solve data science problems. The software can quickly and easily implement machine learning algorithms and provides various statistical and graphical techniques, including linear and non-linear modeling, classical statistical tests, time-series analysis, categorization, and clustering.
- SQL: Relational database management systems (RDBMSs) store and retrieve information using a specialized programming language called SQL(A form of a Relational Database that stores and gives access to connected data elements.) SQL can read and retrieve data from a database and update and insert new data. Creating a SQL query is frequently the first step in the evaluation sequence.
- SAS: SAS is a statistical software suite that can be used for data management, advanced analytics, multivariate analysis, business intelligence, criminal investigation, and predictive analytics. It allows users to interact with their data by displaying dynamic charts and graphs that help them understand key relationships.
Essential Techniques
There are several data mining techniques. The following is a list of data scientists’ seven most important techniques.
Anomaly Detection: The process of identifying abnormal or concerning instances is called anomaly detection. Looking for deviations from averages can help you spot some anomalies. More advanced techniques include searching for examples that do not belong to the group or comparing data points with similar examples to see if their feature values are significantly different. Credit card companies, for example, use anomaly detection methods to alert customers to fraudulent transactions made with their credit cards by identifying transactions that do not fit their typical buying patterns.
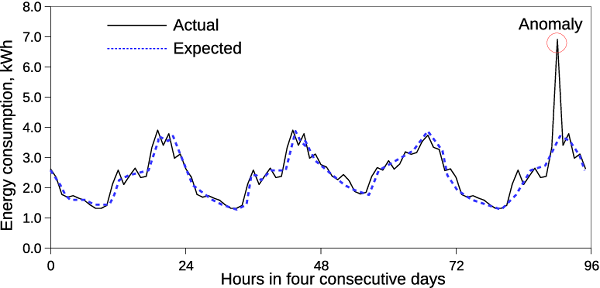
Exploratory Data Analysis: Exploratory data analysis postpones any initial hypotheses, assumptions, or data models. On the other hand, data scientists seek to uncover the underlying structure of the data, extract important variables, and detect outliers and anomalies. Most of the work is done graphically because graphs are the easiest way to infer trends, anomalies, and correlations visually.

Building Predictive Models: Predictive modeling is the process of creating, processing, and validating a model or algorithm that can be used to forecast future outcomes using historical data. By analyzing past events, organizations can use predictive modeling to forecast customer behavior and financial, economic, and market risks.
Regression: The regression includes assigning a number to every object in a dataset. These figures can be weighted (for example, the probability of an event on a scale of one to ten), or they can be related to time or quantity. The aim is to find an equation or curve that fits the data points, revealing how high the curve should be given arbitrary inputs. . Many regression techniques assign a weight to each feature before combining the positive and negative attributes from the weighted features to generate an estimate.
.png)
Decision Trees: A decision tree is a machine learning modeling approach for non-parametric categorization and regression problems. The model is hierarchical, which means it comprises a series of questionnaires that leads to a class label or value. For example, when a bank decides whether to make a loan to someone, it asks a series of questions to evaluate the applicant’s credit risk, completing with a categorization of low, medium, or high risk.
.png)
Practical Examples
Improving Customer Service: Real-life data mining examples

As the most visited online store, Amazon dominates the industry. Its online marketplace platform combines big data with a customer-centric approach to improve user delight and customer experience. Amazon has long used data analytics to serve its massive customer base better.
While using the website, the retailer collects data on each customer. The data includes information like what pages you look at, your reviews, the amount of time you spend on each page, your shipping address, and so on. The company uses external datasets, like census data, to collect customer demographic information. The more information you provide Amazon, the more it can cater to your preferences and anticipate your needs. And, once the retailer has information about you, it can recommend several products that suit you rather than making you waste time searching their vast catalog.
Information and Product Development: Real-life data mining examples

Whirlpool Corporation is one of the world’s largest home appliance manufacturers. Innovation is a top priority in the company’s business and marketing efforts. Consumer feedback is critical in their innovation strategies. In a single month, Whirpool receives a million reviews from customers worldwide. This information was gathered from 40 different websites and six distinct form factors. Emails and several contact forms with sales representatives are examples of data types. Whirlpool implements data mining software to analyze all of this data and answers critical questions like how the products are performing in the market, which features consumers prefer, how the customer purchasing experience is, and so on.
In addition to these insights, data analytics assists the entire corporation in speaking a common language and conducting a comprehensive competitive product analysis to determine where they stand in terms of competition. Converting this data into insights allows the company to explore new avenues and ideas for innovation.
Social Media Optimization: Real-life data mining examples

McDonald’s Corporation is a well-known fast-food corporation widely discussed on the most popular social media platforms – Facebook and Twitter. The company has a dazzling amount of social media commentary, which is an excellent foundation for gaining valuable insights. McDonald’s bases many management decisions, like breakfast menu solutions, on social data mining.
In response to online feedback, the fast-food chain, for example, reintroduced Szechuan sauce and introduced evening breakfasts. Monitoring and analyzing social media can disclose unexpected insights too. It could disclose, for example, that Happy Meal toys, rather than Happy Meals, drive customer engagement. Social media mining is beneficial, too, for quick responses to negative comments. McDonald’s can respond quickly to problems, including mentions of a broken ice cream machine. It aims to solve the problem as soon as possible and to prevent negative conversations from spreading further.
Defining Profitable Store Locations: Real-life data mining examples
.png)
Starbucks Corporation is a coffee company based in the United States and a well-known coffeehouse chain worldwide. One of the primary reasons for its phenomenal success is its ideal location.
The company employs a software solution for visualizing data in the form of maps, which assists it in fine-tuning how to select a store location to drive more traffic and increase sales. Starbucks had to close hundreds of stores and rethink the company’s growth strategy in 2007 and 2008. As a result, Starbucks has adopted a data-driven approach to store openings, using mapping software capable of analyzing massive amounts of data about planned store openings. The software assists Starbucks in identifying the best locations to open stores without affecting sales at other Starbucks locations by analyzing location-based data and demographics. This data mining software tool can even forecast the impact of a new Starbucks location on other Starbucks locations in the area.
Challenges
The growing size of The Data
While it may appear obvious in the context of big data, the fact remains that there is too much data. Databases are growing, making it more difficult to navigate them comprehensively.
There is a huge challenge in effectively managing all of this data.
Privacy & Security
Data mining is a process that directly handles sensitive information. As a result, it is fair to say that privacy and security concerns pose an important challenge to Data Mining.
Data mining might be considered a type of surveillance if you think about it. It deals with data on user activity, consumption habits, and interactions with ad material, among other things. This data can be used for both positive and negative purposes. The objective is what distinguishes mining from surveillance. Data mining’s ultimate purpose is to improve the consumer experience.
As a result, it’s important to safeguard all of the data gathered:
- from being stolen;
- from being altered or modified;
- from being accessed without permission.
The following ways are suggested to do this:
- Encryption mechanisms;
- Different levels of access;
- Consistent network security audits;
- Personal responsibility and clearly defined consequences of the perpetration.
Data Accuracy
The accuracy of the data is another significant difficulty in data mining. Gathered data must meet the following criteria to be considered valuable:
- complete
- accurate
- reliable
Data Noise
Noise is one of the most difficult challenges while dealing with Big Data and Data Mining.
Data Noise is anything that adds no value to the business operation. As a result, it must be filtered out so that the primary effort will remain focused on the valuable data.
In addition, there are two more issues to address:
- Corrupted attribute values
- Missing attribute values
The problem with both is that they impact the quality of the results. Whether it’s a prediction or segmentation, an abundance of noise can throw a wrench in the projects. In the case of corrupted values, the accuracy of the established rules and the training set is everything. The corrupted values result from inaccuracies in the training set, which cause errors in the mining operation. At the same time, valuable values may be considered noise and filtered out. At times, attribute values may be missing from the training set, and even if the information is present, it may be ignored by the mining algorithm due to being unrecognized. These issues are addressed by unsupervised machine learning algorithms that run routine checks and reclassifications on the datasets.
Advantages
- It is a quick method that allows novice users to analyze large amounts of data in a short period of time.
- Companies can collect knowledge-based data using this technology.
- It is less expensive than other computational data applications.
- It allows businesses to improve their service and development significantly.
- It allows the automated identification of latent phenomena and trend and behavior prediction. It aids a corporation’s decision-making process.
- It can also be activated in the current system and on existing systems.
Disadvantages
- Any data mining software solutions are complicated to use and necessarily require specialized training and certification.
- Data mining methods are inefficient, which can have serious consequences in difficult situations.
- Businesses are willing to sell valuable consumer data to other organizations to generate revenue.
- Different data mining methods work differently due to the several algorithms used in their architecture. Finding the best data mining software is thus a tough job.
Conclusion
In today’s highly competitive business environment, data mining is absolutely essential.
Data mining applications are widely used in direct marketing, health care, e-commerce, customer relationship management (CRM), the FMCG industry, telecommunications, and finance. Data mining will expand to include more complex data types in the future.
Furthermore, any model that has been designed can be refined further by examining other variables and their relationships. Data mining research will yield new methods for determining the most interesting characteristics of data.
Some Key takeaways from the article:
- Data mining uses several approaches to extract useful information from data, including statistical analysis, machine learning, and database systems.
- Choosing the appropriate data mining model depends on the type of data being analyzed and the specific objectives of the analysis.
- Data mining can raise privacy and ethical concerns as it can lead to personal data collection, storage, and analysis.
- Different data mining methods work differently due to the several algorithms used in their architecture. Finding the best data mining software is thus a tough job.
I hope this article will help you in learning about data mining.
If you want to connect with me, then you can connect on:
or for any other doubts, you can send a mail to me also.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Currently, I Am pursuing my Bachelors of Technology( B.Tech) from Vellore Institute of Technology. I am very enthusiastic about programming and its real applications including software development, machine learning and data science.









