Your One-Stop Destination to Start your NLP journey with SpaCy
Introduction
Natural Language Processing (NLP) is a field of Artificial Intelligence that deals with the interaction between computers and human language. NLP aims to enable computers to understand, interpret and generate human language naturally and helpfully. NLP techniques are used in many applications, such as language translation, text summarization, sentiment analysis, etc. These techniques are based on machine learning, computational linguistics, and computer science. NLP is now entirely in the boom, and with the recent developments in transformers and the advent of everyone’s favorite ChatGPT, this field still has a lot to offer! Libraries such as NLTK, Hugging face, and SpaCy are useful for NLP tasks.
The major learning objectives for today would include getting familiarized with the basic terminologies of NLP like tokenizing, stemming, lemmatization, POS tagging, and how we can implement the same using the python library spaCy. By the end of the blog, I assure to leave you with a firm grasp of the various concepts of NLP and how you can practically implement it in real life using one of the python libraries named SpaCy.
This article was published as a part of the Data Science Blogathon.
Table of Contents
- Introduction to key terms in NLP
1.1 Tokenization
1.2 Normalization
1.3 Stemming
1.4 Lemmatization
1.5 Stop Words
1.6 Parts of Speech tagging
1.7 Statistical Language Modelling
1.8 Syntactic Analysis
1.9 Semantic Analysis
1.10 Sentiment Analysis - The SpaCy library in action with python
- Installing and setting up spaCy
- SpaCy trained pipelines
- Text Pre-processing using spaCy
5.1 Tokenization
5.2 Lemmatization
5.3 Splitting sentences in the text
5.4 Removing punctuation
5.5 Removing stopwords - POS Tagging using Spacy
- Dependency Parsing using Spacy
- Named Entity Recognition using Spacy
- Conclusion
Learning the Key Terms in NLP
In this article, we undertake a no-nonsense approach and start with some key terminologies related to NLP. However, we would mainly focus on the application side of NLP and will be learning how to implement various concepts in NLP with the help of one python library-spaCy.
So here are ten select NLP processing terms, selectively and concisely defined.
Tokenization
If you have done NLP, you will have come across this term. Tokenization is an early step in the NLP process and involves splitting longer pieces of text into smaller parts or tokens. Larger texts can be tokenized into sentences, and sentences can be tokenized into words, and so on. Post tokenization, further steps are needed to make the input text of use.
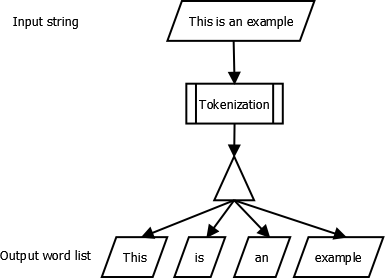
Normalization
The next step you would be required to perform is normalizing the text. In text data, normalization would mean converting all letters to the same case (upper or lower), removing punctuations, expanding contractions, converting numbers to word equivalents, and so on. Thus normalization puts all words on the same footing and allows equal processing of all data.
Stemming
This process removes affixes from all the words to attain a word stem. Stemming may involve removing prefixes, suffixes, infixes, or circumfixes. For example, if we perform stemming on the word “eating,” we would end up getting the stem word “eat.”
Lemmatization
This process is similar to stemming, only differing in the fact that this process can capture the canonical forms based on the word’s lemma. An excellent example of lemmatization is that stemming the word “caring” would return “car,” but lemmatizing it would return “care.”
The image below shows the difference between stemming and lemmatization.
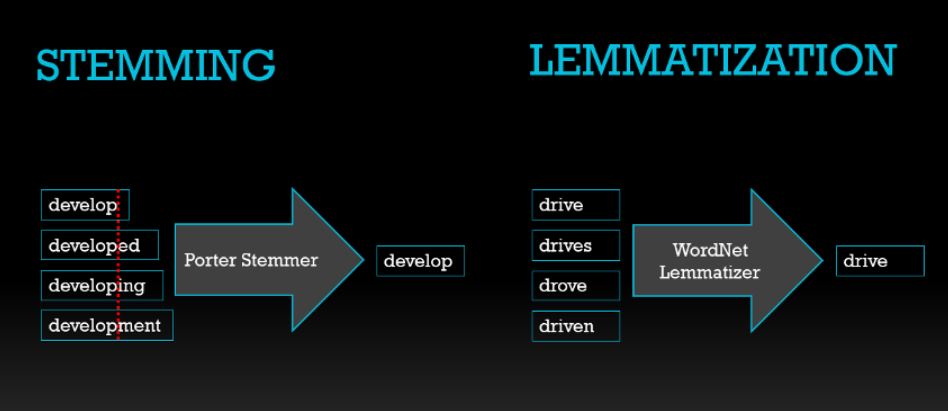
Stop Words
These are the words most common in the language; hence, they contribute very little to the meaning and thus are safe to remove before further processing. Examples of some stop words are “a,” “and,” and “the.” For example, the sentence “The quick brown fox jumps over the lazy dog” would read the same as “quick brown fox jumps over the lazy dog,” i.e. when we remove the stop words.
Parts-of-Speech (POS) Tagging
This step involves assigning a stage to each token generated from the text. The most popular POS tagging would be identifying words as nouns, pronouns, adverbs, adjectives, etc. The figure below shows how POS can be performed.
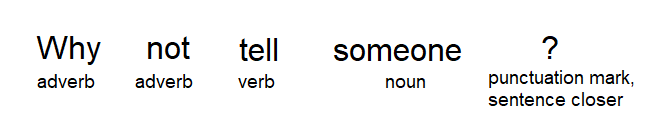
Statistical Language Modelling
This allows for building a model that can help estimate a natural language. For a sequence of input words, the developed model would assign a probability to the entire sequence, allowing for estimating the likelihood of various possible sentences. This is useful in NLP applications that generate text.
Syntactic Analysis
This analyzes strings as symbols and ensures their conformance to grammatical rules. This step must always be performed before other steps of information retrieval, like semantic or sentiment analysis. This step is also often known as sparing.
Semantic Analysis
Often referred to as meaning generation, this text helps determine the meaning of text selections. Once the input selection of text is read and parsed (i.e., analyzed syntactically), the text can further be interpreted for meaning. Thus while syntactic analysis is mainly concerned with what the selected words are made of, semantic analysis gives information about what the collection of words actually means.
Sentiment Analysis
This step involves capturing and analyzing the sentiment captured in the text selection. The sentiment can be generic, like happy, sad, angry, or more generic as a range of values along a scale, with neutral in the middle and positive and negative sentiment increasing in either direction.
I have given you enough theoretical knowledge to give you a headstart on NLP. Going further, I will be focussing more on the application point of view and will e introducing you to one of the python libraries you can use to help find your way through NLP problems.
Get Set Go with SpaCy in Python
Among the plethora of libraries in python for tackling NLP problems, spaCy stands out of them all. If you are not new to NLP and spaC, you should have realized what I am talking about. And if you are new, allow me to enthrall you with the power of spaCy!
SpaCy is a free, open-source python library used mainly for NLP applications that help developers process and understand large chunks of text data. Equipped with advanced tokenizing, parsing, and entity recognition features, spaCy provides a fast and efficient runtime, thus proving to be one of the best choices for NLP. A stand-alone feature of spaCy is the ability to create ad use custom-made models for NLP tasks like entity recognition or POS tagging. As we move along, I will provide you with the working codes of the various functions that spaCy can perform just by typing a few lines, and I assure you that I will leave you in awe by the conclusion of this blog.
Installing and Setting Up SpaCy
To install and set up spaCy, you need python and pip installed on your local machine. If required, python and pip can be downloaded from the official python website. Once both are installed, the latest version of spaCy and its dependents can be installed by the following command:
pip install spacy
You can download one of the many spaCy’s pre-trained language models post-installation. The statistical models allow spaCy to perform NLP-related tasks like POS tagging, Named Entity Recognition, and dependency parsing. The different statistical models of spaCy are listed below:
- en_core_web_sm: English multi-task CNN trained on OntoNotes. Size – 11 MB
- en_core_web_md: English multi-task CNN introduced on OntoNotes, with GloVe vectors trained on Common Crawl. Length – 91 MB
- en_core_web_lg: English multi-task CNN introduced on OntoNotes, with GloVe vectors trained on Common Crawl. Size – 789 MB
These models can be easily imported using spacy.load(“model_name“)
import spacy
nlp = spacy.load('en_core_web_sm')
SpaCy Trained Pipelines
SpaCy introduces the concept of pipelines. The first step of spaCy involves passing the input string as an NLP object. This object is a pipeline of several preprocessing steps (mentioned previously) through which the input text must go. SpaCy has a lot of trained models for different languages. Typically the pipeline includes a tagger, lemmatizer, parser, and entity recognizer. You can also design your custom pipelines in spaCy.
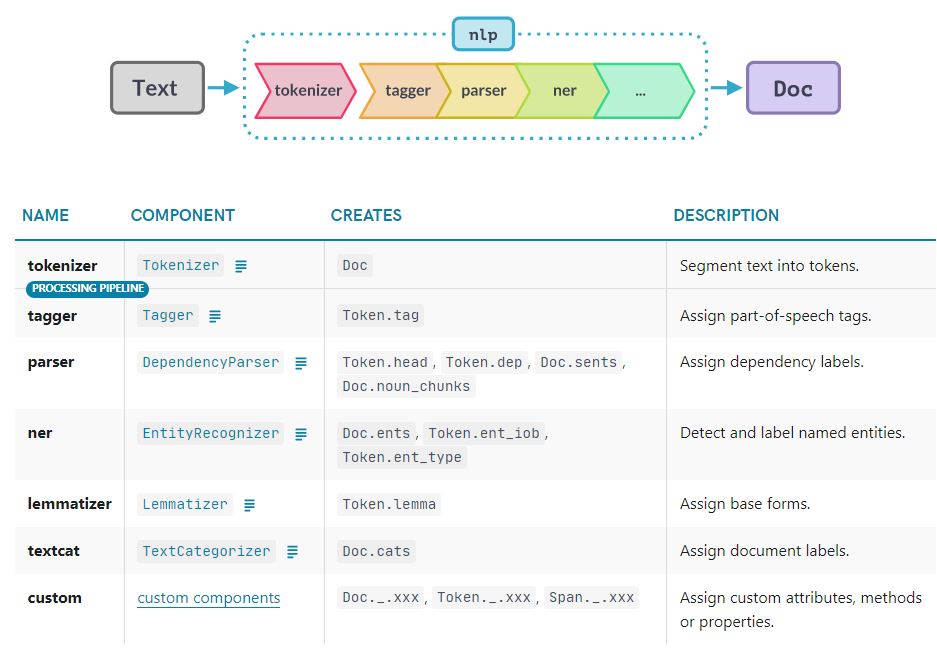
This is how you can create an NLP object in spaCy.
import spacy
nlp = spacy.load('en_core_web_sm')
#Creating an NLP object
doc =nlp("He went to play cricket")
The below code can be used to figure out the different active pipelines.
nlp.pipe_names
You can also choose to disable one or more pipelines at your own will to enable faster operation. Below code can be used for the same.
#nlp.disable_pipes('tagger', 'parser')
#if any of the above components are diasbled, i.e. parser or tagger, w.r.t current context
#then the labels such as .pos, or .dep_ might not work.
#One has to disable or enable the components as per the needs.
#nlp.disable_pipes('parser')
nlp.add_pipe('sentencizer') #will help in splitting sentences
The above code only keeps the tokenizing pipeline alive, making the process fast.
Pre-process your Data with SpaCy
Tokenization
The following code snippet will show you how text and doc are different in spaCy. You will not see any difference between the both when you print them, but there is a difference in the length of both of them, as you will see.
#pass the text you want to analyze to your model
text = "Taylor is learning music"
doc = nlp(text)
print(doc)
print(len(text)) #output = 24
print(len(doc)) #output = 4
Now you can print the tokens from the doc as follows:
for token in doc:
print(token.text)
Lemmatization
Below lines can efficiently perform lemmatization for you.
#pass the text you want to analyze to your model
text = "I am going where Taylor went yesterday"
doc = nlp(text)
for token in doc:
print(token.text, "-", token.lemma_)
Splitting Sentences in Text
text = "Taylor is learning music. I am going where Taylor went yesterday. I like listening to Taylor's music"
doc = nlp(text)
Let me show you how to split the above text into individual sentences.
sentences = [sentence.text for sentence in doc.sents] sentences
This will return a list containing each of the individual sentences. Now you can perform slicing to get your desired output sentence.
Removing Punctuation
Before proceeding further into processing, we should remove the Punctuation. The below code shows how it can be performed.
token_without_punc = [token for token in doc if not token.is_punct]
token_without_punc
Removing Stopwords
You can implement the code below to get an idea of the existing stopwords in SpaCy.
all_stopwords = nlp.Defaults.stop_words
len(all_stopwords)
Now that we have the list of all stop words, it’s time to remove them from our input text.
token_without_stop = [token for token in token_without_punc if not token.is_stop]
token_without_stop
POS Tagging using SpaCY
SpaCy makes it a cakewalk to perform POS tagging with the pos_ attribute of its token object. You can iterate over the tokens in a Doc object to print out their POS tags, as shown below:
for token in doc: print(token.text, token.pos_)
SpaCy has a collection of a large number of POS stages that are consistent over all the supported languages. A list of all the POS tags can be found in the SpaCy documentation.
Dependency Parsing using SpaCy
Every sentence has its grammatical structure, and we can explore it with the help of dependency parsing. It can be imagined as a directed graph where nodes correspond to the words and the edges to the corresponding relationships.
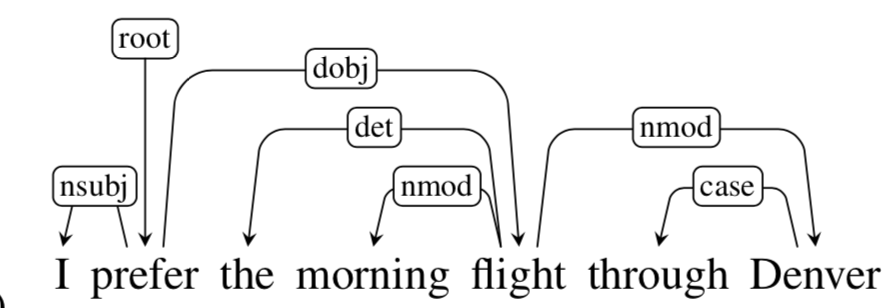
The figure above shows how the various words depend on each other via the relationships marked along the graph edges. The dependency term root determines the main verb or action in the sentence, and the other words are directly or indirectly connected to the root. Spacy includes a detailed review of several dependency labels in the SpaCy Documentation.
Again spacy has an attribute dep_ to help visualize the dependencies amongst the words.
for token in doc: print(token.text, token.dep_)
Named Entity Recognition (NER) using SpaCy
What NER does is that it tries to identify and classify named entities (real-world objects) in text, such as people, organizations, locations,s, etc. NER helps to extract structured information from unstructured data and is a valuable tool for information extraction and entity linking.
SpaCy includes pre-trained entity models that help classify named entities in the text input. It has several pre-defined entity types, such as PERSON, ORG, and GPE. A complete list of entity types can be found in spaCy documentation.
To get the entities, we can use the NER model, iterate over them in the Doc object, and print them out. Again spaCy provides the ent_ attribute to ease the process.
for ent in doc.ents: print(ent.text, ent.label_)
Conclusion
If you followed through till this point, I could assure you have a good headstart to NLP. Your key takeaways from this article would be:
The key terms you would often be coming across in the NLP Literature are tokenization, Stemming, Parsing, POS Tagging, etc.
- Getting introduced to the spaCy pipeline ideas
- Getting hands-on with performing the preprocessing steps(tokenizing, lemmatization, sentence splitting, removing punctuation and stop words) using spaCy
- Performing tasks like POS tagging, dependency parsing, and NER using spaCy
I hope you enjoyed today’s blog. If you want to continue learning NLP, trust me, you will find yourself using spaCy more than often. Several resources are available for you to continue learning NLP with spaCy. The spaCy documentation is an excellent place to start after this. You will get a good idea of the detailed features of the library and its additional features. Also, stay tuned to my blogs to increase your knowledge bandwidth on NLP! See you in my next time.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







