Introduction
S3 is Amazon Web Services cloud-based object storage service (AWS). It stores and retrieves large amounts of data, including photos, movies, documents, and other files, in a durable, accessible, and scalable manner. S3 provides a simple web interface for uploading and downloading data and a powerful set of APIs for developers to integrate S3. S3 storage is dispersed across various locations and availability zones, providing the data’s high availability and durability.
S3 has several storage classes, including Standard, Infrequent Access (IA), and Glacier, each with a different price and durability. Based on preset rules, S3 lifecycle policies allow you to transfer or destroy items across storage classes automatically. Businesses of various sizes rely on S3 for several functions, including data backup and recovery, online and mobile apps, content distribution, and big data analytics. S3 is a cost-effective option for storing and retrieving significant volumes of data since you only pay for the storage and transport you use.

Learning Objectives
- You will be introduced to the fundamentals of Amazon S3, including its capabilities, advantages, and use cases.
- Understanding the distinctions between S3 and other Amazon storage services.
- Knowing the various S3 storage classes and when to use them.
- Knowing optimal practices for S3 data security.
- Then you’ll understand how to maximize S3 performance for various applications.
This article was published as a part of the Data Science Blogathon.
Table of Contents
Q1. What Exactly is Amazon S3, and What are its Main Features?
Amazon S3 (Simple Storage Service) is an Amazon Web Services cloud-based object storage service (AWS). It is intended to store and retrieve vast volumes of data, such as photographs, videos, documents, and other sorts of files, in a durable, available, and scalable manner.
The main features of S3 include the following:
- Scalability: S3 can accommodate nearly infinite quantities of data and requests.
- Durability: S3 replicates data across various availability zones automatically, ensuring that data is always available.
- Availability: S3 provides high availability, with a service level agreement (SLA) of 99.99% uptime.
- Security: S3 offers numerous choices for data security, including encryption, bucket rules, and IAM roles.
- Integration: S3 interfaces with many other AWS services, including Amazon EC2, Amazon RDS, and Amazon EMR, making it simple to use S3 as part of your comprehensive cloud architecture.
- Cost-effectiveness: S3 has a low-cost pricing plan based on the quantity of storage used and the amount of data sent.
Overall, S3 is a highly scalable and cost-effective storage system built for reliably and securely storing and retrieving massive volumes of data.

Q2. What is the Distinction between Amazon S3 and EBS?
Amazon S3 and Amazon EBS (Elastic Block Store) are Amazon Web Services (AWS) storage systems. However, they have different roles and features. S3 stores and retrieves massive volumes of unstructured data, including photographs, videos, documents, etc. S3 is scalable and durable for storing seldom accessed data like backups, archives, and logs.
EBS is a block-level storage solution for databases and applications that need high-performance, low-latency access.
A few key differences between S3 and EBS are:
- S3 offers data access at the object level, whereas EBS allows access at the block level.
- In the case of studies, S3 is usually used to store unstructured data that is seldom accessed, whereas EBS is frequently used to store structured data that requires high-performance access.
- S3 pricing is decided by the amount of storage utilized, and the amount of data moved. In contrast, EBS pricing is determined by the amount of storage used and the number of I/O requests executed.
- In terms of endurance, S3 exceeds EBS with an SLA of 99.999999999%.
S3 and EBS are designed for separate use cases and offer various functionality. S3 is optimal for storing massive amounts of unstructured data, whereas EBS is optimal for storing structured data needing high-performance access.
Learn more: Amazon ECS

Q3. What are the Different Amazon S3 Storage Classes, and When would you Utilize them?
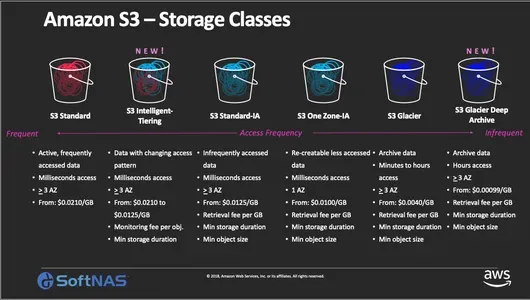
Amazon S3 provides many storage classes with varying durability, availability, performance, and pricing. S3 has the following storage classes:
- S3 Standard: This is the S3 storage class by default, and it is intended for regularly accessed data that requires excellent durability, availability, and performance. The S3 Standard service is appropriate for storing frequently requested data, such as website content, mobile applications, and gaming assets.
- S3 Standard-Infrequent Access (S3 Standard-IA): This storage class is designed for infrequently accessed data requiring rapid access. It is ideal for storing backups, disaster recovery, and other data accessed less frequently. S3 Standard-IA offers lower storage costs than S3 Standard but with slightly higher retrieval costs.
- S3 One Zone-Infrequent Access (S3 One Zone-IA): This storage class is similar to S3 Standard-IA but stores data in a single availability zone rather than multiple availability zones. It is ideal for data that can be recreated easily, such as thumbnails, transcoded media files, and other temporary data.
- S3 Glacier: This storage class is designed for data archival and long-term backup. It offers the lowest storage costs of all S3 storage classes but has a longer retrieval time than other storage classes.
- S3 Glacier Deep Archive: This storage class is designed for long-term archival and retention of rarely accessed data. It offers the lowest storage costs of all S3 storage classes but has a longer retrieval time than other storage classes, which can take up to 12 hours.
Selecting a particular storage class depends on the stored data’s use case and access patterns. S3 Standard is ideal for frequently accessed data that requires high performance and availability, while S3 Glacier is ideal for rarely accessed data and is intended for archival purposes. The other storage classes offer a balance between cost and performance, with varying levels of durability and availability.
Q4. What Exactly are Amazon S3 Lifecycle Policies, and How do they Function?
S3 lifecycle policies are an Amazon S3 feature that allows you to automatically transfer things between storage classes or destroy objects depending on your established rules or criteria. You may minimize your storage expenses and eliminate the need for manual intervention in data management by utilizing S3 lifecycle policies. A lifecycle policy comprises one or more rules describing when objects should be moved to a new storage class or removed. Each direction is made up of the following components:Prefix: A prefix that indicates which objects the rule applies to.
Transitions: A collection of one or more changes that describe the destination storage class and the time after which objects should be migrated.
Expiration: An expiry action determining when objects should be removed after a specific period.
The rule’s state specifies whether it is activated or disabled.
When an S3 lifecycle policy is applied to a bucket, it affects all items that meet the rule’s prefix. S3 examines the regulations in the order they are defined and executes the actions indicated on the objects that match the rule. You may, for example, write a rule that moves all things with the “logs/” prefix to the S3 Glacier storage class after 30 days and deletes them after 365 days. You can also write a rule that moves items with the prefix “archive/” to the S3 Standard-IA storage class after 60 days and deletes them after 365 days.
You may save storage costs and automate data management activities using S3 lifecycle policies to guarantee that your data is kept in the most suitable storage class based on access patterns and retention needs.

Q5. How can you Keep Data Stored in Amazon S3 Safe?
S3 data security methods include:
- Bucket Policies: Define rights for one or more buckets using bucket policies. Bucket rules can restrict access and actions.
- Access Control Lists (ACLs): Define bucket object permissions with ACLs. ACLs can restrict object access and activities.
- Encryption: You can encrypt data stored in S3 using server-side or client-side encryption. Server-side encryption encrypts data at rest in S3 using encryption keys managed by AWS. Client-side encryption encrypts data before it is uploaded to S3 and requires you to manage the encryption keys.
- Cross-Origin Resource Sharing (CORS): CORS lets you restrict S3 resource access from non-S3 websites. CORS lets you specify domains and actions for S3 resource access.
- MFA Delete: S3 buckets can need MFA devices to remove items. This prevents unintended data destruction.
- Logging and Monitoring: Amazon CloudTrail logs all S3 API calls, and AWS CloudWatch monitors S3 access logs and bucket metrics. This lets you monitor S3 data access and identify unusual activities.
S3 supports server-side and client-side encryption. Amazon keys secure S3 data at rest via server-side encryption. Client-side encryption encrypts data before uploading to S3 and needs key management. Client-side encryption encrypts data before uploading to S3 and needs key management.
By using these security measures and best practices, you can ensure that your data stored in S3 is protected from unauthorized access, theft, or accidental deletion.

Q6. How can you Improve the Performance of Amazon S3 for your Application?
There are various approaches you may take to improve S3 speed for your application, including Region Selection: To reduce latency and increase performance, select the S3 area nearest to your application’s users.
Object Key Naming: Using unique and random object key names to distribute things uniformly across various partitions in S3. This can aid in the prevention of hotspots and increase performance.
Object Size: To minimize the number of queries and enhance performance, use bigger object sizes (e.g., 128 MB or more). S3 now allows multipart uploads, which allow you to split up huge files and parallelize the upload process.
Caching: Employ Amazon CloudFront to cache frequently requested assets closer to your users at edge locations. CloudFront can help your application minimize latency and enhance performance.
Transfer Acceleration: Using Amazon CloudFront’s globally spread edge locations, you may use Amazon S3 Transfer Acceleration to expedite data transfers to and from S3.
Employ parallelized downloads or uploads to increase throughput and decrease transfer time. This may be accomplished through the use of technologies like S3DistCp or by parallelizing transfers at the application level.
S3 Select: Use S3 Select to obtain only a subset of data from S3 objects, minimizing network traffic and boosting query efficiency.
Applying these improvements and recommended practices may enhance your application’s speed and scalability while accessing data stored in S3.

Conclusion
In conclusion, Amazon S3 is a highly scalable and durable object storage service that Amazon Web Services (AWS) offers. It provides a simple and cost-effective way to store and retrieve any amount of data from anywhere on the web. In this discussion, we have covered six important questions related to Amazon S3, which can be helpful for understanding the service and preparing for an interview.
Key takeaways of this article:
- Amazon S3 is an object storage service provided by AWS, which is highly scalable and durable.
- We discussed some different S3 storage classes to cater to different use cases and cost requirements. We also discussed S3 lifecycle policies that help you automate your data management by defining rules for transitioning objects to different storage classes or deleting them after a specific period.
- To secure data stored in S3, you can use bucket policies, access control lists (ACLs), encryption, cross-origin resource sharing (CORS), MFA deletion, logging, and monitoring.
- Finally, we discussed to optimize S3 performance for your application, you can choose the closest S3 region, use unique object key names, upload larger object sizes, use caching, transfer acceleration, parallelization, and S3 Select.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
My self Bhutanadhu Hari, 2023 Graduated from Indian Institute of Technology Jodhpur ( IITJ ) . I am interested in Web Development and Machine Learning and most passionate about exploring Artificial Intelligence.






