Introduction
Large Language Models have come a long way in Document Q&A and information retrieval. These models know a lot about the world, but sometimes, they struggle to know when they don’t know something. This leads them to make things up to fill the gaps, which isn’t great.

However, a new method called Retrieval Augmented Generation (RAG) seems promising. Using RAG to query an LLM with your private knowledge base. It helps these models get better by adding extra information from their data sources. This makes them more innovative and helps reduce their mistakes when they don’t have enough information.
RAG works by enhancing prompts with proprietary data, ultimately enhancing the knowledge of these large language models while simultaneously reducing the occurrence of hallucinations.
Learning Objectives
1. Understanding of the RAG approach and its benefits
2. Recognize the challenges in Document QnA
3. Difference between Simple Generation and Retrieval Augmented Generation
4. Practical implementation of RAG on an industry use case like Doc-QnA
By the end of this learning article, you should have a solid understanding of Retrieval Augmented Generation (RAG) and its application in enhancing the performance of LLMs in Document Question Answering and Information Retrieval.
This article was published as a part of the Data Science Blogathon.
Table of contents
Getting Started
Regarding Document Question Answering, the ideal solution is to give the model the specific information it needs right when asked a question. However, deciding what information is relevant can be tricky and depends on what the large language model is expected to do. This is where the concept of RAG becomes important.
Let us see how a RAG pipeline works:
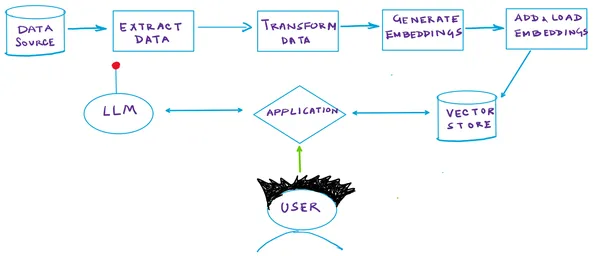
Retrieval Augmented Generation
RAG, a cutting-edge generative AI architecture, employs semantic similarity to identify pertinent information in response to queries autonomously. Here’s a concise breakdown of how RAG functions:
- Vector Database: In a RAG system, your documents are stored within a specialized Vector DB. Each document undergoes indexing based on a semantic vector generated by an embedding model. This approach enables rapid retrieval of documents closely related to a given query vector. Each document is assigned a numerical representation (the vector), signifying its semantic meaning.
- Query Vector Generation: When a query is submitted, the same embedding model produces a semantic vector that represents the query.
- Vector-Based Retrieval: Subsequently, the model utilizes vector search to identify documents within the DB that exhibit vectors closely aligned with the query’s vector. This step is crucial in pinpointing the most relevant documents.
- Response Generation: After retrieving the pertinent documents, the model employs them with the query to generate a response. This strategy empowers the model to access external data precisely when required, augmenting its internal knowledge.
The Illustration
The illustration below sums up the entire steps discussed above:
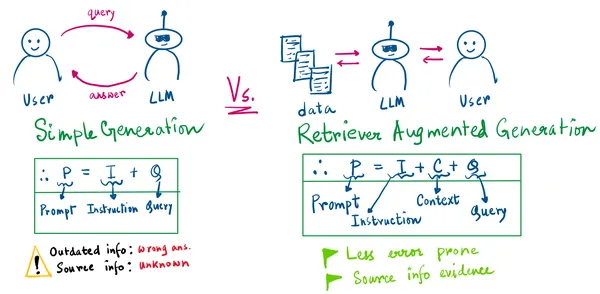
From the drawing above, there are 2 important things to pinpoint :
- In the Simple generation, we will never know the source information.
- Simple generation can lead to wrong information generation when the model is outdated, or its knowledge cutoff is before the query is asked.
With the RAG approach, our LLM’s prompt will be the instruction given by us, the retrieved context, and the user’s query. Now, we have the evidence of the information retrieved.
So, instead of taking the hassle of retraining the pipeline several times to an ever-changing information scenario, you can add updated information to your vector stores/data stores. The user can come next time and ask similar questions whose answers have now changed (take an example of some finance records of an XYZ firm). You are all set.
Hope this refreshes your mind on how RAG works. Now, let’s get to the point. Yes, the code.
I know you did not come here for the small talk. 👻
Let’s Skip to the Good Part!
1: Making the VSCode Project Structure
Open VSCode or your preferred code editor and create a project directory as follows (carefully follow the folder structure) –
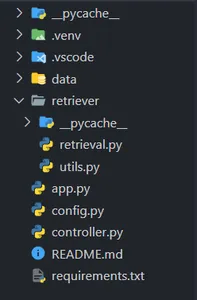
Remember to create a virtual environment with Python ≥ 3.9 and install the dependencies in the requirements.txt file. (Don’t worry, I will share the GitHub link for the resources.)
2: Creating a Class for Retrieval and Embedding Operations
In the controller.py file, paste the code below and save it.
from retriever.retrieval import Retriever
# Create a Controller class to manage document embedding and retrieval
class Controller:
def __init__(self):
self.retriever = None
self.query = ""
def embed_document(self, file):
# Embed a document if 'file' is provided
if file is not None:
self.retriever = Retriever()
# Create and add embeddings for the provided document file
self.retriever.create_and_add_embeddings(file.name)
def retrieve(self, query):
# Retrieve text based on the user's query
texts = self.retriever.retrieve_text(query)
return texts
This is a helper class for creating an object of our Retriever. It implements two functions –
embed_document: generates the embeddings of the document
retrieve: retrieves text when the user asks a query
Down the lane, we will get deeper into the create_and_add_embeddings and retrieve_text helper functions in our Retriever!
3: Coding our Retrieval pipeline!
In the retrieval.py file, paste the code below and save it.
3.1: Import the necessary libraries and modules
import os
from langchain import PromptTemplate
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores.deeplake import DeepLake
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import PyMuPDFLoader
from langchain.chat_models.openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.memory import ConversationBufferWindowMemory
from .utils import save
import config as cfg3.2: Initialize the Retriever Class
# Define the Retriever class
class Retriever:
def __init__(self):
self.text_retriever = None
self.text_deeplake_schema = None
self.embeddings = None
self.memory = ConversationBufferWindowMemory(k=2, return_messages=True)csv3.3: Let’s write the code for creating and adding the document embeddings to Deep Lake
def create_and_add_embeddings(self, file):
# Create a directory named "data" if it doesn't exist
os.makedirs("data", exist_ok=True)
# Initialize embeddings using OpenAIEmbeddings
self.embeddings = OpenAIEmbeddings(
openai_api_key=cfg.OPENAI_API_KEY,
chunk_size=cfg.OPENAI_EMBEDDINGS_CHUNK_SIZE,
)
# Load documents from the provided file using PyMuPDFLoader
loader = PyMuPDFLoader(file)
documents = loader.load()
# Split text into chunks using CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=cfg.CHARACTER_SPLITTER_CHUNK_SIZE,
chunk_overlap=0,
)
docs = text_splitter.split_documents(documents)
# Create a DeepLake schema for text documents
self.text_deeplake_schema = DeepLake(
dataset_path=cfg.TEXT_VECTORSTORE_PATH,
embedding_function=self.embeddings,
overwrite=True,
)
# Add the split documents to the DeepLake schema
self.text_deeplake_schema.add_documents(docs)
# Create a text retriever from the DeepLake schema with search type "similarity"
self.text_retriever = self.text_deeplake_schema.as_retriever(
search_type="similarity"
)
# Configure search parameters for the text retriever
self.text_retriever.search_kwargs["distance_metric"] = "cos"
self.text_retriever.search_kwargs["fetch_k"] = 15
self.text_retriever.search_kwargs["maximal_marginal_relevance"] = True
self.text_retriever.search_kwargs["k"] = 3
3.4: Now, let’s code the function that will retrieve text!
def retrieve_text(self, query):
# Create a DeepLake schema for text documents in read-only mode
self.text_deeplake_schema = DeepLake(
dataset_path=cfg.TEXT_VECTORSTORE_PATH,
read_only=True,
embedding_function=self.embeddings,
)
# Define a prompt template for giving instruction to the model
prompt_template = """You are an advanced AI capable of analyzing text from
documents and providing detailed answers to user queries. Your goal is to
offer comprehensive responses to eliminate the need for users to revisit
the document. If you lack the answer, please acknowledge it rather than
making up information.
{context}
Question: {question}
Answer:
"""
# Create a PromptTemplate with the "context" and "question"
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
# Define chain type
chain_type_kwargs = {"prompt": PROMPT}
# Initialize the ChatOpenAI model
model = ChatOpenAI(
model_name="gpt-3.5-turbo",
openai_api_key=cfg.OPENAI_API_KEY,
)
# Create a RetrievalQA instance of the model
qa = RetrievalQA.from_chain_type(
llm=model,
chain_type="stuff",
retriever=self.text_retriever,
return_source_documents=False,
verbose=False,
chain_type_kwargs=chain_type_kwargs,
memory=self.memory,
)
# Query the model with the user's question
response = qa({"query": query})
# Return response from llm
return response["result"]
4: Utility function to query our pipeline and extract the result
Paste the below code in your utils.py file :
def save(query, qa):
# Use the get_openai_callback function
with get_openai_callback() as cb:
# Query the qa object with the user's question
response = qa({"query": query}, return_only_outputs=True)
# Return the answer from the llm's response
return response["result"]5: A config file for storing your keys….nothing fancy!
Paste the below code in your config.py file :
import os
OPENAI_API_KEY = os.getenv(OPENAI_API_KEY)
TEXT_VECTORSTORE_PATH = "data\deeplake_text_vectorstore"
CHARACTER_SPLITTER_CHUNK_SIZE = 75
OPENAI_EMBEDDINGS_CHUNK_SIZE = 16Finally, we can code our Gradio app for the demo!!
6: The Gradio app!
Paste the following code in your app.py file :
# Import necessary libraries
import os
from controller import Controller
import gradio as gr
# Disable tokenizers parallelism for better performance
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# Initialize the Controller class
controller = Controller()
# Define a function to process the uploaded PDF file
def process_pdf(file):
if file is not None:
controller.embed_document(file)
return (
gr.update(visible=True),
gr.update(visible=True),
gr.update(visible=True),
gr.update(visible=True),
)
# Define a function to respond to user messages
def respond(message, history):
botmessage = controller.retrieve(message)
history.append((message, botmessage))
return "", history
# Define a function to clear the conversation history
def clear_everything():
return (None, None, None)
# Create a Gradio interface
with gr.Blocks(css=CSS, title="") as demo:
# Display headings and descriptions
gr.Markdown("# AskPDF ", elem_id="app-title")
gr.Markdown("## Upload a PDF and Ask Questions!", elem_id="select-a-file")
gr.Markdown(
"Drop an interesting PDF and ask questions about it!",
elem_id="select-a-file",
)
# Create the upload section
with gr.Row():
with gr.Column(scale=3):
upload = gr.File(label="Upload PDF", type="file")
with gr.Row():
clear_button = gr.Button("Clear", variant="secondary")
# Create the chatbot interface
with gr.Column(scale=6):
chatbot = gr.Chatbot()
with gr.Row().style(equal_height=True):
with gr.Column(scale=8):
question = gr.Textbox(
show_label=False,
placeholder="e.g. What is the document about?",
lines=1,
max_lines=1,
).style(container=False)
with gr.Column(scale=1, min_width=60):
submit_button = gr.Button(
"Ask me 🤖", variant="primary", elem_id="submit-button"
)
# Define buttons
upload.change(
fn=process_pdf,
inputs=[upload],
outputs=[
question,
clear_button,
submit_button,
chatbot,
],
api_name="upload",
)
question.submit(respond, [question, chatbot], [question, chatbot])
submit_button.click(respond, [question, chatbot], [question, chatbot])
clear_button.click(
fn=clear_everything,
inputs=[],
outputs=[upload, question, chatbot],
api_name="clear",
)
# Launch the Gradio interface
if __name__ == "__main__":
demo.launch(enable_queue=False, share=False)
Grab your🧋, cause now it is time to see how our pipeline works!
To launch the Gradio app, open a new terminal instance and enter the following command:
python app.pyNote: Ensure the virtual environment is activated, and you are in the current project directory.
Gradio will start a new instance of your application in the localhost server as follows:

All you need to do is CTRL + click on the localhost URL (last line), and your app will open in your browser.
YAY!
Our Gradio App is here!
Let’s drop an interesting PDF! I will use Harry Potter’s Chapter 1 pdf from this Kaggle repository containing Harry Potter books in .pdf format for chapters 1 to 7.
Lumos! May the light be with you🪄
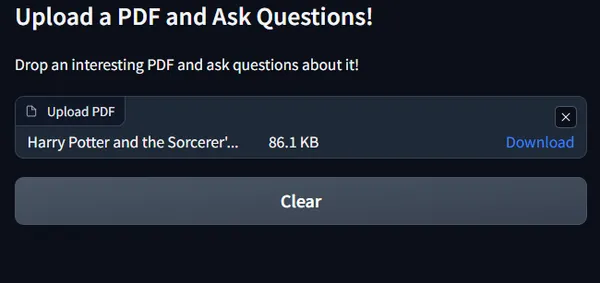
Now, as soon as you upload, the text box to ask a query will be activated as follows:

Let’s get to the most awaited part now — Quizzing!
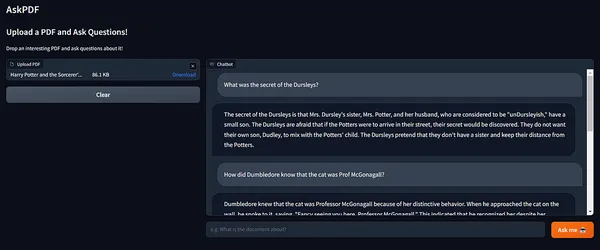
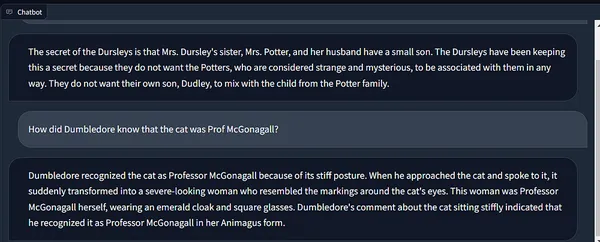
Wow! 😲
I love how accurate the answers are!
Also, look at how Langchain’s memory maintains the chain state, incorporating context from past runs.
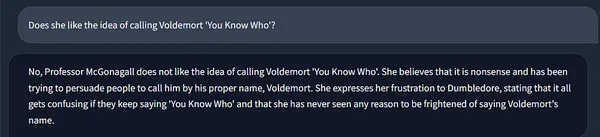
It remembers that she here is our beloved Professor McGonagall! ❤️🔥
A Short Demo of How the App Works!
RAG’s practical and responsible approach can be extremely useful to data scientists across various research areas to build accurate and responsible AI products.
1. In healthcare diagnosis, Implement RAG to assist doctors and scientists in diagnosing complex medical conditions by integrating patient records, medical literature, research papers, and journals into the knowledge base, which will help retrieve up-to-date information when making critical decisions and research in healthcare.
2. In customer support, companies can readily use RAG-powered conversational AI chatbots to help resolve customer inquiries, complaints, and information about products and manuals, FAQs from a private product, and purchase order information database by providing accurate responses, improving the customer experience!
3. In fintech, analysts can incorporate real-time financial data, market news, and historical stock prices into their knowledge base, and an RAG framework will quickly respond efficiently to queries about market trends, company financials, investment, and revenues, aiding strong and responsible decision-making.
4. In the ed-tech market, E-learning platforms can have RAG-made chatbots deployed to help students resolve their queries by providing suggestions, comprehensive answers, and solutions based on a vast repository of textbooks, research articles, and educational resources. This enables students to deepen their understanding of subjects without requiring extensive manual research.
The scope is unlimited!
Conclusion
In this article, we explored the mechanics of RAG with Langchain and Deep Lake, where semantic similarity plays a pivotal role in pinpointing relevant information. With vector databases, query vector generation, and vector-based retrieval, these models access external data precisely when needed.
The result? More precise, contextually appropriate responses enriched with proprietary data. Hope you liked it and learned something on your way! Feel free to download the complete code from my GitHub repo, to try it out.
Key Takeaways
- Introduction to RAG: Retrieval Augmented Generation (RAG) is a promising technique in Large Language Models (LLMs) that enhances their knowledge by adding extra information from their own data sources, making them smarter and reducing errors when they lack information.
- Challenges in Document QnA: Large Language Models have made significant progress in Document Question and Answering (QnA) but can sometimes struggle to discern when they lack information, leading to errors.
- RAG Pipeline: The RAG pipeline employs semantic similarity to identify relevant query information. It involves a Vector Database, Query Vector Generation, Vector-Based Retrieval, and Response Generation, ultimately providing more precise and contextually appropriate responses.
- Benefits of RAG: RAG allows models to provide evidence for the information they retrieve, reducing the need for frequent retraining in rapidly changing information scenarios.
- Practical Implementation: The article provides a practical guide to implementing the RAG pipeline, including setting up the project structure, creating a retrieval and embedding class, coding the retrieval pipeline, and building a Gradio app for real-time interactions.
Frequently Asked Questions
Q1: What is Retrieval Augmented Generation (RAG)?
A1: Retrieval Augmented Generation (RAG) is a cutting-edge technique used in Large Language Models (LLMs) that enhances their knowledge and reduces errors in document question-answering. It involves retrieving relevant information from data sources to provide context for generating accurate responses.
Q2: Why is RAG important for LLMs?
A2: RAG is important for LLMs because it helps them improve their performance by adding extra information from their data sources. This additional context makes LLMs smarter and reduces their mistakes when they lack sufficient information.
Q3: How does the RAG pipeline work?
A3: The RAG pipeline involves several steps:
Vector Database: Store documents in a specialized Vector Database, and each document is indexed based on a semantic vector generated by an embedding model.
Query Vector Generation: When you submit a query, the same embedding model generates a semantic vector representing the query.
Vector-Based Retrieval: The model uses vector search to identify documents in the database with vectors closely aligned with the query’s vector, pinpointing the most relevant documents.
Response Generation: After retrieving pertinent documents, the model combines them with the query to generate a response, accessing external data as needed. This process enhances the model’s internal knowledge.
Q4: What are the benefits of using the RAG approach?
A4: The RAG approach offers several benefits, including:
More Precise Responses: RAG enables LLMs to deliver more precise and contextually appropriate responses by incorporating proprietary data from vector-search-enabled databases.
Reduced Errors: By providing evidence for retrieved information, RAG reduces errors and eliminates the need for frequent retraining in rapidly changing information scenarios.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
An ace multi-skilled programmer whose major area of work and interest lies in Software Development, Data Science, and Machine Learning. A proactive and detail-oriented individual who loves data storytelling, and is curious and passionate to solve complex value-oriented business problems with Data Science and Machine Learning to deliver robust machine learning pipelines that ensure maximum impact.
In my free time, I focus on creating Data Science and AI/ML content, providing 1:1 mentorships, career guidance and interview preparation tips, with a sole focus on teaching complex topics the easier way, to help people make a successful career transition to Data Science with the right skillset!






