Introduction
While working extensively on SAS-EG, I lost touch of coding in Base SAS. I had to brush up my base SAS before appearing for my first lateral interview. SAS is highly capable of data triangulation, and what distinguishes SAS from other such languages is its simplicity to code.
There are some very tricky SAS questions and handling them might become overwhelming for some candidates. I strongly feel a need of a common thread which has all the tricky SAS questions asked in interviews. This article will give a kick start to such a thread. This article will cover 4 of such questions with relevant examples. This article is the first part of tricky SAS questions series. Please note that the content of these articles is based on the information I gathered from various SAS sources.
And if you’re looking to land your first data science role – look no further than the ‘Ace Data Science Interviews‘ course. It is a comprehensive course spanning tons of videos and resources (including a mammoth interview questions and answers guide).
[stextbox id=”section”]1. Merging data in SAS :[/stextbox]
Merging datasets is the most important step for an analyst. Merging data can be done through both DATA step and PROC SQL. Usually people ignore the difference in the method used by SAS in the two different steps. This is because generally there is no difference in the output created by the two routines. Lets look at the following example :
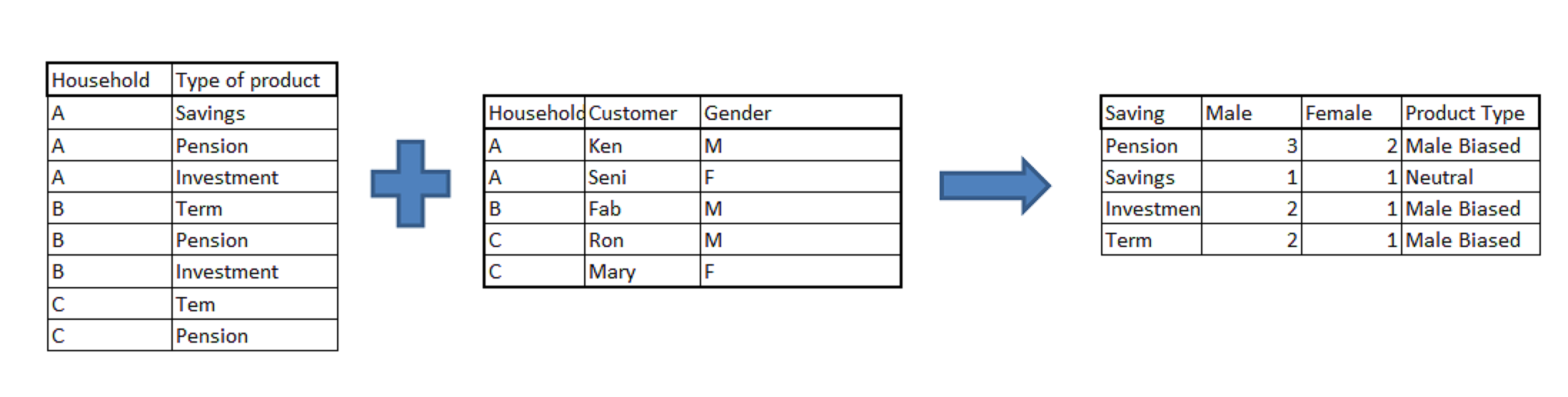
Problem Statement : In this example, we have 2 datasets. First table gives the product holding for a particular household. Second table gives the gender of each customer in these households. What you need to find out is that if the product is Male biased or neutral. The Male biased product is a product bought by males more than females. You can assume that the product bought by a household belongs to each customer of that household.
Thought process: The first step of this problem is to merge the two tables. We need a Cartesian product of the two tables in this case. After getting the merged dataset, all you need to do is summarize the merged dataset and find the bias.
Code 1
[stextbox id=”grey”]Proc sort data = PROD out =A1; by household;run;
Proc sort data = GENDER out =A2; by household;run;
Data MERGED;
merge A1(in=a) A2(in=b);
by household;
if a AND b;
run;[/stextbox]
Code 2 :
[stextbox id=”grey”]PROC SQL;
Create table work.merged as
select t1.household, t1.type,t2.gender
from prod as t1, gender as t2
where t1.household = t2.household;
quit; [/stextbox]
Will both the codes give the same result?
The answer is NO. As you might have noticed, the two tables have many-to-many mapping. For getting a cartesian product, we can only use PROC SQL. Apart from many-to-many tables, all the results of merging using the two steps will be exactly same.
Why do we use DATA – MERGE step at all?
DATA-MERGE step is much faster compared to PROC SQL. For big data sets except one having many-to-many mapping, always use DATA- MERGE.
[stextbox id=”section”]2. Transpose data-sets :[/stextbox]
When working on transactions data, we frequently transpose datasets to analyze data. There are two kinds of transposition. First, transposing from wide structure to narrow structure. Consider the following example :
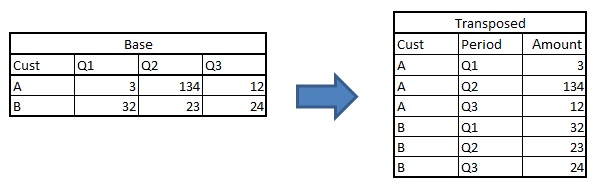
Following are the two methods to do this kind of transposition :
a. DATA STEP :
[stextbox id=”grey”]data transposed;set base;
array Qtr{3} Q:;
do i = 1 to 3;Period = cat('Qtr',i);Amount = Qtr{i} ;output;end;
drop Q1:Q3;
if Amount ne .;
run; [/stextbox]
b. PROC TRANSPOSE :
[stextbox id=”grey”]proc transpose data = base out = transposed
(rename=(Col1=Amount) where=(Amount ne .)) name=Period;
by cust; run; [/stextbox]
In this kind of transposition, both the methods are equally good. PROC TRANSPOSE however takes lesser time because it uses indexing to transpose.
Second, narrow to wide structure. Consider an opposite of the last example.
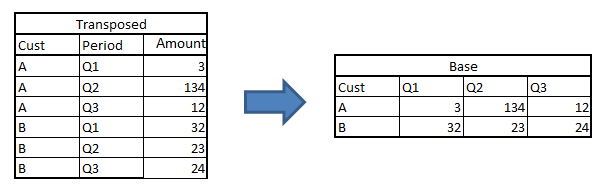
For this kind of transposition, data step becomes very long and time consuming. Following is a much shorter way to do the same task,
[stextbox id=”grey”]Proc transpose data=transposed out=base (drop=_name_) prefix Q;
by cust;
id period;
var amount;
run; [/stextbox]
[stextbox id=”section”]3. Passing values from one routine to other:[/stextbox]
Imagine a scenario, we want to compare the total marks scored by two classes. Finally the output should be simply the name of the class with the higher score. The score of the two datasets is stored in two separate tables.
There are two methods of doing this question. First, append the two tables and sum the total marks for each or the classes. But imagine if the number of students were too large, we will just multiply the operation time by appending the two tables. Hence, we need a method to pass the value from one table to another. Try the following code:
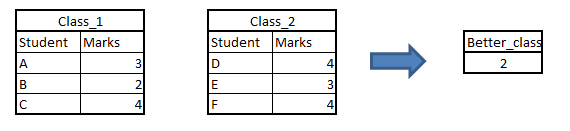
DATA _null_;set class_1;
total + marks;
call symputx ('class1_tot',total);
run;
DATA _null_;set class_2;
total + marks;
call symputx ('class2_tot',total);
run;
DATA results;
if &class1_tot > &class2_tot then better_class = 1;
else if &class1_tot > &class2_tot then better_class = 2;
else better_class = 0;
run; [/stextbox]
Funtion symputx creates a macro variable which can be passed between various routines and thus gives us an opportunity to link data-sets.
[stextbox id=”section”]4. Using where and if : [/stextbox]
“Where” and “if” are both used for sub-setting. Most of the times where and if can be used interchangeably in data step for sub-setting. But, when sub-setting is done on a newly created variable, only if statement can be used. For instance, consider the following two programs,
[stextbox id=”grey”]Code 1 : Code 2 :
data a;set b; data a;set b;
z= x+y; z= x+y;
if z < 10; where z < 10;
run; run; [/stextbox]
Code 2 will give an error in this case, because where cannot be used for sub-setting data based on a newly created variable.
[stextbox id=”section”]End Notes : [/stextbox]
These codes come directly from my cheat chit. What is especial about these 4 codes, that in aggregate they give me a quick glance to almost all the statement and options used in SAS. If you were able to solve all the questions covered in this article, we think you are up for the next level. You can read the second part of this article here ( https://www.analyticsvidhya.com/blog/2014/04/tricky-base-sas-interview-questions-part-ii/ ) . The second part of the article will have tougher and lengthier questions as compared to those covered in this article.
Have you faced any other SAS problem in analytics interview? Are you facing any specific problem with SAS codes? Do you think this provides a solution to any problem you face? Do you think there are other methods to solve the problems discussed in a more optimized way? Do let us know your thoughts in the comments below.
You can read part II of this article here.
If you like what you just read & want to continue your analytics learning, subscribe to our emails or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.






1. Merging data in SAS : is complete answer is Data A; Input household $ type_of_product $13.; Datalines; A savings A pension A investment B term B pension B investment C term C pension ; run; proc print; run; Data B; input household $ Customer $ gender $; datalines; A Ken M A Seni F B Fab M C Ron M C Mary F ; run; Proc sort data = a out =A1; by household;run; Proc sort data = b out =A2; by household;run; Data MERGED; merge A1(in=a) A2(in=b); by household; if a AND b; run; proc print data=merged; run; PROC SQL; Create table work.merged as select t1.household, t1.type,t2.gender from a as t1, b as t2 where t1.household = t2.household; quit; proc sort data=merged out=f; by type_of_product; run; data final; retain f 0; retain m 0; set f; by type_of_product; if gender="F" then f=f+1; if gender="M" then m=m+1; if last.type_of_product then do; if f>m then product_type="Female based"; else if m>f then product_type="Male based"; else product_type="Neutral"; output; f=0; m=0; end; drop household customer gender f m ; run; proc print data=final; run;
Question 1 answer Data A; Input household $ type_of_product $13.; Datalines; A savings A pension A investment B term B pension B investment C term C pension ; run; proc print; run; Data B; input household $ Customer $ gender $; datalines; A Ken M A Seni F B Fab M C Ron M C Mary F ; run; Proc sort data = a out =A1; by household;run; Proc sort data = b out =A2; by household;run; Data MERGED; merge A1(in=a) A2(in=b); by household; if a AND b; run; proc print data=merged; run; PROC SQL; Create table work.merged as select t1.household, t1.type,t2.gender from a as t1, b as t2 where t1.household = t2.household; quit; proc sort data=merged out=f; by type_of_product; run; data final; retain f 0; retain m 0; set f; by type_of_product; if gender="F" then f=f+1; if gender="M" then m=m+1; if last.type_of_product then do; if f>m then product_type="Female based"; else if m>f then product_type="Male based"; else product_type="Neutral"; output; f=0; m=0; end; drop household customer gender f m ; run; proc print data=final; run;
Hi! COMMENT to the answer to "4. Using where and if : " Suppose SAS-table B (WORK.B) contains a variable B, then the solution in Code 2 will work: data a;set b; z= x+y; /* The old value of Z, which was < 10, will be replaces. */ where z < 10; run; The WHERE-clause should (in my opinion) immediately follow the SET-statement. Easy question! Easy answer! Basic questions: What data do You have ? What rules do you have? What results do you want ? THEN we can start to discuss what is CORRECT and what is (perhaps) "a little less correct" (British English understatement). / Br Anders
Reply to answer 4 . Simple diff b/w IF and WHERE CLAUSE. IF works on pdv, where as WHERE works on source and applies conditions so new cant be created in WHERE. so there In code2 shows error.