Support Vector Machine – Simplified
The first time I heard the name “Support Vector Machine”, I felt, if the name itself sounds so complicated the formulation of the concept will be beyond my understanding. Luckily, I saw a few university lecture videos and realized how easy and effective this tool was. In this article, we will talk about how support vector machine works. This article is suitable for readers who do not know much about this algorithm and have a curiosity to learn a new technique. In following articles we will explore the technique in detail and analyze cases where such techniques are stronger than other techniques.

What is a classification analysis?
Let’s consider an example to understand these concepts. We have a population composed of 50%-50% Males and Females. Using a sample of this population, you want to create some set of rules which will guide us the gender class for rest of the population. Using this algorithm, we intend to build a robot which can identify whether a person is a Male or a Female. This is a sample problem of classification analysis. Using some set of rules, we will try to classify the population into two possible segments. For simplicity, let’s assume that the two differentiating factors identified are : Height of the individual and Hair Length. Following is a scatter plot of the sample.
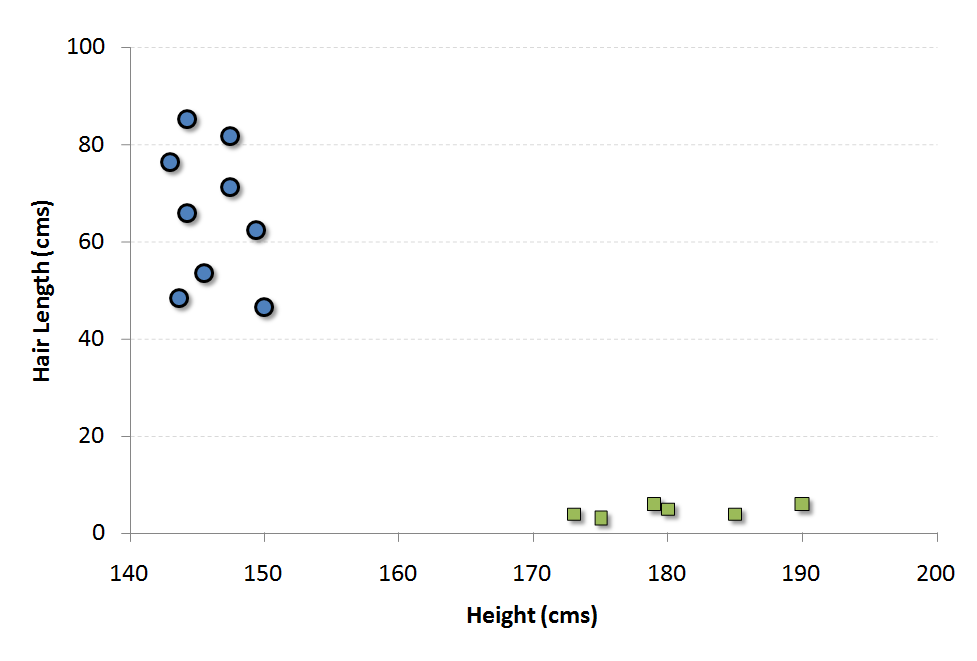 The blue circles in the plot represent females and green squares represents male. A few expected insights from the graph are :
The blue circles in the plot represent females and green squares represents male. A few expected insights from the graph are :
1. Males in our population have a higher average height.
2. Females in our population have longer scalp hairs.
If we were to see an individual with height 180 cms and hair length 4 cms, our best guess will be to classify this individual as a male. This is how we do a classification analysis.
What is a Support Vector and what is SVM?
Support Vectors are simply the co-ordinates of individual observation. For instance, (45,150) is a support vector which corresponds to a female. Support Vector Machine is a frontier which best segregates the Male from the Females. In this case, the two classes are well separated from each other, hence it is easier to find a SVM.
How to find the Support Vector Machine for case in hand?
There are many possible frontier which can classify the problem in hand. Following are the three possible frontiers.
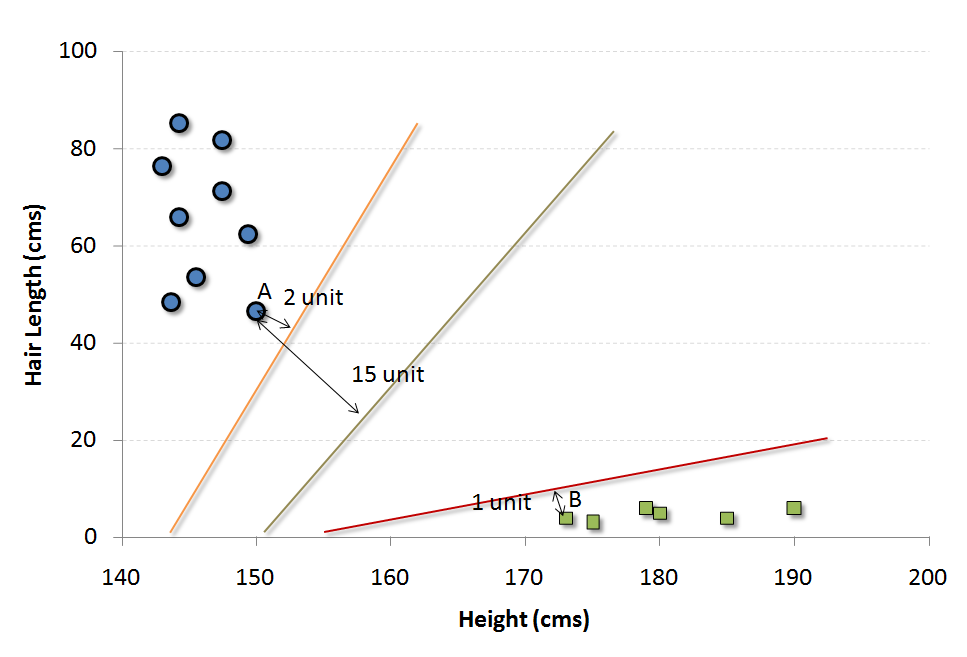
How do we decide which is the best frontier for this particular problem statement?
The easiest way to interpret the objective function in a SVM is to find the minimum distance of the frontier from closest support vector (this can belong to any class). For instance, orange frontier is closest to blue circles. And the closest blue circle is 2 units away from the frontier. Once we have these distances for all the frontiers, we simply choose the frontier with the maximum distance (from the closest support vector). Out of the three shown frontiers, we see the black frontier is farthest from nearest support vector (i.e. 15 units).
What if we do not find a clean frontier which segregates the classes?
Our job was relatively easier finding the SVM in this business case. What if the distribution looked something like as follows :
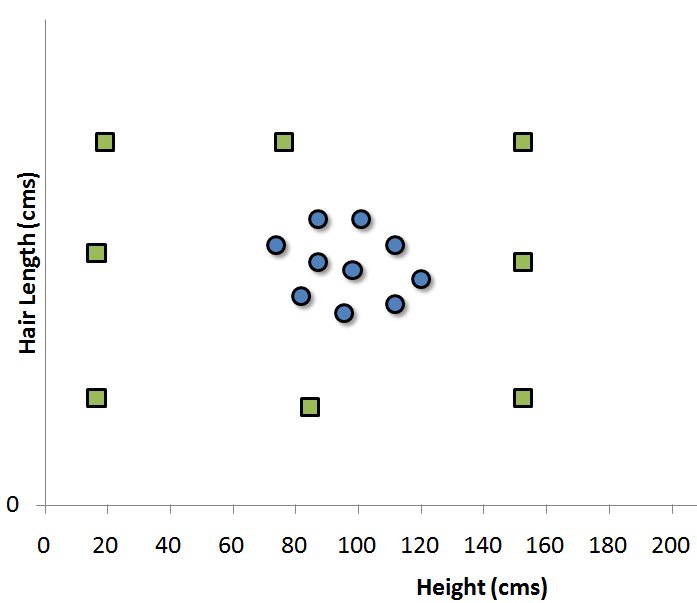
In such cases, we do not see a straight line frontier directly in current plane which can serve as the SVM. In such cases, we need to map these vector to a higher dimension plane so that they get segregated from each other. Such cases will be covered once we start with the formulation of SVM. For now, you can visualize that such transformation will result into following type of SVM.
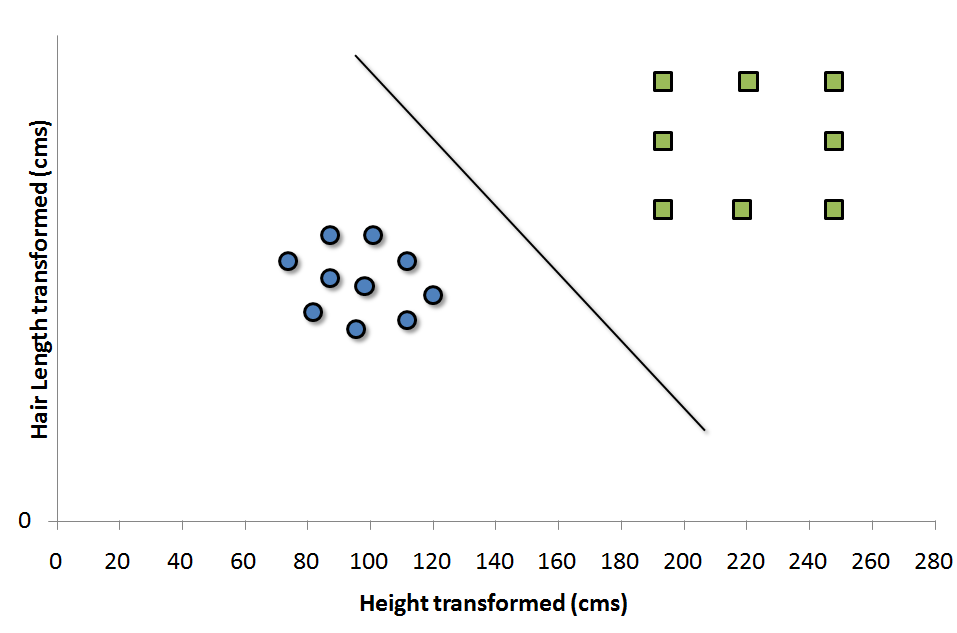
Each of the green square in original distribution is mapped on a transformed scale. And transformed scale has clearly segregated classes. Many algorithms have been proposed to make these transformations and some of which will be discussed in following articles.
End Notes
Support Vector Machines are very powerful classification algorithm. When used in conjunction with random forest and other machine learning tools, they give a very different dimension to ensemble models. Hence, they become very crucial for cases where very high predictive power is required. Such algorithms are slightly harder to visualize because of the complexity in formulation. You will find these algorithm very useful to solve some of the Kaggle problem statement.
Did you find the article useful? Have you used any other machine learning tool recently? How do you think SVM is different when compared to CART/CHAID models? Do you plan to use SVM in any of your business problems? If yes, share with us how you plan to go about it.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.








It is very useful for kaggle. With "svm" package in R; data required in numerical only. It is also useful for high dimensional data ; and also where dimensions are more than observations.
True that
SVM is a very powerful classification tool. SVM + Cover's theorem combination has been used many times. It all started with the XOR gate. It's wonderful to see the range of problems it can solve.
Give me some practical examples using R codes..
Sidshikur, We have a few articles in pipeline which will answer your query. Tavish
Thank you for this awesome and easy explanation. SVM always sounded very scary before you explained it so well.
Stay tuned for more detailed articles on SVM
Stay tuned for more detailed articles on SVM
Awesome explanation.Thank you
Do we have the next series of articles on SVM? I couldnt find any articles on SVM after this? Can you please help?
Great post! Really served to simplify my understanding. I have a request - could you please write a post about M5' algorithm as well?
Very easy to understand article. Thank you so much
can SVM also handle multiple clusters - eg customer segments (1 group may have only installed app, other have installed and visited, other may have installed and login , other may have also made a purchase but not visited? Can i provide multiple variable and then identify which variables to use for segmentation (like factor analysis)
Very Nice! Explanation. Everything very straightforward.
Would you please help me solve this question? How can I do with the training data if one feature of one sample is a vector while there are many features. The introduction of SVM in MATLAB shows, training data must be a "m x n" vector, in which "m" is the number of samples, "n" is the number of features, but if every sample has many features and every feature is a vector instead of a value, I don not know how to handle it.
Iam being a beginner much useful article.