Data exploration sets and developing a deep understanding of the data is one of the most important skills every data scientist should possess. People sometimes estimate that the time spent on these activities can go as high as 80% of the project time. Python has been gaining much ground as a preferred tool for data scientists lately, and for the right reasons. Ease of learning, powerful libraries with integration of C/C++, production readiness, and integration with the web stack are some of the main reasons for this move lately.
I will use NumPy, Matplotlib, Seaborn, and Pandas to explore data in this guide. These are powerful libraries that can perform data exploration in Python. The idea is to create a ready reference for some of the regular operations that are required frequently. I am using an iPython Notebook to perform data exploration and would recommend the same for its natural fit for exploratory analysis.
In case you missed it, I suggest you refer to the Python baby steps series to understand the basics of programming.
Input data sets can be in various formats (XLS, TXT, CSV, JSON ). Python makes it easy to load data from any source due to its simple syntax and availability of predefined libraries, such as Pandas. Here, I will use Pandas itself.
Pandas features many functions for reading tabular data as a Pandas DataFrame object. Below are the common functions that can be used to read data (including read_csv in Pandas):
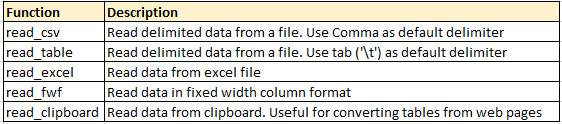
Code
Code df=pd.read_excel("E:/EMP.xlsx", "Data") # Load Data sheet of excel file EMP Output print df
Code:
df=pd.read_csv("E:/Test.txt",sep='\t') # Load Data from text file having tab '\t' delimeter print df
Converting a variable data type to others is an important and common procedure after loading data. Let’s look at some of the commands to perform these conversions:
srting_outcome = str(numeric_input) #Converts numeric_input to string_outcome integer_outcome = int(string_input) #Converts string_input to integer_outcome float_outcome = float(string_input) #Converts string_input to integer_outcome
The later operations are especially useful when you input value from user using raw_input(). By default, the values are read at string.
There are multiple ways to do this. The simplest would be to use the datetime library and strptime function. Here is the code:
from datetime import datetime char_date = 'Apr 1 2015 1:20 PM' #creating example character date date_obj = datetime.strptime(char_date, '%b %d %Y %I:%M%p') print date_obj
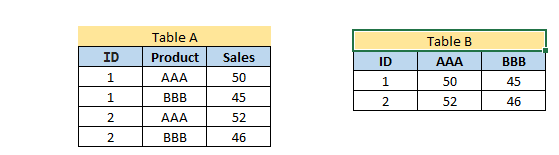
I want to transpose Table A into Table B on the variable Product. This task can be accomplished by using Pandas dataframe.pivot:
Code
#Transposing Pandas dataframe by a variable
df=pd.read_excel("E:/transpose.xlsx", "Sheet1") # Load Data sheet of excel file EMP
print df
result= df.pivot(index= 'ID', columns='Product', values='Sales')
result
Output

Data can be sorted using dataframe.sort() for data exploration in Python. It can be based on multiple variables and can be ascending or descending in both orders.
Code
#Sorting Pandas Dataframe
df=pd.read_excel("E:/transpose.xlsx", "Sheet1") #Add by variable name(s) to sort
print df.sort(['Product','Sales'], ascending=[True, False])
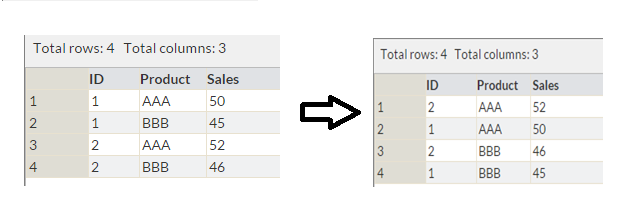
Above is a table with variables ID, Product, and Sales. Now, we want to sort it by Product and Sales (in descending order), as shown in Table 2.
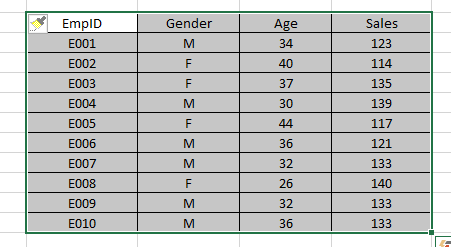
Data visualization helps us understand the data easily. Python has libraries like matplotlib and Seaborn to create multiple graphs effectively. Let’s look at some of the visualizations below to understand the behavior of the variable(s).
Code
#Plot Histogram
import matplotlib.pyplot as plt import pandas as pd
df=pd.read_excel("E:/First.xlsx", "Sheet1")
#Plots in matplotlib reside within a figure object, use plt.figure to create new figure fig=plt.figure()
#Create one or more subplots using add_subplot, because you can't create blank figure ax = fig.add_subplot(1,1,1)
#Variable ax.hist(df['Age'],bins = 5)
#Labels and Tit
plt.title('Age distribution')
plt.xlabel('Age')
plt.ylabel('#Employee')
plt.show()
Output
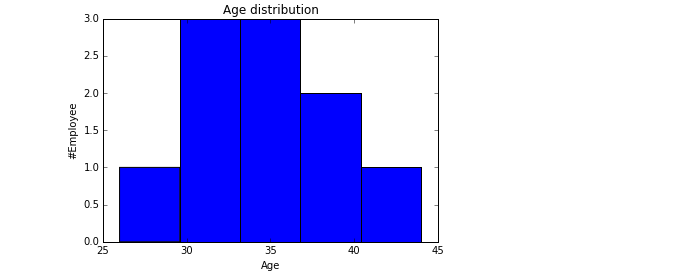
Code
#Plots in matplotlib reside within a figure object, use plt.figure to create new figure fig=plt.figure()
#Create one or more subplots using add_subplot, because you can't create blank figure ax = fig.add_subplot(1,1,1)
#Variable ax.scatter(df['Age'],df['Sales'])
#Labels and Tit
plt.title('Sales and Age distribution')
plt.xlabel('Age')
plt.ylabel('Sales')
plt.show()
Output
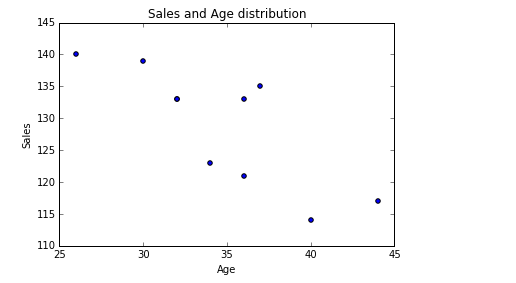
Code
import seaborn as sns sns.boxplot(df['Age']) sns.despine()
Output
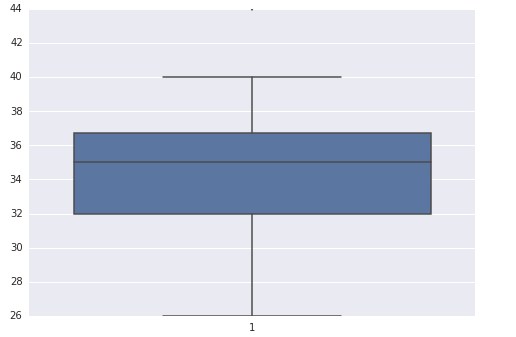
Frequency tables can be used to understand the distribution of categorical or n categorical variables using frequency tables.
Code
import pandas as pd
df=pd.read_excel("E:/First.xlsx", "Sheet1")
print df
test= df.groupby(['Gender','BMI']) test.size()
Output
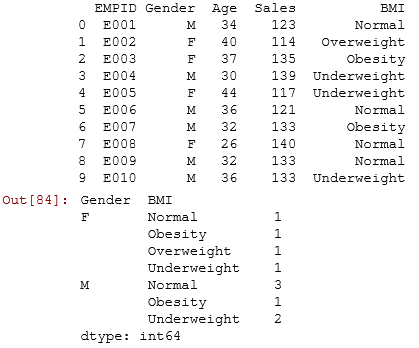
To select a sample from a data set, we will use the libraries numpy and random for data exploration in Python. Sampling data sets always helps us understand them quickly.
Let’s say, from the EMP table, I want to select a random sample of 5 employees.
Code
#Create Sample dataframe
import numpy as np import pandas as pd from random import sample
# create random index rindex = np.array(sample(xrange(len(df)), 5))
# get 5 random rows from the dataframe df dfr = df.ix[rindex] print dfr
Output
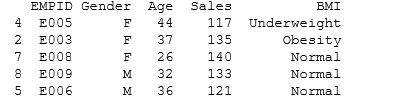
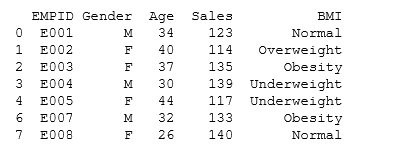
We often encounter duplicate observations. We can use the dataframe.drop_duplicates() to tackle this in Python.
Code
#Remove Duplicate Values based on values of variables "Gender" and "BMI"
rem_dup=df.drop_duplicates(['Gender', 'BMI']) print rem_dup
Output
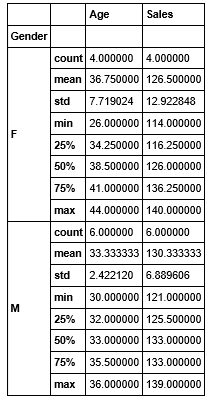
I suggest you use a dataframe to understand the count, average, and sum of variables. Describe () with Pandas groupby() in data exploration in Python.
Let’s look at the code:
Code
test= df.groupby(['Gender']) test.describe()
Output
To identify missing values , we can use dataframe.isnull(). You can also refer article “Data Munging in Python (using Pandas)“, here we have done a case study to recognize and treat missing and outlier values.
Code
# Identify missing values of dataframe
df.isnull()
Output

Various imputation methods are available to treat missing values. You can refer these articles for methods to detect Outlier and Missing values. Imputation methods for both missing and outlier values are almost similar. Here, we will discuss general case imputation methods to replace missing values. Let’s do it using an example:
#Example to impute missing values in Age by the mean import numpy as np meanAge = np.mean(df.Age) #Using numpy mean function to calculate the mean value df.Age = df.Age.fillna(meanAge) #replacing missing values in the DataFrame
Joining/merging is a common operation to integrate datasets from different sources for data exploration in Python. They can be handled effectively in Pandas using the merge function:
Code:
df_new = pd.merge(df1, df2, how = 'inner', left_index = True, right_index = True) # merges df1 and df2 on index # By changing how = 'outer', you can do outer join. # Similarly how = 'left' will do a left join # You can also specify the columns to join instead of indexes, which are used by default.
This comprehensive guide examined the Python codes for various data exploration in Python and munging steps. We also examined the Python libraries Pandas, Numpy, Matplotlib, and Seaborn to perform these steps. In the next article, I will reveal the codes to perform these steps in R.
A. Data exploration in Python involves using libraries like Pandas for data manipulation, Matplotlib and Seaborn for visualization, and NumPy for numerical operations. It includes loading data, examining data types, summary statistics, missing values, correlations, and distributions to understand data structure and detect patterns or anomalies.
A. The data exploration process involves collecting and analyzing data to understand its structure, quality, and patterns. Steps include data collection, cleaning (handling missing values and outliers), summarizing with descriptive statistics, visualizing distributions, relationships, and trends, and deriving initial insights for further analysis.
A. Exploratory Data Analysis (EDA) in Python entails using tools like Pandas, Matplotlib, and Seaborn to summarize data sets visually and statistically. It involves examining data distributions, spotting outliers, detecting patterns, and checking assumptions to form hypotheses and guide data preprocessing and modeling.
A. The EDA process includes several steps: data collection, Data cleaning (handling missing values and outliers), Data transformation, Generating summary statistics, Visualizing data distributions and relationships, Drawing initial conclusions, and Identifying the next steps for modeling or further analysis.
Sunil Ray is Chief Content Officer at Analytics Vidhya, India's largest Analytics community. I am deeply passionate about understanding and explaining concepts from first principles. In my current role, I am responsible for creating top notch content for Analytics Vidhya including its courses, conferences, blogs and Competitions. I thrive in fast paced environment and love building and scaling products which unleash huge value for customers using data and technology. Over the last 6 years, I have built the content team and created multiple data products at Analytics Vidhya. Prior to Analytics Vidhya, I have 7+ years of experience working with several insurance companies like Max Life, Max Bupa, Birla Sun Life & Aviva Life Insurance in different data roles. Industry exposure: Insurance, and EdTech Major capabilities: Content Development, Product Management, Analytics, Growth Strategy.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








Need the same thing/article in R. Please do need full asap. Thanks.
Hi Vikas, Guide for Data Exploration using R is live now. You can access it here http://www.analyticsvidhya.com/blog/2015/04/comprehensive-guide-data-exploration-r/ Thanks
About data imputation... I'm struggling to find methods (read packages / libraries) to carry out imputation in Python beyond the usual mean/ median approach...coming from an R background , there are tonnes of good packages to carry out very sophisticated imputation...this is something I miss in Python (it may be my lack of knowledge). i tried r2py to call imputation packages from R in python but it doesnt run as smoothly do you have suggestions in this regards?
Fantastic article with great examples! Thank you.
Great article. I learned something today. Any books which helps me to do these kind of data analysis?
good article
super
Nice article to start with Python.
Thank you so much. This was very helpful. :)
Nice summary Thank you.
Very Useful, covered all important data manipulation/exploration libraries, very handy.. !
Could you please provide the data sets that can be loaded directly to the code ? It will be really very helpful.
Where can we download the datasets referred to in the examples above? I'd like to replicate the steps exactly first before getting some other sample data. Thanks
AttributeError: 'DataFrame' object has no attribute 'sort'
Hi Anubhaw, Please use dataframe.sort_values().