Introduction
Don’t be a data scientist whose models fail to get deployed!
An epic example of model deployment failure is from Netflix Prize Competition. In a short story, it was an open competition. Participants had to build a collaborative filtering algorithm to predict user rating for films. The winners received grand prize of US$1,000,000. In the end, the complete model never got deployed.
Not just Netflix, such dramatic events occurs in most of the companies. Recently, I have been talking with C-Suite professionals of many leading analytics companies. The biggest concern I hear about is 50% of the predictive models don’t get implemented.
Would you want to build a model which doesn’t gets used in real world ? It’s like baking a cake which you’ve tasted and found wonderful but would never be eaten by anyone.
In this article, I have listed down all the possible reasons which you should keep in mind while building models. In my career, I’ve faced such situations many a times. Hence, I think my experience could help you in overcoming such situations.

8 Reasons For Model Deployments Failure
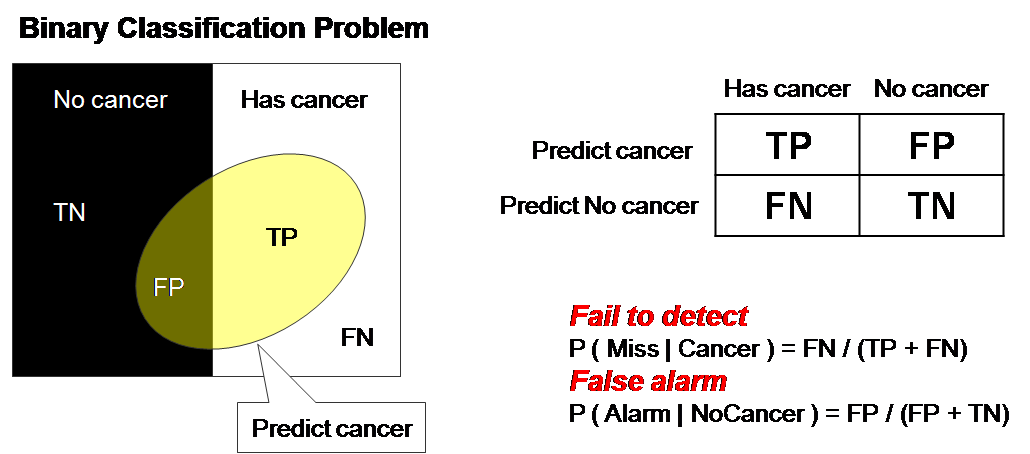
1. High amount of false positive : This might seem a bit technical. Here, it’s important to understand what is false positive?In a classification model, assume that we want to predict whether the customer is a responder (one who give answers) or a non-responder (one who doesn’t).
Imagine that you predict that a person X will be a responder but in reality he does not respond. Person X in this case is called a false positive. So how does this effect in real world ? I knew you would ask this question.
Let’s take an example. For instance, you have given the responsibility to build a retention campaign for 1000 customers. Out of these 1000, 100 customers will actually attrite (leave). You create an amazing model which has a 4X lift on top decile (10 equal large subsections).
This means, out of your top 100 predicted customers, 40 customers will actually attrite. So, you recommend the business to target all these 100 customers with a fascinating shopping offer which can stop them from attriting. But, here’s the challenge.
The challenge is that for every dollar you spend on each of these customers, only $0.4 get used to stop attrition. Rest $0.6 just go to false positive customers who were really not in a mood of attrition. This calculation will some times make these models less likely to be implemented as a result of negative P&L (Profit & Loss).
2. Low understanding of underlying models with business : Lately, there has been a rising requirement of using machine learning algorithms and more complex techniques for model building. In other words, companies are drifting away from using traditional models techniques.
Undoubtedly, using ML techniques lead to an incremental power of prediction, but the businesses are still not very receptive to such black box techniques. In my experience, this leads to a lot longer lead time for a predictive strategy to get implemented. And as most of the applications in business are highly dynamic, the model become more and more redundant with higher lead time. 
3. Not enough understanding of the business problem: Predictive models are good for resumes of both analyst and the business counterparts. However, that is not the purpose of the model you would build. In some cases, analyst run into creating model phase and try to cut down the time that should have been allotted to understanding the business problem.

4. Too complex models for implementation : Predictive power of models is the soul of these exercises. But in general, predictive power comes at a cost of complexity of models. We start bringing in bivariates and tri-variates to make models stronger, even when these variables make no sense as per business. Such models might be amazing in books, and hence, they just stay in these books and never see the actual light of real-world.

5. Not addressing the root cause just trying to improve the effect of a process : Why do we make models? The most important reason is to find the drivers of a particular response. What are these drivers? Drivers are always the root cause of response rate. What will happen if you bring in all the effects as the input variable and these variables also come out as significant? It will hardly be of any use as you are not changing things that can really bring changes .
 Source: ThinkReliability
Source: ThinkReliability
6. Training population significantly different from Scoring Population : In many cases, we end up creating models on a population which is significantly different from the actual population. For instance, if you are creating a campaign targeting population and you have no previous similar campaign. In such cases we start with the basic assumption that a population with high response rate might also have a high incremental response rate. But this assumption is rarely true and hence the model would be hardly used.
7. Unstable models : High performing models are often highly unstable and do not perform at par with time. In such cases, business might demand high frequency model revision. With higher lead time in model creation, business might start going back to intuition based strategy.

8. Models dependent on highly dynamic variables : Dynamic variable are those variables which bring in the real prediction power to the model. However, you might have a culprit variables which might bring in such values which have never been seen in training window.
For instance, you might get number of working days as a significant variable to predict monthly sales of a branch. Let’s say this variable is highly predictive. But for our scoring window, we have months which have just 10-15 working days. If your training data does not have any such month, your model might not be capable of making this prediction accurately.
End Notes
I believe if we do understand these challenges, we can think of better ways of not getting entangled with such catches. Also, knowing them makes us see what business is really looking out for. I welcome you to append this list which will make our analysis more comprehensive and take the team a step ahead.
Did you like reading this article ? Do share your experience / suggestions in the comments section below.
You can test your skills and knowledge. Check out Live Competitions and compete with best Data Scientists from all over the world.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.






Good job Tavish, thank you !
Hi Sounds like a complaint on a data scientist job. Sounds demoralizing LOL I do agreed with your points. and I hope analytics won't become a dot-net bubble. It is better to start small scale and bring small value (let's call it SMALL DATA analytics), than to do BIG DATA analytics which will end up in black hole. .Honestly, when I do my own mini projects and as I came across many algorithms, I start asking myself : what does the better algorithm provide in incremental value ? Maybe I end up more confused ! Worst, people who are non-believer of analytics will always disagree with people like us.
Nice article Tavish.