Introduction
Proof of the pudding lies in the eating. It takes working on the Deep network and witness it progressively produce good accuracy, to be truly amazed by the power of a Deep neural network. Using Deep Learning in a competitive environment requires all the more (as opposed to research) understanding of its strengths and costs. This is due to time boundedness and hence limited possibilities for experimentation.
In this blog, we narrate our experience in using Deep Learning to achieve qualifying accuracy for a preliminary round of the International Data Science Game 2016. We are one of the 20 teams which qualified for the final round of the competition at Paris. We begin with a brief description of the problem statement, move through methodology and the implementation. We close the article, with few points from a panel discussion from the final event on the theme “Does Deep Learning mark the end of conventional Feature Engineering?”
Most of the online resources on deep learning are focussed on helping the reader getting started. In this blog, we go a step ahead and discuss the use of Deep learning on a real life image Dataset. The analyses of this Dataset has potential applications in solar energy harness. The underlying idea is to bring out practical aspect of the much-discussed-in-theory-concepts like Data Augmentation and Semi-supervised learning.

About Data Science Game
Data Science Game is an International Inter-University student team challenge, hosted by the Data Science Game Organization. The competition was conducted in 2 phases, an online preliminary round and a final face off in Paris. In the preliminary round, 143 teams coming from universities from 28 countries competed, with top 20 teams qualifying for the second round. The phase 2 of the competition involved a fresh data science problem over 2 days.
The competition had two phases, the first phase was an online competition held in from June 17 to July 10. The participants were required to solve a real life business challenge. The participants were required to solve a predictive problem containing complex data, with the help of statistical algorithms. The second phase of the competition was held in Paris held on September 10th & 11th, where top 20 teams competed in a machine learning challenge.
Phase 1
Initial Participation
The initial participation included 143 teams participating more than 50 universities from 28 countries. The participants were tested on a real-life business challenge. It was an online round and all participants were tested on their data science skills.
Challenge Details
The participants were provided a computer vision problem. In France, OpenSolarMap provides satellite images of roof of 80,000 houses to find out the potential of solar energy production. Over 15,000 roof orientation have been collected by the company but they are facing an issue to automatically classify the orientation of roof. To tackle this problem, the participants were required to build an algorithm to test recognise the roof orientation from a satellite image.
Phase 2
The top 20 finalists from the Phase 1 were invited to Paris for the final round of the competition. All the participants were welcomed at Capgemini’s Les Fontaines campus. There were around 80 students waiting to compete for the Data Science Champion title.
Competition Challenge
The problem set for the final round was based on an Automobile Insurance quotes received by Axa. In this, the participants had to predict if a person who requested a given quote bought the associated insurance policy. The participated were provided free access to Microsoft’s Azure computing clusters. The hackathon lasted for 30-hours and the performance measure used was log-loss.
Now, we will be discussing the problem set from Phase 1 and what approach did we take. Read on, to know our complete approach.
About the hackathon
Problem set for the preliminary round comprised of classification of satellite images of rooftops into 4 classes as shown below. Training dataset comprised of 8000 images in the ratio of 4:2:1:2 for the classes North-South, East-West, Flat and Other. Evaluation was based on classification accuracy on 14000 images. In addition to the training and the test dataset there were 22000 unmarked images.

North-South

East-West

Flat

Other
The use of Convolutional Neural Network helped us beat the accuracy of conventional methodologies. Case specific data augmentation strategies, semi-supervised learn ing and ensembling of numerous models were instrumental in achieving the qualification benchmark for accuracy. Many of these ideas evolved as a result of extensive experimentation with the data. “In a data science competition you either go up or down”. Hence, it is important to continuously experiment during the course of the competition.
Detailed Approach
1. Methodology
Before discussing our approach based on Deep Learning, we must pay respect to another school of thought, which employs supervised and unsupervised models with engineered features on available data as input. At the opening ceremony of the final round, the organizers announced that the problem of the prelim round could have been solved at 79% accuracy merely using multi-logit regression and feature engineering. It was a surprise to see such accuracy coming from the use of simple model. Hence we realized that it is less of Deep Learning versus Conventional Models, but more of Deep Learning versus the human ability to create distinguishing features in classification in cases of high level Data representation.
Indeed, the problem given was dealing with images. A very generic representation of events and intuitive methods of generating granular features (for example, detecting presence of edges, finding contrast gradient, common shape identification) lead to an incoherent description of the image, which failed to capture all characteristic features. If these features are not good they can end up confusing the learner.
Since a quantum leap was required to capture the higher level of abstraction present in the data like complex edge patterns, shapes, different color blobs etc., it was needed to choose a model which can bring in the complexity in feature generation. The feature generation process is eventually automated and tuned to reduce the training error as minimum as possible. We turned to Convolutional Neural Networks.
Convolutional image networks are sparsely connected neural networks, with enhanced feature generation capabilities over the conventional image processing techniques. Deep Learning enables higher degree of abstraction. With Convolutional neural network, we could achieve a single model accuracy of approximately 80% and 82%. The team scoring highest achieved accuracy of 86%.
Accuracy in a Deep Learning model is extremely sensitive to the volume of training data. With higher number of training examples, the generalization increases. We followed different data augmentation strategies. For example, adding noise to the image, images obtained by rotating original images, cropped portion of original images, 90 Degree rotation of the North-South and East-West Images. This process eventually generated another set of images those were almost similar to previous images but not completely. The added noise in those image data increased the information content and hence learner got new examples to learn. This way, the effective training data comprised of nearly 10 times the images provided in the original training data.
Event organizers used crowdsourcing methods to mark the images in the training dataset. Since crowd sourced experimentation involves much time and cost, it is extremely likely to have large number of unlabeled data points. The whole data set consisted of 22, 000 unlabeled images, with potential of meaningful information for the Neural Network. Our strategy was to label the images, using the already trained network, with a hope that the volume advantage of having increased dataset for training is more than losses due to noise in the added dataset. Use of semi-supervised learning which allowed us to witness a clear break from our accuracy saturation and we left the plateau to climb up in the leaderboard. Till that point, our model was giving an accuracy of 78% on the validation set. We used an ensemble of models to predict the classes for the unlabeled images. The different models in the ensemble came from local minima of validation error. Finally, a majority vote over 10 models was a deciding call for a class to be attached to an unlabeled image. With lower variance due to bagging, we have certainly identified 80% of the unlabeled images correctly. The new information was again fed to the already trained network, resulting in accuracy improvement of 2-4%. Even the small increase in accuracy at this stage was critical since it was in the range where most of the top models at that time were. The overall experience shows the power of a Deep network acting as an oracle in deciding about the labels for unlabeled data and in turn using that imparted knowledge to make itself better learnt.
To decrease the variance in prediction, it is advisable to use ensemble of learners to predict. As by the construct of the experiment, every time the network have been fed by a slightly different but bigger dataset, in different instances of training, it is possible to store different models which have potential to predict with almost similar accuracy. It has been thoroughly checked that these models indeed perform well on different segments of validation data. The difference in learning is caused by different updates of network weights across learning phases. The advantage of using Deep Network is that with slight variation in training data can tweak the optimization of minimizing training error and can lead to similar local optima with a different set of parameter (weights here) value. We also created ensemble of ensembles with proportional weights to their individual accuracy. This strategy boosted our performance by 2%, which again was quite critical at that stage.
2. Implementation
To implement the CNN model we used Keras, which is a Deep Learning library in Python. It was the natural choice for us since numerous tutorial and codes for Deep Learning on Keras were available online. Some of the benefits of using Keras based on our experience were
- Simplified and intuitive network building
- Inbuilt Data Augmentation Features
- Utilizes Graphics Processing Unit
Images in the raw dataset were of non-uniform sizes. We decided to convert all the images to 128 * 128 Pixel as 128 was the approximate median of both length and breadth, since this would minimize information loss for most images. To fill empty portions within images left after resizing we used bilinear interpolation. For Image processing we used the OpenCV Package in Python. To verify our choice of the optimal size for images, we trained a simple network on 64*64 pixel images and 128*128 pixel images. We observed higher accuracy in the later, even though it came at the cost of higher training time.
The ImageDataGenerator function simplifies the process of feeding data to the network. It automatically reads the training and validation images from the respective folders. The class should name the folders containing the images.
In the limited time scenario of the competition, time taken to transfer train images within folders can be significant. The number of Train images increased even more after semi-supervised learning and further increased due to Data augmentation. To minimize the time going into transfer of large number of files, we used scripts in command line as well as the Shuttl module in python. The file transfer time was an important concern, since we had to do Image Preprocessing and Model Training on different computers, and hence first files had to be transferred to USB and from USB to other computer.
Attached below is a snippet of the Network build on Keras.
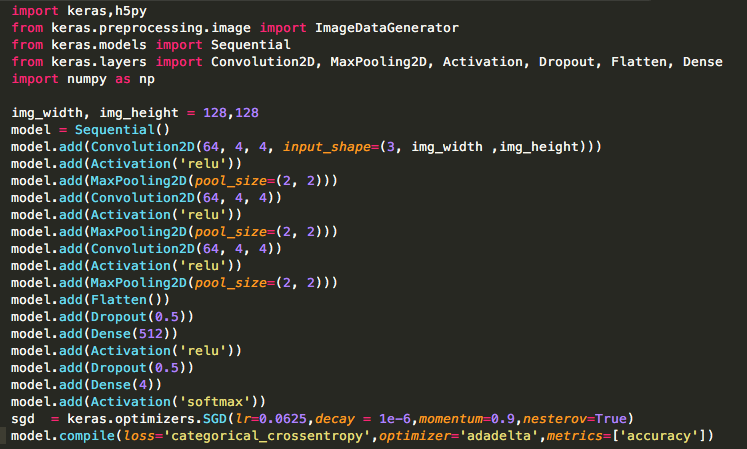
As the training dataset size increased via Augmentation strategies and Semi-Supervised learning, training time per epoch started to explode to an extent that it was difficult to decide the point of termination of the training. With more time per epoch, to be sure of the point of divergence of the validation error and training error, more time had to be spent per experimentation. To give an estimate of the epoch time, on a 8GB RAM machine with AMD M380 GPUs (96 GB/s) one epoch used to take half an hour on the 8000 images dataset. This time increased up to 3 hours for one epoch with augmented data. Typically the network would take 15-20 epochs to train. To some extent, this time can be minimized by generating images for augmentation on the fly in keras, which is primarily due to less time required for seeking files on the disk.
The beginning of the final round of the competition was marked by a panel discussion on the lines of Deep Learning versus Conventional Algorithms. The speakers were Data Science heads of large organizations and academicians, and hence it was natural to expect thought provoking takeaways. Where at one end Deep learning has solved numerous challenges and opened doors to new possibilities, the importance of conventional methods, which focus on understanding data generation process, cannot be given less importance. Numerous applications of Data Science in industry strongly depend upon the interpretability of the underlying algorithm in addition to high accuracy. Very relevant here are the developments in programming, where despite massive leaps in higher level languages, low level languages like C# are indispensable in certain applications. Analogous to the scenario in programming, simple models combined with feature engineering will continue to have a very important position. Moreover, high accuracy in Deep learning is not without a skillful Data Scientist and hence Deep learning is not a replacement for skills of a Data Scientist. Summarizing, it is important to be aware of the power of Deep learning but a complete reliance is unadvisable.
End Note
We hope you enjoyed reading this article.We are grateful to share our approach with you all to enhance learning and add more material on Deep Learning. If you have any questions or doubts, drop in your comments below.
About the Authors

Robin Singh

Bodhisattwa Majumder
The authors are Robin Singh skilled in machine learning, complex networks & information retrieval and Bodhisattwa Prasad Majumder skilled in machine learning, distributed computing & information retrieval. They both are students of Post Graduate Diploma in Business Analytics by ISI Kolkata, IIT Kharagpur and IIM Calcutta.
Their teammates who participated in the Data Science Game challenge together with them are Ayan Sengupta and Jayanta Mandi.
Disclaimer: Our stories are published as narrated by the community members. They do not represent Analytics Vidhya’s view on any product / services / curriculum.






I'm just leaving to tell you how happy I am to see such an experience being shared. I'm a beginner in data science, and I feel amazed by all the things that can achieved by a good team of data scientists. Hence, this article was such a big view of the actual, real-life application of data science knowledge, that I could not find anywhere else. Thank you so much! Keep up the good work!
*that can be achieved(...)
Thanks Diego! Connect for more details! :)