K-Nearest Neighbours (KNN) and tree-based algorithms are two of the most intuitive and easy-to-understand machine learning algorithms. Both are simple to explain and demonstrate, making them perfect for those who are new to the field. For beginners, it is crucial to test their knowledge of these algorithms as they are simplistic yet immensely powerful. These are commonly asked in interviews as well. Searching for KNN interview questions and practicing them can help one gain a deeper understanding of the algorithm and its practical applications. In this article, we are explaining the top 30 KNN interview questions or KNN MCQS that help you to succeed in the interview.
1) [True or False] k-NN algorithm does more computation on test time rather than train time.
A) TRUE B) FALSE
Solution: A
The training phase of the algorithm consists only of storing the feature vectors and class labels of the training samples.In the testing phase, a test point is classified by assigning the label which are most frequent among the k training samples nearest to that query point – hence higher computation.
2) In the image below, which would be the best value for k assuming that the algorithm you are using is k-Nearest Neighbor.
A) 3 B) 10 C) 20 D 50
Solution: B
Validation error is the least when the value of k is 10. So it is best to use this value of k
A) Manhattan B) Minkowski C) Tanimoto D) Jaccard E) Mahalanobis F) All can be used
Solution: F
All of these distance metric can be used as a distance metric for k-NN.
–
4) Which of the following option is true about k-NN algorithm?
A) It can be used for classification B) It can be used for regression C) It can be used in both classification and regression
Solution: C
We can also use k-NN for regression problems. In this case the prediction can be based on the mean or the median of the k-most similar instances.
5) Which of the following statement is true about k-NN algorithm?
k-NN performs much better if all of the data have the same scale
k-NN works well with a small number of input variables (p), but struggles when the number of inputs is very large
k-NN makes no assumptions about the functional form of the problem being solved
A) 1 and 2 B) 1 and 3 C) Only 1 D) All of the above
Solution: D
The above mentioned statements are assumptions of KNN algorithm
6) Which of the following machine learning algorithm can be used for imputing missing values of both categorical and continuous variables?
A) K-NN B) Linear Regression C) Logistic Regression
Solution: A
k-NN algorithm can be used for imputing missing value of both categorical and continuous variables.
7) Which of the following is true about Manhattan distance?
A) It can be used for continuous variables B) It can be used for categorical variables C) It can be used for categorical as well as continuous D) None of these
Solution: A
Manhattan Distance is designed for calculating the distance between real valued features.
8) Which of the following distance measure do we use in case of categorical variables in k-NN?
Hamming Distance
Euclidean Distance
Manhattan Distance
A) 1 B) 2 C) 3 D) 1 and 2 E) 2 and 3 F) 1,2 and 3
Solution: A
Both Euclidean and Manhattan distances are used in case of continuous variables, whereas hamming distance is used in case of categorical variable.
9) Which of the following will be Euclidean Distance between the two data point A(1,3) and B(2,3)?
A) 1 B) 2 C) 4 D) 8Solution: A
sqrt( (1-2)^2 + (3-3)^2) = sqrt(1^2 + 0^2) = 1
10) Which of the following will be Manhattan Distance between the two data point A(1,3) and B(2,3)?
A) 1 B) 2 C) 4 D) 8Solution: A
sqrt( mod((1-2)) + mod((3-3))) = sqrt(1 + 0) = 1
Context: 11-12
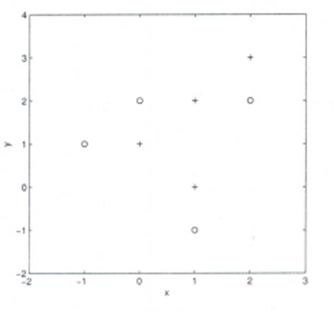
Suppose, you have given the following data where x and y are the 2 input variables and Class is the dependent variable.
Below is a scatter plot which shows the above data in 2D space.
11) Suppose, you want to predict the class of new data point x=1 and y=1 using eucludian distance in 3-NN. In which class this data point belong to?
A) + ClassB) – ClassC) Can’t say
D) None of these
Solution: A
All three nearest point are of +class so this point will be classified as +class.
12) In the previous question, you are now want use 7-NN instead of 3-KNN which of the following x=1 and y=1 will belong to?
A) + ClassB) – ClassC) Can’t saySolution: B
Now this point will be classified as – class because there are 4 – class and 3 +class point are in nearest circle.
Context 13-14:
Suppose you have given the following 2-class data where “+” represent a postive class and “” is represent negative class.
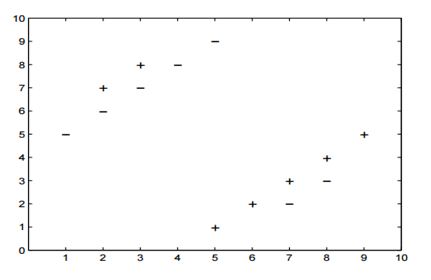
13) Which of the following value of k in k-NN would minimize the leave one out cross validation accuracy?
A) 3 B) 5 C) Both have same D) None of theseSolution: B
5-NN will have least leave one out cross validation error.
14) Which of the following would be the leave on out cross validation accuracy for k=5?
A) 2/14 B) 4/14 C) 6/14 D) 8/14 E) None of the aboveSolution: E
In 5-NN we will have 10/14 leave one out cross validation accuracy.
15) Which of the following will be true about k in k-NN in terms of Bias?
A) When you increase the k the bias will be increases B) When you decrease the k the bias will be increases C) Can’t say D) None of theseSolution: A
large K means simple model, simple model always condider as high bias
16) Which of the following will be true about k in k-NN in terms of variance?
A) When you increase the k the variance will increases B) When you decrease the k the variance will increases C) Can’t say D) None of theseSolution: B
Simple model will be consider as less variance model
17) The following two distances(Eucludean Distance and Manhattan Distance) have given to you which generally we used in K-NN algorithm. These distance are between two points A(x1,y1) and B(x2,Y2).Your task is to tag the both distance by seeing the following two graphs. Which of the following option is true about below graph ?
A) Left is Manhattan Distance and right is euclidean Distance B) Left is Euclidean Distance and right is Manhattan Distance C) Neither left or right are a Manhattan Distance D) Neither left or right are a Euclidian DistanceSolution: B
Left is the graphical depiction of how euclidean distance works, whereas right one is of Manhattan distance.
18) When you find noise in data which of the following option would you consider in k-NN?
A) I will increase the value of k B) I will decrease the value of k C) Noise can not be dependent on value of k D) None of theseSolution: A
To be more sure of which classifications you make, you can try increasing the value of k.
19) In k-NN it is very likely to overfit due to the curse of dimensionality. Which of the following option would you consider to handle such problem?
Dimensionality Reduction
Feature selection
A) 1 B) 2 C) 1 and 2 D) None of these
Solution: C
In such case you can use either dimensionality reduction algorithm or the feature selection algorithm
20) Below are two statements given. Which of the following will be true both statements?
k-NN is a memory-based approach is that the classifier immediately adapts as we collect new training data.
The computational complexity for classifying new samples grows linearly with the number of samples in the training dataset in the worst-case scenario.
A) 1 B) 2 C) 1 and 2 D) None of these
Solution: C
Both are true and self explanatory
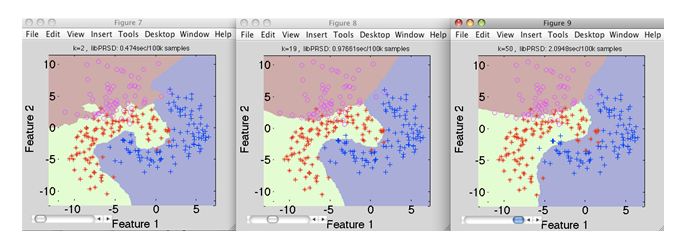
21) Suppose you have given the following images(1 left, 2 middle and 3 right), Now your task is to find out the value of k in k-NN in each image where k1 is for 1st, k2 is for 2nd and k3 is for 3rd figure.
A) k1 > k2> k3 B) k1<k2 C) k1 = k2 = k3 D) None of theseSolution: D Value of k is highest in k3, whereas in k1 it is lowest
22) Which of the following value of k in the following graph would you give least leave one out cross validation accuracy?
A) 1 B) 2 C) 3 D) 5Solution: B
If you keep the value of k as 2, it gives the lowest cross validation accuracy. You can try this out yourself.
23) A company has build a KNN classifier that gets 100% accuracy on training data. When they deployed this model on client side it has been found that the model is not at all accurate. Which of the following thing might gone wrong?
Note: Model has successfully deployed and no technical issues are found at client side except the model performance
A) It is probably a overfitted model B) It is probably a underfitted model C) Can’t say D) None of theseSolution: A
In an overfitted module, it seems to be performing well on training data, but it is not generalized enough to give the same results on a new data.
24) You have given the following 2 statements, find which of these option is/are true in case of k-NN?
In case of very large value of k, we may include points from other classes into the neighborhood.
In case of too small value of k the algorithm is very sensitive to noise
A) 1 B) 2 C) 1 and 2 D) None of these
Solution: C
Both the options are true and are self explanatory.
25) Which of the following statements is true for k-NN classifiers?
A) The classification accuracy is better with larger values of k B) The decision boundary is smoother with smaller values of k C) The decision boundary is linear D) k-NN does not require an explicit training stepSolution: D
Option A: This is not always true. You have to ensure that the value of k is not too high or not too low.
Option B: This statement is not true. The decision boundary can be a bit jagged
Option C: Same as option B
Option D: This statement is true
26) True-False: It is possible to construct a 2-NN classifier by using the 1-NN classifier?
A) TRUE B) FALSESolution: A
You can implement a 2-NN classifier by ensembling 1-NN classifiers
27) In k-NN what will happen when you increase/decrease the value of k?
A) The boundary becomes smoother with increasing value of K B) The boundary becomes smoother with decreasing value of K C) Smoothness of boundary doesn’t dependent on value of K D) None of theseSolution: A The decision boundary would become smoother by increasing the value of K
28) Following are the two statements given for k-NN algorthm, which of the statement(s)
is/are true?
We can choose optimal value of k with the help of cross validation
Euclidean distance treats each feature as equally important
A) 1 B) 2 C) 1 and 2 D) None of these
Solution: C
Both the statements are true
Context 29-30:
Suppose, you have trained a k-NN model and now you want to get the prediction on test data. Before getting the prediction suppose you want to calculate the time taken by k-NN for predicting the class for test data. Note: Calculating the distance between 2 observation will take D time.
29) What would be the time taken by 1-NN if there are N(Very large) observations in test data?
A) N*D B) N*D*2 C) (N*D)/2 D) None of theseSolution: A
The value of N is very large, so option A is correct
30) What would be the relation between the time taken by 1-NN,2-NN,3-NN.
A) 1-NN >2-NN >3-NN B) 1-NN < 2-NN < 3-NN C) 1-NN ~ 2-NN ~ 3-NN D) None of theseSolution: C
The training time for any value of k in KNN algorithm is the same.
Helpful Resources for KNN Interview
Here are some resources to get in depth knowledge in the subject.
If you are just getting started with Machine Learning and Data Science, here is a course to assist you in your journey to Master Data Science and Machine Learning. Check out the detailed course structure in the link below:
Understand the Basics: Before the interview, make sure you have a strong understanding of the basics of the KNN algorithm. Review the key concepts such as distance metrics, k-value selection, and the curse of dimensionality.
Know the Applications: KNN has a variety of practical applications, including image recognition, recommender systems, and anomaly detection. Make sure you have a good understanding of these applications and how KNN is used in each of them.
Prepare for Technical Questions: Be prepared to answer technical questions related to KNN, such as how to choose the optimal value of k, how to handle imbalanced data, and how to deal with missing data. Look up KNN interview questions online to get a sense of the types of questions that may be asked.
Demonstrate your Problem-solving Skills: Be prepared to walk through a problem-solving exercise using KNN. This could include a real-world scenario or a hypothetical problem. Walk the interviewer through your thought process and explain how you would approach the problem using KNN.
Practice, Practice, Practice: The best way to prepare for a KNN interview is to practice. Search for KNN interview questions and practice answering them. Consider working through example problems or participating in data science competitions to improve your KNN skills.
End Notes
Being prepared for KNN interview questions is crucial for anyone looking to enter the field of data science or machine learning. Understanding the basics of the KNN algorithm, its practical applications, and how to handle technical questions can help you demonstrate your knowledge and problem-solving skills. By practicing KNN interview questions and working through example problems, you can improve your understanding and feel more confident during the interview process. With these tips in mind, you can approach KNN interviews with confidence and set yourself up for success in your data science career.
Sunil Ray is Chief Content Officer at Analytics Vidhya, India's largest Analytics community. I am deeply passionate about understanding and explaining concepts from first principles. In my current role, I am responsible for creating top notch content for Analytics Vidhya including its courses, conferences, blogs and Competitions.
I thrive in fast paced environment and love building and scaling products which unleash huge value for customers using data and technology. Over the last 6 years, I have built the content team and created multiple data products at Analytics Vidhya.
Prior to Analytics Vidhya, I have 7+ years of experience working with several insurance companies like Max Life, Max Bupa, Birla Sun Life & Aviva Life Insurance in different data roles.
Industry exposure: Insurance, and EdTech
Major capabilities: Content Development, Product Management, Analytics, Growth Strategy.
Answer to Q 12 should be + class. All together there are 8 observation 4 of - and 4 of+. But the nearest ones for 1,1 is +
Ikwuoche John David
13 Sep, 2017
Lovely test. Please, can I get the soft copy of the questions & answers for both the KNN & TREE Algorithms to my email?: [email protected].
Anubhav
05 Oct, 2017
Answers to Q 25 & 27 are bit contradictory
Nenad
01 May, 2018
10 is wrong.
Mandell
21 Dec, 2021
I am relatively new Data science in python and was exploring some competition on data science, i am getting confused with "Training data Set" and "Test Data Set" . Some projects have merged both and some they have kept separate. What is the rationale behind having two data sets. Any advise will be helpful thanks
quentin
13 Sep, 2023
Helpful. Even better would be masked answers think spoilers. This would ensure one could scroll without seeing the answer by mistake.
slideshare downloader
28 Apr, 2024
Wow, this is an incredibly comprehensive list of KNN interview questions! As a data scientist, I can attest to the importance of understanding KNN and its applications. The questions in this post are exactly what I need to prepare for my next interview. Thank you for sharing!
We use cookies on Analytics Vidhya websites to deliver our services, analyze web traffic, and improve your experience on the site. By using Analytics Vidhya, you agree to our Privacy Policy and Terms of Use.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.



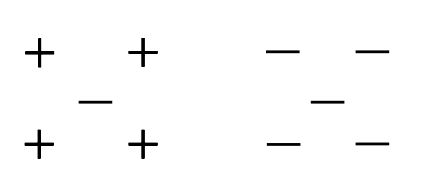








WOW !! Nice Sir, Thankyou.
Answer to Q 12 should be + class. All together there are 8 observation 4 of - and 4 of+. But the nearest ones for 1,1 is +
Hi Sasikanth, There was a typo in the questions. I have updated the same, thanks for the feedback
Lovely test. Please, can I get the soft copy of the questions & answers for both the KNN & TREE Algorithms to my email?: [email protected].
Answers to Q 25 & 27 are bit contradictory
Hi Anubhav, Answer to Q 25 is that the decision boundary can be a bit jagged( not smooth when k is small). Whereas the answer to Q25 is that the decision boundary is smooth for large values of k.
10 is wrong.
Hi Nenad, Answer to question 10 will be 1. As manhattan distance is the sum of absolute difference of the vectors. So it will be [mod(1-2) + mod(3-3)] =1
I am relatively new Data science in python and was exploring some competition on data science, i am getting confused with "Training data Set" and "Test Data Set" . Some projects have merged both and some they have kept separate. What is the rationale behind having two data sets. Any advise will be helpful thanks
Helpful. Even better would be masked answers think spoilers. This would ensure one could scroll without seeing the answer by mistake.
Wow, this is an incredibly comprehensive list of KNN interview questions! As a data scientist, I can attest to the importance of understanding KNN and its applications. The questions in this post are exactly what I need to prepare for my next interview. Thank you for sharing!