Build High Performance Time Series Models using Auto ARIMA in Python and R
Introduction
Picture this – You’ve been tasked with forecasting the price of the next iPhone and have been provided with historical data. This includes features like quarterly sales, month-on-month expenditure, and a whole host of things that come with Apple’s balance sheet. As a data scientist, which kind of problem would you classify this as? Time series modeling, of course.
From predicting the sales of a product to estimating the electricity usage of households, time series forecasting is one of the core skills any data scientist is expected to know, if not master. There are a plethora of different techniques out there which you can use, and we will be covering one of the most effective ones, called Auto ARIMA, in this article.
We will first understand the concept of ARIMA which will lead us to our main topic – Auto ARIMA. To solidify our concepts, we will take up a dataset and implement it in both Python and R.
Table of contents
If you are familiar with time series and it’s techniques (like moving average, exponential smoothing, and ARIMA), you can skip directly to section 4. For beginners, start from the below section which is a brief introduction to time series and various forecasting techniques.
What is a time series ?
Before we learn about the techniques to work on time series data, we must first understand what a time series actually is and how is it different from any other kind of data. Here is the formal definition of time series – It is a series of data points measured at consistent time intervals. This simply means that particular values are recorded at a constant interval which may be hourly, daily, weekly, every 10 days, and so on. What makes time series different is that each data point in the series is dependent on the previous data points. Let us understand the difference more clearly by taking a couple of examples.
Example 1:
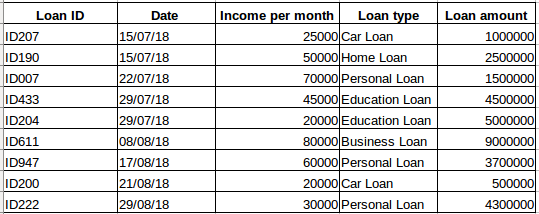
Suppose you have a dataset of people who have taken a loan from a particular company (as shown in the table below). Do you think each row will be related to the previous rows? Certainly not! The loan taken by a person will be based on his financial conditions and needs (there could be other factors such as the family size etc., but for simplicity we are considering only income and loan type) . Also, the data was not collected at any specific time interval. It depends on when the company received a request for the loan.
Example 2:
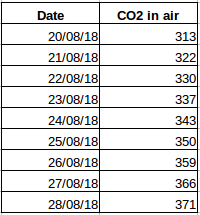
Let’s take another example. Suppose you have a dataset that contains the level of CO2 in the air per day (screenshot below). Will you be able to predict the approximate amount of CO2 for the next day by looking at the values from the past few days? Well, of course. If you observe, the data has been recorded on a daily basis, that is, the time interval is constant (24 hours).
You must have got an intuition about this by now – the first case is a simple regression problem and the second is a time series problem. Although the time series puzzle here can also be solved using linear regression, but that isn’t really the best approach as it neglects the relation of the values with all the relative past values. Let’s now look at some of the common techniques used for solving time series problems.
Methods for time series forecasting
There are a number of methods for time series forecasting and we will briefly cover them in this section. The detailed explanation and python codes for all the below mentioned techniques can be found in this article: 7 techniques for time series forecasting (with python codes).
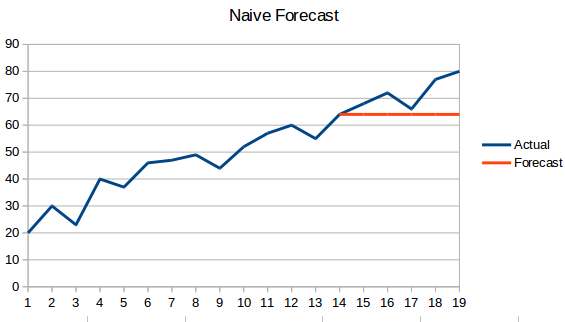
- Naive Approach: In this forecasting technique, the value of the new data point is predicted to be equal to the previous data point. The result would be a flat line, since all new values take the previous values.
- Simple Average: The next value is taken as the average of all the previous values. The predictions here are better than the ‘Naive Approach’ as it doesn’t result in a flat line but here, all the past values are taken into consideration which might not always be useful. For instance, when asked to predict today’s temperature, you would consider the last 7 days’ temperature rather than the temperature a month ago.
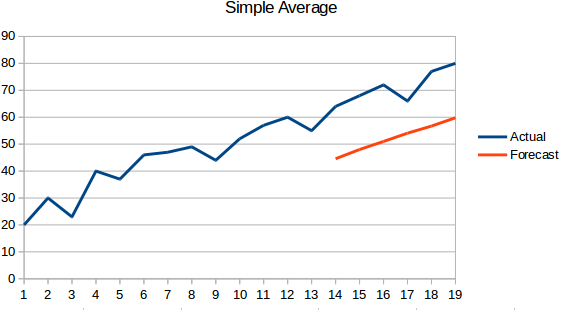
- Moving Average : This is an improvement over the previous technique. Instead of taking the average of all the previous points, the average of ‘n’ previous points is taken to be the predicted value.

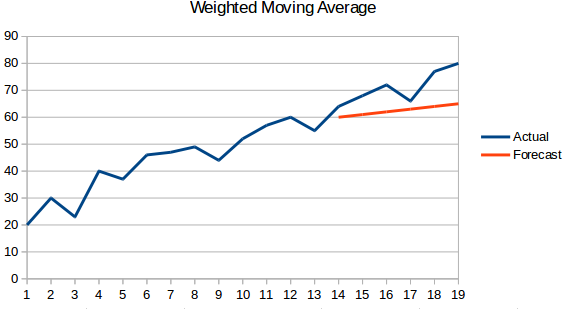
- Weighted moving average : A weighted moving average is a moving average where the past ‘n’ values are given different weights.
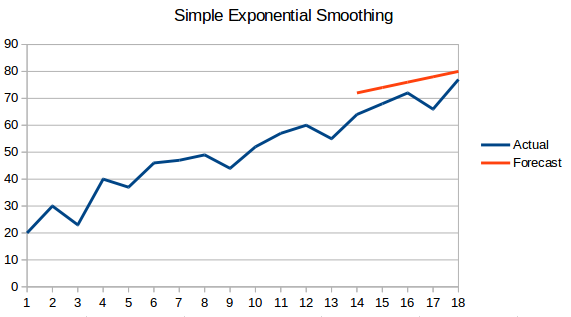
- Simple Exponential Smoothing: In this technique, larger weights are assigned to more recent observations than to observations from the distant past.
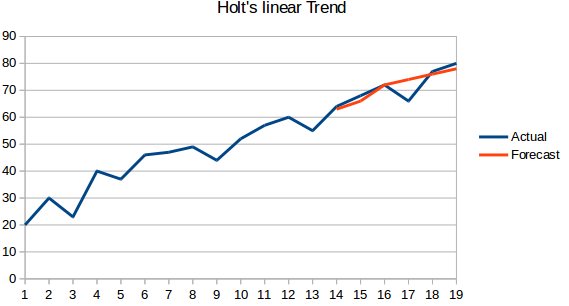
- Holt’s Linear Trend Model: This method takes into account the trend of the dataset. By trend, we mean the increasing or decreasing nature of the series. Suppose the number of bookings in a hotel increases every year, then we can say that the number of bookings show an increasing trend. The forecast function in this method is a function of level and trend.
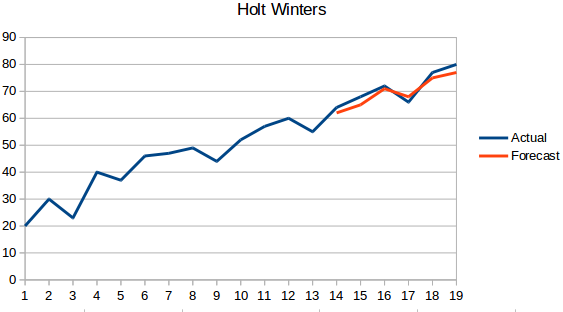
- Holt Winters Method: This algorithm takes into account both the trend and the seasonality of the series. For instance – the number of bookings in a hotel is high on weekends & low on weekdays, and increases every year; there exists a weekly seasonality and an increasing trend.
- ARIMA: ARIMA is a very popular technique for time series modeling. It describes the correlation between data points and takes into account the difference of the values. An improvement over ARIMA is SARIMA (or seasonal ARIMA). We will look at ARIMA in a bit more detail in the following section.
Introduction to ARIMA
In this section we will do a quick introduction to ARIMA which will be helpful in understanding Auto Arima. A detailed explanation of Arima, parameters (p,q,d), plots (ACF PACF) and implementation is included in this article : Complete tutorial to Time Series.
ARIMA is a very popular statistical method for time series forecasting. ARIMA stands for Auto-Regressive Integrated Moving Averages. ARIMA models work on the following assumptions –
- The data series is stationary, which means that the mean and variance should not vary with time. A series can be made stationary by using log transformation or differencing the series.
- The data provided as input must be a univariate series, since arima uses the past values to predict the future values.
ARIMA has three components – AR (autoregressive term), I (differencing term) and MA (moving average term). Let us understand each of these components –
- AR term refers to the past values used for forecasting the next value. The AR term is defined by the parameter ‘p’ in arima. The value of ‘p’ is determined using the PACF plot.
- MA term is used to defines number of past forecast errors used to predict the future values. The parameter ‘q’ in arima represents the MA term. ACF plot is used to identify the correct ‘q’ value.
- Order of differencing specifies the number of times the differencing operation is performed on series to make it stationary. Test like ADF and KPSS can be used to determine whether the series is stationary and help in identifying the d value.
Steps for ARIMA implementation
The general steps to implement an ARIMA model are –
- Load the data
The first step for model building is of course to load the dataset
- Preprocessing
Depending on the dataset, the steps of preprocessing will be defined. This will include creating timestamps, converting the dtype of date/time column, making the series univariate, etc.
- Make series stationary
In order to satisfy the assumption, it is necessary to make the series stationary. This would include checking the stationarity of the series and performing required transformations
- Determine d value
For making the series stationary, the number of times the difference operation was performed will be taken as the d value
- Create ACF and PACF plots
This is the most important step in ARIMA implementation. ACF PACF plots are used to determine the input parameters for our ARIMA model
- Determine the p and q values
Read the values of p and q from the plots in the previous step
- Fit ARIMA model
Using the processed data and parameter values we calculated from the previous steps, fit the ARIMA model
- Predict values on validation set
Predict the future values
- Calculate RMSE
To check the performance of the model, check the RMSE value using the predictions and actual values on the validation set
What is Auto ARIMA?
Auto ARIMA (Auto-Regressive Integrated Moving Average) is a statistical algorithm used for time series forecasting. It automatically determines the optimal parameters for an ARIMA model, such as the order of differencing, autoregressive (AR) terms, and moving average (MA) terms. Auto ARIMA searches through different combinations of these parameters to find the best fit for the given time series data. This automated process saves time and effort, making it easier for users to generate accurate forecasts without requiring extensive knowledge of time series analysis.
Why do we need Auto ARIMA?
Although ARIMA is a very powerful model for forecasting time series data, the data preparation and parameter tuning processes end up being really time consuming. Before implementing ARIMA, you need to make the series stationary, and determine the values of p and q using the plots we discussed above. Auto ARIMA makes this task really simple for us as it eliminates steps 3 to 6 we saw in the previous section. Below are the steps you should follow for implementing auto ARIMA:
- Load the data: This step will be the same. Load the data into your notebook
- Preprocessing data: The input should be univariate, hence drop the other columns
- Fit Auto ARIMA: Fit the model on the univariate series
- Predict values on validation set: Make predictions on the validation set
- Calculate RMSE: Check the performance of the model using the predicted values against the actual values
We completely bypassed the selection of p and q feature as you can see. What a relief! In the next section, we will implement auto ARIMA using a toy dataset.
Implementation in Python and R
We will be using the International-Air-Passenger dataset. This dataset contains monthly total of number of passengers (in thousands). It has two columns – month and count of passengers. You can download the dataset from this link.
Python Code:
#building the model from pyramid.arima import auto_arima model = auto_arima(train, trace=True, error_action='ignore', suppress_warnings=True) model.fit(train) forecast = model.predict(n_periods=len(valid)) forecast = pd.DataFrame(forecast,index = valid.index,columns=['Prediction']) #plot the predictions for validation set plt.plot(train, label='Train') plt.plot(valid, label='Valid') plt.plot(forecast, label='Prediction') plt.show()
#calculate rmse from math import sqrt from sklearn.metrics import mean_squared_error rms = sqrt(mean_squared_error(valid,forecast)) print(rms)
output - 76.51355764316357
Below is the R Code for the same problem:
# loading packages
library(forecast)
library(Metrics)
# reading data
data = read.csv("international-airline-passengers.csv")
# splitting data into train and valid sets
train = data[1:100,]
valid = data[101:nrow(data),]
# removing "Month" column
train$Month = NULL
# training model
model = auto.arima(train)
# model summary
summary(model)
# forecasting
forecast = predict(model,44)
# evaluation
rmse(valid$International.airline.passengers, forecast$pred)
How does Auto Arima select the best parameters
In the above code, we simply used the .fit() command to fit the model without having to select the combination of p, q, d. But how did the model figure out the best combination of these parameters? Auto ARIMA takes into account the AIC and BIC values generated (as you can see in the code) to determine the best combination of parameters. AIC (Akaike Information Criterion) and BIC (Bayesian Information Criterion) values are estimators to compare models. The lower these values, the better is the model.
Check out these links if you are interested in the maths behind AIC and BIC.
Frequently Asked Questions
A. Auto ARIMA (Auto-Regressive Integrated Moving Average) is an algorithm used in time series analysis to automatically select the optimal parameters for an ARIMA model. It determines the order of differencing, the autoregressive component, and the moving average component. By automatically finding the best fit, it simplifies the process of modeling and forecasting time series data.
A. ARIMA (Auto-Regressive Integrated Moving Average) is a time series forecasting model that requires manual selection of its parameters, including the order of differencing, the autoregressive component, and the moving average component. This manual selection process can be time-consuming and requires expertise.
Auto ARIMA, on the other hand, is an automated version of the ARIMA model. It utilizes algorithms to automatically determine the optimal values for the ARIMA parameters. Auto ARIMA saves time and effort by eliminating the need for manual parameter selection, making it a convenient tool for forecasting time series data, especially for users without deep knowledge of time series analysis.
End Notes and Further Reads
I have found auto ARIMA to be the simplest technique for performing time series forecasting. Knowing a shortcut is good but being familiar with the math behind it is also important. In this article I have skimmed through the details of how ARIMA works but do make sure that you go through the links provided in the article. For your easy reference, here are the links again:
- A Comprehensive Guide for beginners to Time Series Forecast in Python
- Complete Tutorial to Time series in R
- 7 techniques for time series forecasting (with python codes)
I would suggest practicing what we have learned here on this practice problem: Time Series Practice Problem. You can also take our training course created on the same practice problem, Time series forecasting, to provide you a head start.
Good luck, and feel free to provide your feedback and ask questions in the comments section below.
An avid reader and blogger who loves exploring the endless world of data science and artificial intelligence. Fascinated by the limitless applications of ML and AI; eager to learn and discover the depths of data science.









Hi Aishwarya, Thanks for another nice article. There are few things which I would like to clarify. could you please through some light on below points? While introducing ARIMA you mentioned that q is calculated by PACF and p is calculated by ACF, I believe its vice versa. Please confirm what are the selected p,d,q values after the auto arima model decided the best params for prediction? Forecasted line seems to be just an average of the validation set which completely miss the seasonality and the trend. Is it a good forecast? which smoothing technique(MA, WA, Holts or Holts winter) is used while applying ARiMA on the training dataset? How to interpret the score on the basis of AIC and BIC? Please elaborate Do we need to do any preprocessing before feeding training set to the auto arima tool? How can we improve the rmse score? Regards Nitin
Hi Nitin, Thank you for the feedback. You are right about the calculation of p and q. I will update the same in the article. Secondly, when you use
model.fit(), it will print the selected p,q,d. Regarding the forecast, if you change the parameters of auto arima and put Seasonality = True, Auto arima will take into account the seasonality as well. You will certainly give a better result. Same is the answer to your last question about rmse score, set a range of p,q and P,Q (after setting seasonality=True) and you will see an improvement in the rmse score. This is actually a great point and if time permits, I will include parameter tuning of auto arima in this article. Lastly, AIC and BIC values are used to compare models; the lower the AIC/BIC, better is the model.Thanks for this article...
Glad you liked it!
sounds great, but bit unclear about cons n pros, is this always good to prefer than simply ARIMA?
Hi Ayush, The major difference between Arima and Auto Arima is that there is no need to tune the parameters p,q,d. If you have used arima, you would be aware that the values of p and q are to be calculated using ACF PACF plots, which is not required in auto arima. But the drawback is, auto arima fits the model on selected parameters and you cannot manually change these. In case you want to see the results on a different set of parameters, you will have to use arima.
Hi, Good article and nicely explained. However, I think there is an issue with your last line of code in the R version with vector length mismatch. Thanks!
Hi, The code works fine for me. Can you share what is the error the error?
Hi Aishwarya, the rmse() last line code produces error as follows: Error in `-.default`(actual, predicted) : time-series/vector length mismatch Then I fix the forecast = predict(model, 46) # instead of 44 because valid has 46 obs. Then rmse(valid$passenger, forecast$pred) >> which works no error message but the error result is NA. Please advise how to fix it.
Hi, I guess the problem is with the dataset and not the code. The dataset downloaded has an extra line at row 147 which contains text "Internationanl air passenger". Please delete that (simply by opening the csv file). I have also mailed you the corrected csv file.
Hi, I'd like to translate this excellent tutorial to Chinese. Can you give me the permission to translate it? The translated text will be published at ai.jqr.com and related Chinese social net accounts. Thanks.
Nice article Aishwarya
Thank You Mathangi!
Nice article. What is the best practice for hourly time series ? Thank you !
Hi AISHWARYA, Nice article. Could you please share your thoughts/experience about comparison between Auto-ARIMA and Prophet ? Thank you !
Hi Bhushan, Prophet is another great library for time series forecasting. One interesting addition in prophet is that it takes into account the holidays as well, which I believe would greatly affect the forecast. Personally, I found understanding the working of ARIMA easier. To be honest, I haven't really worked with it or compared these two yet.
Nice article Aishwarya. Keep posting such useful articles. I am new to DataScience. I ran your R model. In Training set I got the following RMSE Training set error measures: ME RMSE MAE MPE MAPE MASE ACF1 Training set 4.471684 21.26657 17.48184 1.56563 7.996206 0.9294857 -0.06828143 And when I executed the last line ie RMSE command, I got following > rmse(valid$International.airline.passengers, forecast$pred) [1] 122.024 How do I interpret that? Can I plot output for both training and test set as you did in Python code? Thanks a lot again
Interesante articulo sobre el pronostico de series de tiempo con modelos ARIMA , nos podria compartir estos resultados usando Redes Neuronales para poder pronosticar tanto univariada y bivariada . Me seria de gran ayuda.
Gracias Pedro He utilizado redes neuronales para univariado (LSTM) en uno de los artículos. Compartirá el siguiente enlace: https://www.analyticsvidhya.com/blog/2018/10/predicting-stock-price-machine-learningnd-deep-learning-techniques-python/
I have applied ARIMA in small dataset having only 18 months data (18 data points).It does not work on small data.Request you to mention some time series techniques that work on small data
HI, Just 18 points is not a sufficient amount of data to train any model as it will not be able to capture any pattern from the data. If it is possible, gather more data points, or if you can get the daily data instead of monthly data for this
Great article. I have a question about interpretation. The RMSE at the end comes out to 122.024. Isn't that pretty high? Can you provide a short explanation of how you would interpret this outcome in a professional setting? Thanks in advance!
hi.. could you please share the R code of hybrid model of ARIMA-ANN model?
Have you ever done any analysis on NIFTY or STOCK Future?
Hello, I am getting the following error TypeError: ARIMA.fit() got an unexpected keyword argument 'disp' I have used the statsmodels.tsa.arima.model instead of statsmodels.tsa.arima_model as it has been removed. Can anyone please help me with this? Quote ReplyReport Edit Delete
Hello Aishwarya, May I ask, if you have ever worked on implementation of Multiple Time Series Models in R or Python? If so could you share the article or code which you used as reference for doing the same.
Hi, Thanks for your comprehensive guide about arima model. As far as I am not completely familiar with this method, I did not understand what Valid is here : "forecast = model.predict(n_periods=len(valid))" . Would you please explain more about it? Is it a list? and what does it contain? Thank you.