Overview
- Check out Google AI’s best paper from ICML 2019
- There is a heavy focus on unsupervised learning in Google AI’s paper
- We have broken down the best paper from ICML 2019 into easy-to-understand sections in this article
Introduction
There are only a handful of machine learning conferences in the world that attract the top brains in this field. One such conference, which I am an avid follower of, is the International Conference on Machine Learning (ICML).
Folks from top machine learning research companies, like Google AI, Facebook, Uber, etc. come together and present their latest research. It’s a conference any data scientist would not want to miss.
ICML 2019, held last week in Southern California, USA, saw records tumble in astounding fashion. The number of papers received and the number of papers accepted at the conference – both broke all previous records. Check out the numbers:
Source: Medium
A panel of hand-picked judges is charged with picking out the best papers from this list. Receiving this best paper award is quite a prestigious achievement – everyone in the research community strives for it!

And decrypting these best papers from ICML 2019 has been an eye-opener for me. I love going through these papers and breaking them down so our community can also partake in the hottest happenings in machine learning.
In this article, we’ll look at Google AI’s best paper from the ICML 2019 conference. There is a heavy focus on unsupervised learning so there’s a lot to unpack. Let’s dive right in.
You can also check out my articles on the best papers from ICLR 2019 here.
The Best Paper Award at ICML 2019 Goes to:
- Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations (Google AI)
- Rates of Convergence for Sparse Variational Gaussian Process Regression
Our main focus is on the first paper from the Google AI team. So let’s check out what Google has put forward for our community.
Note: There are certain unsupervised deep learning concepts you should be aware of before diving into this article. I suggest going through the below guides first in case you need a quick refresher:
- Introduction to Unsupervised Deep Learning (with Python codes)
- Exploring Unsupervised Deep Learning Algorithms
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
Let’s first understand what disentangled representations are. Here is Google AI’s succinct and simple definition of the concept:
The ability to understand high-dimensional data, and to distill that knowledge into useful representations in an unsupervised manner, remains a key challenge in deep learning. One approach to solving these challenges is through disentangled representations, models that capture the independent features of a given scene in such a way that if one feature changes, the others remain unaffected. – Google AI
As the paper says, in representation learning, it is often assumed that real-world observations x, like images or videos, are generated by a two-step generative process:
- The first step involves the sampling of a multivariate latent random variable z from a distribution P(z). Intuitively, this random variable corresponds to semantically meaningful factors of variation of the observations
- In the second step, the observation x is sampled from condition distribution P(x|z)
In other words, a lower dimensional entity, which is mapped to the higher-dimensional space of observation, could be used to explain a high-dimension observation.
Objective of this Paper
The objective of this research is to point out the areas of improvement for future work to make unsupervised disentangled methods better.
The authors have released a reproducible large-scale experimental study on seven different datasets, including 12,000 models that were trained covering the most prominent methods and evaluation metrics.
There is currently no single formalized notion of disentanglement which is widely accepted. So, the key intuition is that a disentangled representation should separate the distinct, informative factors of variations in the data.
Current State-of-the-Art Approach
The current state-of-the-art approaches for unsupervised disentanglement learning are largely based on Variational Autoencoders (VAEs). A specific distribution P(z) is assumed on a latent space and then a deep neural network is used to parameterize the conditional probability P(x|z).
Similarly, the distribution P(z|x) is approximated using a variational distribution Q(z|x). The model is then trained by minimizing a suitable approximation to the negative log-likelihood.
Contribution of this Paper to the Field
Google AI researchers have challenged the commonly held assumptions in this field. I have summarized their contributions below:
- The current approaches and their inductive biases were investigated in a reproducible large scale experimental study with a sound experimental protocol for unsupervised disentanglement learning. The researchers:
- Implemented 6 recent unsupervised disentanglement learning methods
- Created 6 disentanglement measures from scratch
- Trained more than 12,000 models on seven different datasets
- They have released a new library disentanglement_lib to train and evaluate disentangled representations. As the result production requires substantial computational effort, the team also released more than 10,000 trained models which can be used as baselines for future research
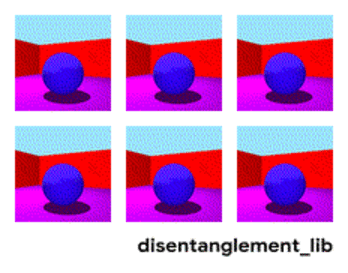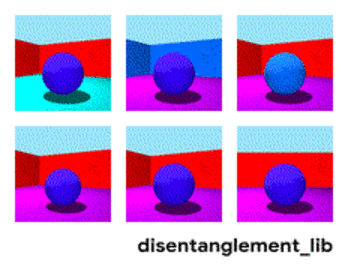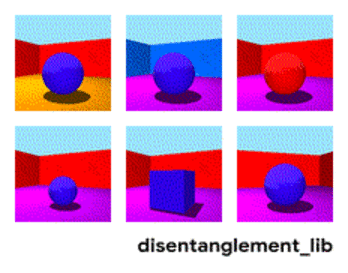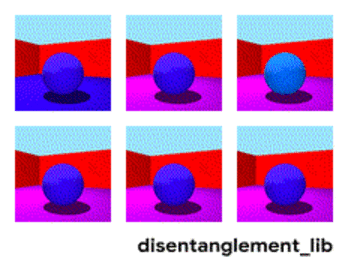
Visualization of the ground-truth factors of the Shapes3D data set: Floor color (upper left), wall color (upper middle), object color (upper right), object size (bottom left), object shape (bottom middle), and camera angle (bottom right)
- The researchers analyzed their experimental result and challenged common beliefs in disentangled learning:
- All the methods considered by the Google AI team proved effective at ensuring that the individual dimensions of the aggregated posterior (which is sampled) are not correlated. However, they observed that the dimensions of the representation (which is taken to be the mean) are in fact correlated
- They did not find evidence that the considered models can be used to reliably learn disentangled representations in an unsupervised manner as random seeds
- Hyperparameters seemed to matter more than the model choice. Furthermore, well-trained models seemingly couldn’t be identified without access to ground-truth labels even if we are allowed to transfer good hyperparameter values across datasets
- For the considered models and datasets, the team could not validate the assumption that disentanglement is useful for downstream tasks
Experimental Design Proposed by Google AI
I have taken this section from within the paper itself. If you have any queries, you can reach out to me in the comments section below the article and I’ll be happy to clarify them.
Considered methods:
All the considered methods augment the VAE (Variational Autoencoders) loss with some regularizer.
- The β-VAE introduces a hyperparameter in front of the KL regularizer of vanilla VAEs to constrain the capacity of the VAE bottleneck
- The AnnealedVAE progressively increases the bottleneck capacity so that the encoder can focus on learning one factor of variation at a time (the one that most contributes to a small reconstruction error)
- The FactorVAE and the β-TCVAE penalize the total correlation with adversarial training or with a tractable but biased Monte-Carlo estimator respectively
- The DIP-VAE-I and the DIP-VAE-II both penalize the mismatch between the aggregated posterior and a factorized prior
Considered metrics:
- The BetaVAE metric measures disentanglement as the accuracy of a linear classifier that predicts the index of a fixed factor of variation
- The Mutual Information Gap (MIG) measures, for each factor of variation, the normalized gap in mutual information between the highest and second highest coordinate in r(x)
- The Disentanglement metric of Ridgeway & Mozer computes the entropy of the distribution obtained by normalizing the importance of each dimension of the learned representation for predicting the value of a factor of variation
Datasets:
- The four datasets used in this research are:
- dSprites
- Cars3d
- SmallNORB
- Shapes3D
- Three datasets Color-dSprites, Noisy-dSprites and Scream-dSprites are also introduced where the observations are stochastic given the factor of variations z:
- In Color-dSprites, the shapes are colored with a random color
- In Noisy-dSprites, white-colored shapes on a noisy background are considered
- Finally, in Scream-dSprites, the background is replaced with a random patch in a random color shade extracted from the famous The Scream painting:

The Scream Painting
Key Experimental Results
This is the part that will get every data scientist out of their seats! The researchers have showcased their results by answering a set of questions.
- Can current methods enforce an uncorrelated aggregated posterior and representation?
- The results concluded that, with minor exceptions, the considered methods are effective at enforcing an aggregated posterior whose individual dimensions are not correlated. But this does not seem to imply that the dimensions of the mean representation are uncorrelated

Total correlation based on a fitted Gaussian of the sampled (left) and the mean representation (right) plotted against regularization strength for Color-dSprites and approaches (except AnnealedVAE). The total correlation of the sampled representation decreases while the total correlation of the mean representation increases as the regularization strength is increased
- How much do the disentanglement metrics agree?
- All disentanglement metrics except Modularity appear to be correlated. However, the level of correlation changes between different datasets
- How important are different models and hyperparameters for disentanglement?
- The disentanglement scores of unsupervised models are heavily influenced by randomness (in the form of the random seed) and the choice of the hyperparameter (in the form of the regularization strength). The objective function appears to have less impact

(left) FactorVAE score for each method on Cars3D. Models are abbreviated (0=β- VAE, 1=FactorVAE, 2=β-TCVAE, 3=DIP-VAE-I, 4=DIP-VAE-II, 5=AnnealedVAE). The scores are heavily overlapping. (right) Distribution of FactorVAE scores for FactorVAE model for different regularization strengths on Cars3D.
- Are there reliable recipes for model selection?
- Unsupervised model selection remains an unsolved problem. Transfer of good hyperparameters between metrics and datasets does not seem to work as there appears to be no unsupervised way to distinguish between good and bad random seeds on the target task
- Are these disentangled representations useful for downstream tasks in terms of the sample complexity of learning?
- While the empirical results in this section are negative, they should also be interpreted with care. After all, we have seen in previous sections that the models considered in this study fail to reliably produce disentangled representations. Hence, the results in this section might change if one were to consider a different set of models (for example, semi-supervised or fully supervised ones)

Statistical efficiency of the FactorVAE Score for learning a GBT downstream task on dSprites.
End Notes
The Google AI team continues to nail its machine learning research. They continue to be on top of the latest advacements, this year’s International Conference of Machine Learning.
The second paper selected is based on how the results could be made better in Gaussian Process Regression, you can check out the paper through the link provided in this article.
Let me know about your views on the Google AI research paper in the comments section below. Keep learning!
A Data Science Enthusiast who loves reading & writing about Data Science and its applications. He has done many projects in this field and his recent work include concepts like Web Scraping, NLP etc. He is a Data Science Content Strategist Intern at Analytics Vidhya. And currently pursuing BTech in Computer Science from DIT University, Dehradun.




inspiring article.
This is indeed an attention getter! Haven't read the paper yet but, going on the assumption that Google AI haven't made a gross methodological error, which is reasonable, the questions come to mind fast and furious! At the top of the list is what this means for already accepted methods and results. What is the unknown correlational factor for the mean? Had Google AI found it, this paper wouldn't exist. We're leaning heavily on Google AI's reputation for our philosophical comfort right now. It's trivially true to say that the models/features are correlated because they are in a set of observations, and are a product of certain mathematical operations. Maybe not so trivial? I feel like some kind of New Age Woo-meister for even thinking of the Observer Effect here.