Understanding Distance Metrics Used in Machine Learning
Clustering is an important part of data cleaning, used in the field of artificial intelligence, deep learning, and data science. Today we are going to discuss distance metrics, which is the backbone of clustering. Distance metrics basically deal with finding the proximity or distance between data points and determining if they can be clustered together. In this article, we will walk through 4 types of distance metrics in machine learning and understand how they work in Python.
Table of contents
Learning objectives
- In this tutorial, you will learn about the use cases of various distance metrics.
- You will also learn about the different types of learning metrics.
- Lastly, you will learn about the important role distance metrics play in data mining.
What Are Distance Metrics?
Distance metrics are a key part of several machine learning algorithms. These distance metrics are used in both supervised and unsupervised learning, generally to calculate the similarity between data points. An effective distance metric improves the performance of our machine learning model, whether that’s for classification tasks or clustering.
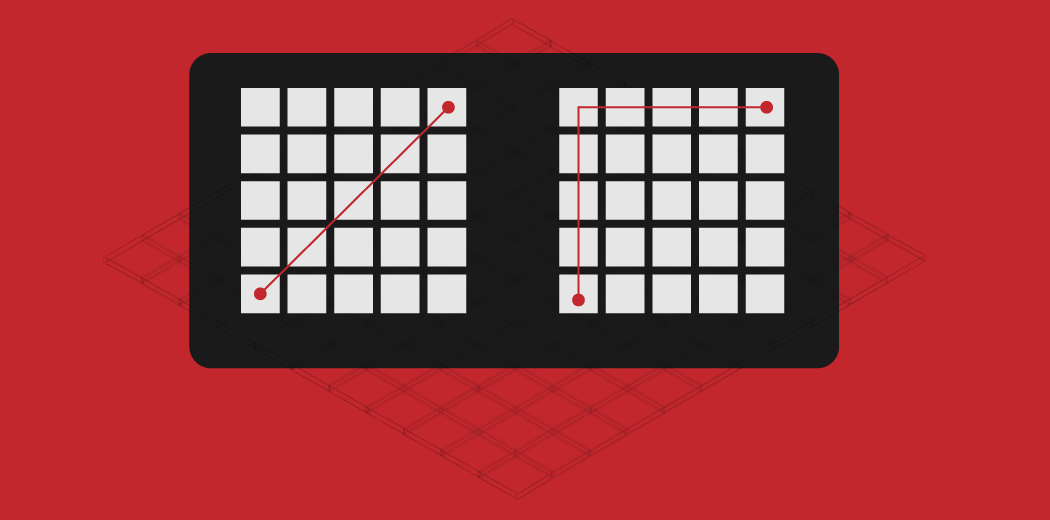
Let’s say you need to create clusters using a clustering algorithm such as K-Means Clustering or k-nearest neighbor algorithm (knn), which uses nearest neighbors to solve a classification or regression problem. How will you define the similarity between different observations? How can we say that two points are similar to each other? This will happen if their features are similar, right? When we plot these points, they will be closer to each other by distance.

Hence, we can calculate the distance between points and then define the similarity between them. Here’s the million-dollar question – how do we calculate this distance, and what are the different distance metrics in machine learning? Also, are these metrics different for different learning problems? Do we use any special theorem for this? These are all questions we are going to answer in this article.
Types of Distance Metrics in Machine Learning
- Euclidean Distance
- Manhattan Distance
- Minkowski Distance
- Hamming Distance
Let’s start with the most commonly used distance metric – Euclidean Distance.
Euclidean Distance
Euclidean Distance represents the shortest distance between two vectors.It is the square root of the sum of squares of differences between corresponding elements.
The Euclidean distance metric corresponds to the L2-norm of a difference between vectors and vector spaces. The cosine similarity is proportional to the dot product of two vectors and inversely proportional to the product of their magnitudes.
Most machine learning algorithms, including K-Means use this distance metric to measure the similarity between observations. Let’s say we have two points, as shown below:

So, the Euclidean Distance between these two points, A and B, will be:

Formula for Euclidean Distance

We use this formula when we are dealing with 2 dimensions. We can generalize this for an n-dimensional space as:

Where,
- n = number of dimensions
- pi, qi = data points
Let’s code Euclidean Distance in Python. This will give you a better understanding of how this distance metric works.
We will first import the required libraries. I will be using the SciPy library that contains pre-written codes for most of the distance functions used in Python:
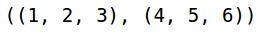
These are the two sample points that we will be using to calculate the different distance functions. Let’s now calculate the Euclidean Distance between these two points:
Python Code

This is how we can calculate the Euclidean Distance between two points in Python. Let’s now understand the second distance metric, Manhattan Distance.
Manhattan Distance
Manhattan Distance is the sum of absolute differences between points across all the dimensions.
We can represent Manhattan Distance as:

Formula for Manhattan Distance
Since the above representation is 2 dimensional, to calculate Manhattan Distance, we will take the sum of absolute distances in both the x and y directions. So, the Manhattan distance in a 2-dimensional space is given as:

And the generalized formula for an n-dimensional space is given as:

Where,
- n = number of dimensions
- pi, qi = data points
Now, we will calculate the Manhattan Distance between the two points:
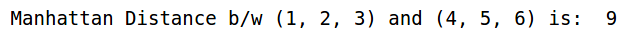
Note that Manhattan Distance is also known as city block distance. SciPy has a function called cityblock that returns the Manhattan Distance between two points.
Let’s now look at the next distance metric – Minkowski Distance.
Minkowski Distance
Minkowski Distance is the generalized form of Euclidean and Manhattan Distance.
Formula for Minkowski Distance

Here, p represents the order of the norm. Let’s calculate the Minkowski Distance formula of order 3:

The p parameter of the Minkowski Distance metric of SciPy represents the order of the norm. When the order(p) is 1, it will represent Manhattan Distance and when the order in the above formula is 2, it will represent Euclidean Distance.
Python Code

Here, you can see that when the order is 1, both Minkowski and Manhattan Distance are the same. Let’s verify the Euclidean Distance as well:

When the order is 2, we can see that Minkowski and Euclidean distances are the same.
So far, we have covered the distance metrics that are used when we are dealing with continuous or numerical variables. But what if we have categorical variables? How can we decide the similarity between categorical variables? This is where we can make use of another distance metric called Hamming Distance.
Hamming Distance
Hamming Distance measures the similarity between two strings of the same length. The Hamming Distance between two strings of the same length is the number of positions at which the corresponding characters are different.
Let’s understand the concept using an example. Let’s say we have two strings:
“euclidean” and “manhattan”
Since the length of these strings is equal, we can calculate the Hamming Distance. We will go character by character and match the strings. The first character of both the strings (e and m, respectively) is different. Similarly, the second character of both the strings (u and a) is different. and so on.
Look carefully – seven characters are different, whereas two characters (the last two characters) are similar:

Hence, the Hamming Distance here will be 7. Note that the larger the Hamming Distance between two strings, the more dissimilar those strings will be (and vice versa).
Python Code
Let’s see how we can compute the Hamming Distance of two strings in Python. First, we’ll define two strings that we will be using:
These are the two strings “euclidean” and “manhattan”, which we have seen in the example as well. Let’s now calculate the Hamming distance between these two strings:

As we saw in the example above, the Hamming Distance between “euclidean” and “manhattan” is 7. We also saw that Hamming Distance only works when we have strings of the same length.
Let’s see what happens when we have strings of different lengths:
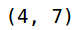
You can see that the lengths of both the strings are different. Let’s see what will happen when we try to calculate the Hamming Distance between these two strings:
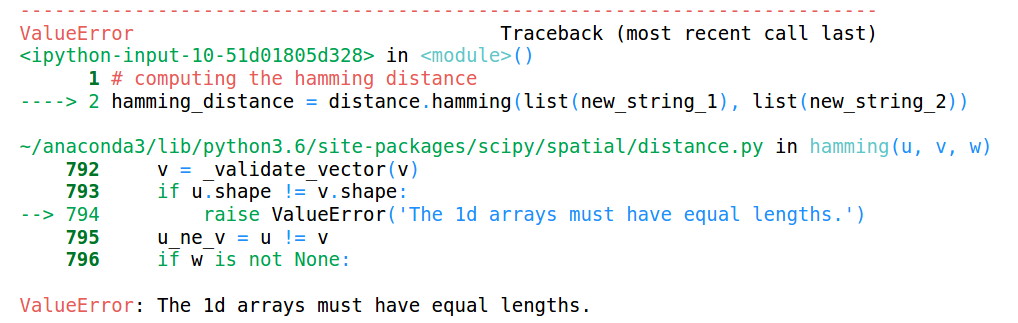
This throws an error saying that the lengths of the arrays must be the same. Hence, Hamming distance only works when we have strings or arrays of the same length.
These are some of the most commonly used similarity measures or distance matrices in Machine Learning.
Conclusion
Distance metrics are a key part of several machine learning algorithms. They are used in both supervised and unsupervised learning, generally to calculate the similarity between data points. Therefore, understanding distance measures is more important than you might realize. Take k-NN, for example – a technique often used for supervised learning. By default, it often uses euclidean distance, a great distance measure, for clustering.
By grasping the concept of distance metrics and their mathematical properties, data scientists can make informed decisions in selecting the appropriate metric for their specific problem. Our BlackBelt program provides comprehensive training in machine learning concepts, including distance metrics, empowering learners to become proficient in this crucial aspect of data science. Enroll in our BlackBelt program today to enhance your skills and take your data science expertise to the next level.
Key Takeaways
- Distance metrics are used in supervised and unsupervised learning to calculate similarity in data points.
- They improve the performance, whether that’s for classification tasks or clustering.
- The four types of distance metrics are Euclidean Distance, Manhattan Distance, Minkowski Distance, and Hamming Distance.
Frequently Asked Questions
A. The L1 is calculated as the sum of the absolute values of the vector. The L2 norm is calculated as the square root of the sum of squared vector values.
A. Euclidean distance, cosine similarity measure, Minkowsky, correlation, and Chi-square, are used in the k-NN classifier.
A. Distance metric is what most algorithms, such as K-Means and KNN, use for clustering.
My research interests lies in the field of Machine Learning and Deep Learning. Possess an enthusiasm for learning new skills and technologies.









hello, sir, I need help regarding my 8th-semester project can you please give me your contact mail.
Hi, In Minkowski Distance, how to determine the value of 'p'? Thanks in advance Sagar
Hello Pulkit, This comment refers to your 'Step-by-Step Deep Learning Tutorial to Build your own Video Classification Model' blog post. I could not seem to add a comment under the post, so i will add it here. First, I will love to thank you for the step-by-step guide to Video classification. However, I don't think you performed video classification. You preprocessed the videos into frames, which was great but you modelled your problem as an image classification and not video classification problem. I think a video classification problem requires processing the frames in sequence i.e., sequence learning. The main difference between video classification and image classification is to capture the temporal or dynamic characteristics between the different frames of a video. However, i dont see this in the way you modelled your data or your model. So i think its better to title the post "step-by-step deep learning tutorial to build an image classification model from videos". Hope this helps. Kind regards,
thank you for the information