This article was published as a part of the Data Science Blogathon
Introduction
Hello folks, so this article has the detailed concept of distance measures, When you use some distance measures machine learning algorithms like KNN, SVM, logistic regression, etc… they are mostly or generally dependent on the distance between data points and to measure these distances between points here’s this concept comes into existence. Distance measures play an important role in several machine learning algorithms. So before moving ahead we have to clear some fundamentals or concepts related to this particular topic.
Image Source: https://www.klipfolio.com/blog/algorithm-in-six-steps
So, let’s Introduce to one of the distance measure algorithms KNN,
K- Nearest Neighbours
This is a supervised machine learning algorithm, which is generally used to solve classification problems but sometimes it was also used in regression problems too. The main aim of KNN is to find the nearest neighbours of our query point. This algorithm believes that similar things are in close proximity, in other words, we can say that suppose X is +ve in a group of points so there is a high chance that the point nearer to X is also +ve. Let us talk about the concept of nearest neighbour for better understanding.
Nearest Neighbour:
let’s take the simplest case of binary classification, suppose we have a group of +ve and -ve points in the dataset D such that the Xis belongs to the R-dim. data points and Yi are labels (+ve and -ve).
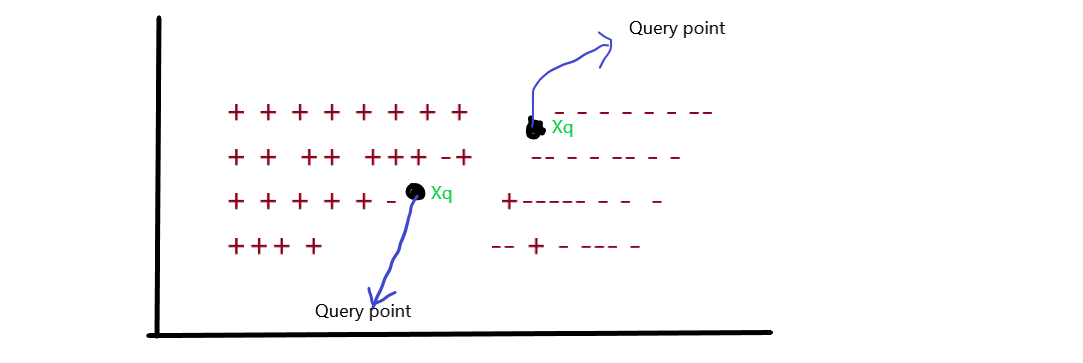
From the above image, you can conclude that there are several data points in 2 dim. Having the specific label, they are classified according to the +ve and -ve labels. If you noticed in the image there is one Query point referred to as Xq which has an unknown label. The surrounding points of Xq we considered as neighbours of Xq and the points which are close to the Xq are nearest neighbours.
So how can we conclude that this point is nearest or not? It’s by finding the distance b/w the points. So, here’s the distance measures come existence.
Distance measures
We generally say that we will use distance to find the nearest neighbours of any query point Xq, but we still don’t know how mathematically distance is measured between Xq and other nearest points? for further finding distance, we can’t conclude that this is nearest or not.
In a theoretical manner, we can say that a distance measure is an objective score that summarizes the difference between two objects in a specific domain. There are several types of distance measures techniques but we only use some of them and they are listed below:
1. Euclidean distance
2. Manhattan distance
3. Minkowski distance
4. Hamming distance
Let’s discuss it one by one.
Euclidean Distance
We mostly use this distance measurement technique to find the distance between consecutive points. It is generally used to find the distance between two real-valued vectors. Euclidean distance is used when we have to calculate the distance of real values like integer, float, etc… One issue with this distance measurement technique is that we have to normalize or standard the data into a balance scale otherwise the outcome will not preferable.
Let’s take an example of a 2-Dimensional vector and take a geometrical intuition of distance measures on 2-Dim data for a better understanding.
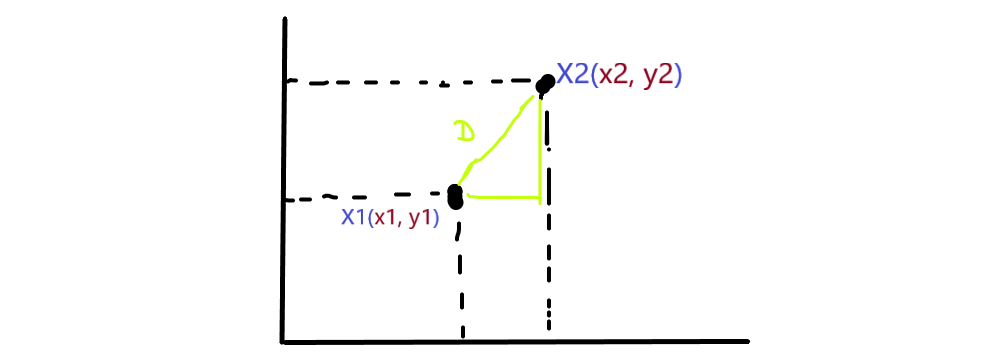
From the above image, you can see that there are 2-Dim data X1 and X2 placed at certain coordinates in 2 dimensions, suppose X1 is at (x1,y1) coordinates and X2 is at (x2,y2) coordinates. We have 2-dim data so we considered F1 and F2 two features and D is considered as the shortest line from X1 and X2, If we find the distance between these data points that can be found by the Pythagoras theorem and can be written as:

You already know that we are finding the distance or we can say the length of any 2 points, so we in vectorize from we can write that as d = || X1 – X2 ||
Suppose we take D-dimensional vector it means X1 belongs to Rd (X1∈Rd) and also X2 belongs to Rd (X2∈Rd) so the distance between X1 and X2 is written as:
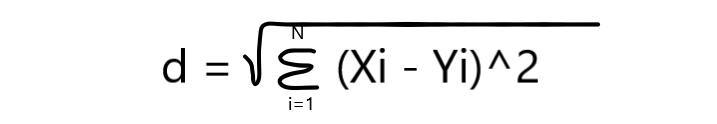
Note: Euclidean distance between two vectors or points is the L2 norm of two vector
Example:
Let’s take a simple and basic example to illustrate the above mathematical equation.
Suppose the vector X1 and X2 coordinates are in 2-Dim,
X1(x1, y1) = X1(3, 4)
X2(x2, y2) = X2(4, 7), as you can see in the image.
So these are a 2-Dim vector so our eucledian distance mathematical equation for finding the distance between X1 and X2 is:
distance = sqrt( (x2-x1)2 + (y2-y1)2 )
When we put our coordinates in the equations,
distance = sqrt( (4-3)2 + (7-4)2 )
distance = sqrt( 1+32 )
distance = sqrt( 10 )
distance = 3.1 (approx)
So, simply we can say that point X2 is 2 distances far from point X1.
Manhatten Distance
This is the simplest way or technique to calculate the distance between two points, often called Taxicab distance or City Block distance, you can easily relate this with your daily life, If you start from somewhere and reached some destination so the Manhatten distance says that the distance between your starting point and the destination point. More mathematical we can say that It calculates the absolute value between two points. We calculate the distance exactly as the original path is we didn’t take any diagonal or shortest path.
Let’s take the geometric intuition for better understanding;
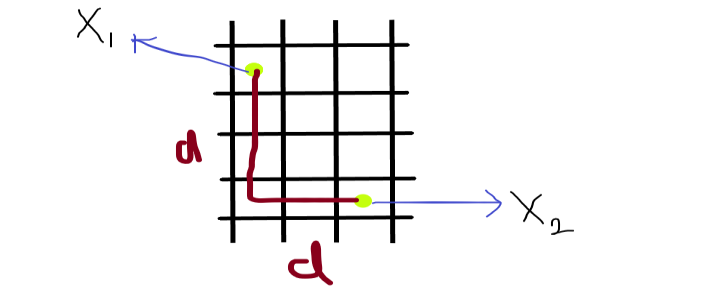
you can see in the image that the points X1 and X2 are 2-Dim vectors and having the coordinates same as before we discussed for euclidean distance, but here we can’t calculate the distance as we calculate earlier apart from this we take the absolute value of the path from X1 to X2. In the image see that we take the path that actually covers from one point to another.
Manhatten Distance = sum for i to N sum || X1i – X2i ||
In mathematically we can write as :
Note: Manhatten distance between two vectors or points is the L1 norm of two vector
Example:
So, you all know that the Manhatten distance is a little bit the same as the euclidian distance, but here we find the absolute value, let’s take an example of it.
Suppose, one cab starting from point X1 and has to reach its destination point X2 so we didn’t calculate its shortest path apart from this we have to calculate its absolute or full path they travel.
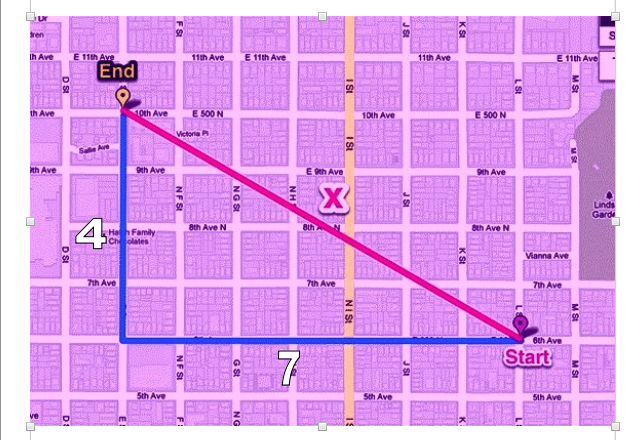
As you see in the image the blue line represents the absolute path that the cab travel.
as Manhatten formula says: distance = absolute sum ||xi-yi||
distance = (7 + 4)
distance = 11
SO, the absolute path the cab cover is 11.
Minkowski distance
Above we have discussed the L1 norm and L2 norm so this is the Lp norm of two vectors, More often we say that the Minkowski distance is the generalization or generalized form of the euclidean and Manhatten distance. Why do we call it to generalize? because we take both the distance technique and the new technique for finding the distance between vectors. It adds a parameter, called the “P“, that allows different distance measures to be calculated.
Let’s take it more mathematically, the equation of Minkowski distance is:
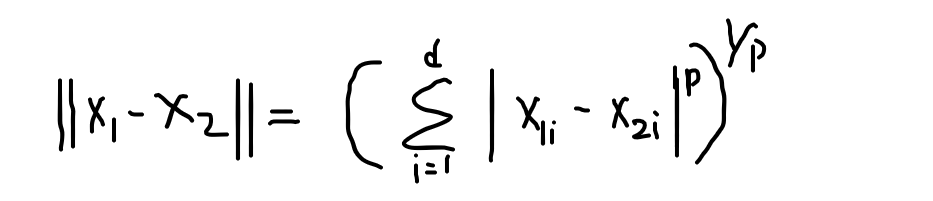
From the above equation you notice that the formula is the same as Euclidean distance but the change is that here we prefer the value of P, So if we take the P-value equals to 2 then it is euclidian distance and takes P-value equals to 1 then it is considered as Manhatten distance.
P = 1 => D = ( ∑i=1 to n( X1i−X2i )1)1/1
P = 2 => D = ( ∑i=1 to n( X1i−X2i )2 )1/2
Note: Minkowski distance between two vectors or points is the Lp norm of two vector.
Example:
So, here we will take the same example as we take in the euclidean distance measures.
X1(x1, y1) = X1(3, 4)
X2(x2, y2) = X2(4, 7)
and we take the value of P = 4
distance = ( (x2-x1)4 + (y2-y1)4 )1/4
distance = ( (4-3)4 + (7-4)4 )1/4
distance = ( (1)4 + (3)4 )1/4
distance = ( 1+81 )1/4
distance = ( 82 )1/4
distance = approx(2)
Hamming distance
This distance measurement technique is more different from that technique we have learned above, The hamming distance is mostly used in text processing or having the boolean vector. Boolean vector means the data is in the form of binary digits 0 and 1. So, the hamming distance calculates the distance between two binary vectors, also referred to as binary strings.
Suppose we have two points X1 and X2 and both of them are boolean vectors, represented as:
X1 = [ 0,0,0,1,0,1,1,0,1,1,1,0,0,0,1]
X2 = [ 0,1,0,1,0,1,0,0,1,0,1,0,1,0,1]
So more simply the hamming distance of (X1, X2) is the location where the binary vectors or numbers are different. let’s simplify for you;
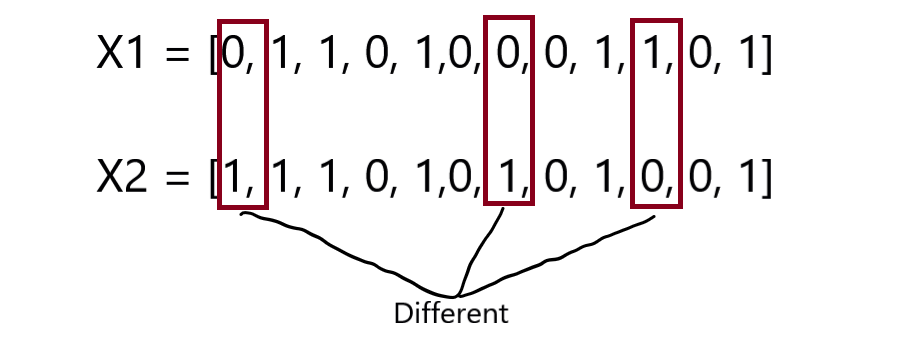
As you see in the above image that there are 3 locations where the binary numbers are different or we can say that the one respective number doesn’t match with the other one respectively.
So, we can say that the hamming distance of these two boolean vectors is 3. let’s see more mathematically.
Hamming distance(X1, X2) = 3 ……… {place where binary vectors are differ}
So this is the fundamental knowledge of the distance measures when we use KNN and other algorithms.
Example:
SO, this distance measure is different from the above 3, Suppose we have a problem that finds the number of locations where the string is different?
string1 = a n d v j s k e
string2 = a n r v j a k c
So you can notice that at 3 locations the string is different.
EndNote
Generally, the above takes detailed knowledge of how distance is measured and learn some different techniques for distance measures. Although this will not end here there are 100s of distance measurement techniques for finding the distance, so we generally discussed important ones.
Connect with me on Linkedin: Mayur_Badole
Prefer my other blog too: Profile
Thank You.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.






