Introduction
Did you know that the Indian cricket team relies heavily on data analytics to decide their strategy for an upcoming match? Batsmen are told where a bowler typically pitches during the death overs, bowlers are shown various visualizations to help them understand the weak spots of opposition batsmen, and so on.
Honestly, with the unprecedented rise in data generation and collection – sports teams and franchises around the world are tapping into the seemingly infinite trove of data at our fingertips. Sports analytics is a thriving field.
And cricket, as you can imagine, is ripe with data points. It’s a battle between bat and ball played across different formats and different levels. The ball-by-ball analysis of matches can produce some surprising hidden insights, such as batting partnerships and who the best batting partner is (the idea behind network analysis and this article).
And the shortest version of cricket, the T20, generates an incredible number of points to analyze and interpret. I love pouring over these datasets and finding features other folks might have missed.
So that’s what we’ll do in this article. We will learn the concept of network analysis and apply that on IPL 2019 data to analyze who the best batsman to partner with is. Ready to dive in and be surprised?
Note: I assume basic knowledge about the rules of cricket and the concept of graph theory. Here’s a quick refresher if you need one:
Table of Contents
- The Role of Statistics in Cricket
- Significance of Batting Partnerships
- Network Analysis of Batting Partnerships
- An Overview of a Batting-Partnership Network
- Network Interpretation and Inferences
- Implementing Network Analysis in Python for IPL 2019
The Role of Statistics in Cricket
Statistics have always had a significant role in sports. As I mentioned above, sports analytics is on the rise and will continue to play a significant role in how teams operate, pick their players, how they play the game, etc.
Cricket is no different. The runs scored by a batsman, the wickets taken by a bowler, or the matches won by a cricket team – these are all examples of the most important numbers in the game of cricket.

A Cricket Scorecard
Maintaining a record of all such statistics has multiple benefits. The teams and the individual players can dig deep into this data and find areas of improvement. It can also be used to assess an opponent’s strengths and weaknesses.
Below you can see a snapshot of a few key statistics of Virat Kohli, one of the best batsmen in cricket:

This record gives us quite a lot of useful information, such as:
- The batting average in different formats
- Number of times the batsman scored >= 100 runs
- Highest scores of the batsman
- Number of matches played, etc.
An extensive exploratory analysis of this well-structured data can be helpful in comparing multiple players.
Think about it – we can try to answer the age-old questions like who’s the all-time best batsman? Was Courtney Walsh better than Curtley Ambrose? And so on.
This analysis would be based on their individual records. Imagine the amount of fun we can have using this data!
However, there are many crucial insights that are difficult and cumbersome to obtain by using only traditional data analysis techniques. Since cricket is a team game, it involves interaction among the players within a team as well as with those in the opposition team.
It is quite difficult to win matches if individuals focus on their respective performances only. They have to support their fellow players as well, right?
This aspect of the game is quite obvious, especially during batting. There are always going to be two batsmen at the crease. Sp in the next section, we will discuss the importance of batting partnerships in cricket.
Significance of Batting Partnerships
Who’s your favorite opening batting partnership? I used to love watching Sachin Tendulkar and Sourav Ganguly open the innings – that left-right hand combination was deadly.
Healthy batting partnerships have a strong role in building high scores for the team. Good partnerships during the early stage of an innings give a solid foundation to the subsequent batsmen to play freely and score runs according to the situation (regardless of the format of the game).
Let’s have a look at a partnership chart taken from a T20 match between India and Sri Lanka that took place on 7th January 2020:

Sri Lanka batted first and scored 142. India easily overcame this target and won the match.
The chart above shows a comparison of batting partnerships between the two teams. As you can see, Sri Lanka had only 1 decent partnership (Mathews and de Silva). On the other hand, India had three good partnerships of 97, 42, and 37 runs.
I’m sure all you cricket diehards will be picking out your favorite partnerships you’ve seen over the years. There have been plenty of them across cricket – just pick your top 5 and this pattern should come out there!
In the next section, I will introduce my approach to quantify batting partnerships for an entire tournament.
Network Analysis of Batting Partnerships
My approach is inspired by this wonderful paper – Complex Network Analysis in Cricket by Satyam Mukherjee.
I have opted for network analysis because it can easily show us the big picture, i.e., give more insights than many other traditional analyses when we have interactions among the players.
In this article, I will show you how I have done network analysis of batting partnerships in IPL 2019. You can follow along with me here – and then apply your knowledge on the IPL 2020 data that will come up once the tournament begins!
For the uninitiated, IPL (Indian Premier League) is a yearly T20 cricket tournament that takes place in India. There are eight teams in IPL, each consisting of local and international players:

An Overview of the Batting-Partnership Network
The idea is to build a network for a single team, where the nodes are the batsmen that batted for the team during the entire tournament (IPL 2019). If any two batsmen batted together even once, then they would have an edge between them.
The edges will have directions, i.e, each edge will point from one node to another. This direction will tell who contributes more to the partnership.
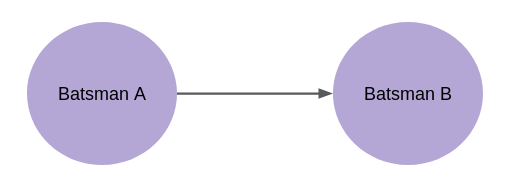
For example, in the figure above, the overall contribution of Batsman B is more than that of Batsman A, taking into account all the partnerships they have had together.
But, wait a second! What exactly is this “overall contribution”?
Well, this is essentially a performance metric. Let me show you how it’s computed.
Let’s say batsman A and batsman B have had 6 partnerships in a cricket tournament (pick any 2 batsmen you like). Given below are the bar charts of the individual scores in every partnership they put up together:
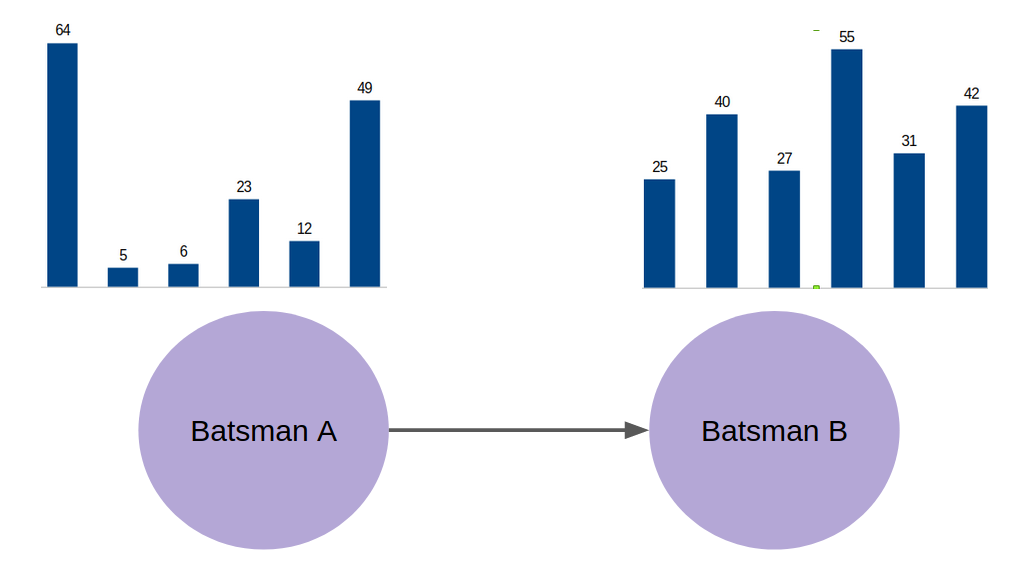
We can clearly see that Batsman B has been more consistent in scoring runs as compared to Batsman A. However, we can’t rely on our visual inspection to find the better batsman in a pair. We should come up with some metric to determine who was the better batsman.
We will follow the below steps to compute this performance metric:
- Compute the individual median values of the runs scored by the two batsmen
- Median score of Batsman A is 17.5 and that of Batsman B is 35.5
- Then find the ratio of the larger value to the sum of the two median values. Hence, in this case, the ratio will be 35.5/(17.5 + 35.5)
Below is the batting-partnership graph of one of the most successful teams in the IPL era, Chennai Super Kings (CSK):

Chennai Super Kings Batting Partnership Network
Let’s see how we can interpret this graph and what sort of insights we can get from it.
Network Interpretation and Inferences
In the graph above, there are 17 nodes and 40 edges with directions. This means that during IPL 2019, 17 players batted for CSK and there were 40 unique pairs of players who batted together.
Let’s see the insights we can fetch from this network:
- AT Rayudu built partnerships with the maximum number of players (9) followed by MS Dhoni (8)
- KM Jadhav had the maximum number of incoming edges (5) which means he was the more effective batsman in his partnerships with 5 different players
- AT Rayudu and SR Watson opened the innings for CSK. Rayudu did slightly better than Watson in building partnerships
- We can also infer that a batsman with a high number of edges can adapt to different situations and bat with players of different styles
This network is more useful if we use it for inter-team comparison of players. For example, compare the middle order batsmen across all the teams.
Let’s compare all the opening batsmen of the IPL 2019 semi-finalists. Mumbai Indians (MI), Chennai Super Kings, Sunrisers Hyderabad (SRH), and Delhi Capitals (DC) made it to the semi-finals. I have listed below the openers of these four teams:
| Team | Player |
| DC | PP Shaw |
| DC | S Dhawan |
| CSK | SR Watson |
| CSK | AT Rayudu |
| MI | RG Sharma |
| MI | Q de Kock |
| SRH | JM Bairstow |
| SRH | DA Warner |
By constructing the similar partnership networks for these teams, we can extract the edge count and incoming edge count for each of the above players.
| Team | Player | Runs | Partners | Leading |
| MI | Q de Kock | 500 | 10 | 5 |
| SRH | DA Warner | 692 | 9 | 6 |
| CSK | AT Rayudu | 282 | 9 | 4 |
| CSK | SR Watson | 398 | 7 | 4 |
| DC | S Dhawan | 486 | 7 | 3 |
| SRH | JM Bairstow | 445 | 5 | 3 |
| MI | RG Sharma | 405 | 5 | 3 |
| DC | PP Shaw | 353 | 5 | 3 |
The column ‘Partners’ contains the edge count (number of unique partnerships), and the column ‘Leading’ contains the incoming edge count (number of unique partnerships where the batsman has performed better than his partner).
I have ranked these players based on the edge count and the incoming edge count, giving more preference to the edge count. However, in the case of a tie, I have used the total runs scored by the batsmen.
Now, I am going to add the players’ price to our existing table:
| Team | Player | Runs | Partners | Leading | Price (in Crores) |
| MI | Q de Kock | 500 | 10 | 5 | 2.8 |
| SRH | DA Warner | 692 | 9 | 6 | 12 |
| CSK | AT Rayudu | 282 | 9 | 4 | 2.2 |
| CSK | SR Watson | 398 | 7 | 4 | 4 |
| DC | S Dhawan | 486 | 7 | 3 | 5.2 |
| SRH | JM Bairstow | 445 | 5 | 3 | 2.2 |
| MI | RG Sharma | 405 | 5 | 3 | 15 |
| DC | PP Shaw | 353 | 5 | 3 | 1.2 |
We can list down a few inferences from this table:
- As per this ranking, Q de Kock is on top as he partnered with 10 different batsmen
- DA Warner has also done a great job. However, he was way more expensive than Q de Kock
- Surprisingly, AT Rayudu didn’t score a bag full of runs. And yet he managed to support the other batsmen and build partnerships
- RG Sharma just couldn’t do justice to his price tag
This is useful information for any team heading into next year’s auction! Can you infer anything else? Let me know in the comments section.
Implementation – Network Analysis of IPL 2019
We’ve covered a significant amount of theory and ideas so far. It’s time to bring it all together and design our network analysis in Python.
I have used Google Colab to implement the code. Feel free to use any IDE of your liking. Let’s get started!
Import Libraries and Data
Let’s first import the required libraries:
I manually collected the batting partnership data from ESPN Cricinfo for the semi-finalists: Mumbai Indians (MI), Chennai Super Kings, Sunrisers Hyderabad (SRH), and Delhi Capitals (DC).
You can download the dataset from here and load it:
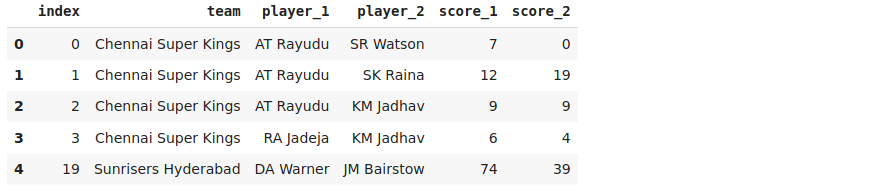
Every row in the dataset represents a batting partnership. The columns player_1 and player_2 contain the batsmen pairs and the columns score_1 and score_2 are the runs scored by them in their respective partnerships, respectively.
Data Preparation
Let’s first prepare the dataset for one of the four IPL teams. We will use that to create the batting-partnership network.

Right now, we have records of all the partnerships for Delhi Capitals during IPL 2019. To construct the network, we need to aggregate this data.
For example, if two players put together 5 partnerships, then we would aggregate it by taking the median values of scores for both the batsmen separately:
Let’s put the aggregated data in a dataframe:

Now that we have the median runs scored by each and every batsman, we can compute the performance metric (overall contribution):
Construct Network
Finally, it’s time to build our partnership network! It is going to be a directed network as the edges in the network will have directions based on the performance metric:
Here’s the code to plot the network:
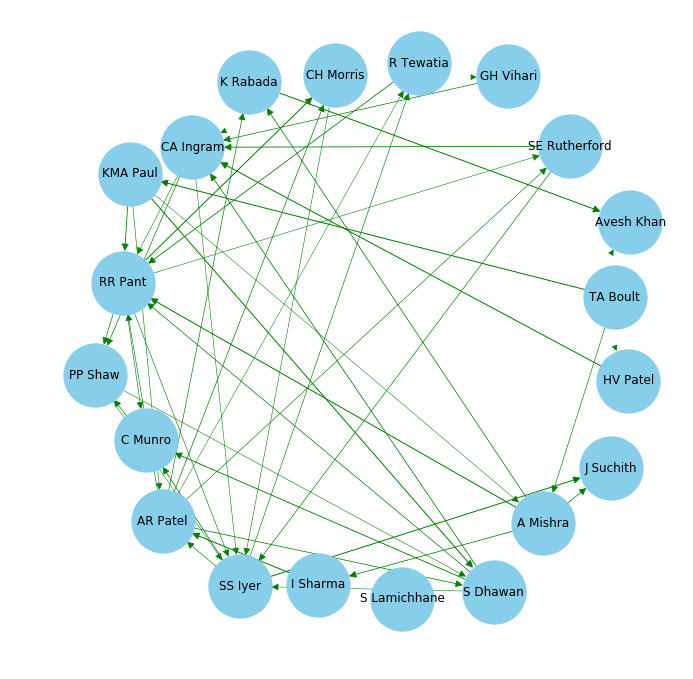
Delhi Capitals Batting-Partnership Network
Similarly, you can plot networks for the other teams as well. We can easily extract the count of edges and incoming edges using the networkx library.
Let’s get the count of all the edges, node-wise:
list(G.degree)
Output:
[(‘PP Shaw’, 5),(‘S Dhawan’, 7),
(‘SS Iyer’, 10),
(‘CA Ingram’, 8),
(‘RR Pant’, 11),
(‘KMA Paul’, 5),
(‘AR Patel’, 9),
(‘R Tewatia’, 3),
(‘GH Vihari’, 3),
(‘HV Patel’, 2),
(‘CH Morris’, 4),
(‘K Rabada’, 4),
(‘Avesh Khan’, 2),
(‘S Lamichhane’, 1),
(‘I Sharma’, 2),
(‘C Munro’, 4),
(‘A Mishra’, 6),
(‘SE Rutherford’, 4),
(‘J Suchith’, 2),
(‘TA Boult’, 2)]
Get the count of incoming edges, node-wise:
list(G.in_degree)
Output:
[(‘PP Shaw’, 3),
(‘S Dhawan’, 3),
(‘SS Iyer’, 6),
(‘CA Ingram’, 5),
(‘RR Pant’, 6),
(‘KMA Paul’, 1),
(‘AR Patel’, 3),
(‘R Tewatia’, 2),
(‘GH Vihari’, 1),
(‘HV Patel’, 1),
(‘CH Morris’, 2),
(‘K Rabada’, 2),
(‘Avesh Khan’, 2),
(‘S Lamichhane’, 0),
(‘I Sharma’, 1),
(‘C Munro’, 3),
(‘A Mishra’, 2),
(‘SE Rutherford’, 2),
(‘J Suchith’, 2),
(‘TA Boult’, 0)]
(‘S Dhawan’, 3),
(‘SS Iyer’, 6),
(‘CA Ingram’, 5),
(‘RR Pant’, 6),
(‘KMA Paul’, 1),
(‘AR Patel’, 3),
(‘R Tewatia’, 2),
(‘GH Vihari’, 1),
(‘HV Patel’, 1),
(‘CH Morris’, 2),
(‘K Rabada’, 2),
(‘Avesh Khan’, 2),
(‘S Lamichhane’, 0),
(‘I Sharma’, 1),
(‘C Munro’, 3),
(‘A Mishra’, 2),
(‘SE Rutherford’, 2),
(‘J Suchith’, 2),
(‘TA Boult’, 0)]
End Notes
I had a ball working on this project and this article. I’m deeply passionate about sports, especially cricket, and loved bringing that passion to this project.
Here, we learned how graphs and networks can be used in cricket to discover hidden but crucial insights. Using the techniques and knowledge gained in the article, we can perform network analysis for other sports as well.
If you have any other ideas about the application of graphs and networks, then do let me know in the comments section below.
Prateek Joshi
25 Jul, 2022
Data Scientist at Analytics Vidhya with multidisciplinary academic background. Experienced in machine learning, NLP, graphs & networks. Passionate about learning and applying data science to solve real world problems.








Wonderful Article. Learned a lot. It would be great if we could change the width of the connecting line depending on the Number of Runs Scored or Strike Rate of the partnership. This will make the analysis more robust as one person can build small partnerships with lots of batsmen and can be the best partnership maker, which in reality is not as he was just part of a lot of partnerships that were smaller in number. My reference is w.r.t CSK graph.
Hi Ankur, I didn't change the width of the edges based on the performance metric because the graph did not look aesthetic. However, you can try it at your end.
I have a doubt - If we follow the theory then performance is measured by amount of runs scored in the partnership whereas in code we are measuring the performance by the median value of the score. In theory, there is no use of Median and in code, we never calculate the total runs. Please elaborate on this?
The way you explained the importance of statistics is incredible. I have followed your knowledge on some fantasy apps and it proved as a boon for me. Thank You! for providing such information on the public platform.