Language is a thing of beauty. But mastering a new language from scratch is quite a daunting prospect. If you’ve ever picked up a language that wasn’t your mother tongue, you’ll relate to this! There are so many layers to peel off and syntaxes to consider – it’s quite a challenge to learn what us tokenization NLP.
And that’s exactly the way with our machines. In order to get our computer to understand any text, we need to break that word down in a way that our machine can understand. That’s where the concept of tokenization in Natural Language Processing (NLP) comes in. This process involves breaking down the text into smaller units called tokens. What is tokenization in NLP is essential for various NLP tasks like text classification, named entity recognition, and sentiment analysis.
Simply put, we can’t work with text data if we don’t perform tokenization. Yes, it’s really that important!

And here’s the intriguing thing about tokenization – it’s not just about breaking down the text. Tokenization plays a significant role in dealing with text data. So in this article, we will explore the depths of tokenization in Natural Language Processing and how you can implement it in Python. Also, you will get to know about the what is tokenization and types of tokenization in NLP.
In this article, you will understand what tokenization in NLP is, how tokenization NLP works, and the role of a tokenizer in processing text for natural language understanding.
I recommend taking some time to go through the below resource if you’re new to NLP:
Tokenization is a common task in Natural Language Processing (NLP). It’s a fundamental step in both traditional NLP methods like Count Vectorizer and Advanced Deep Learning-based architectures like Transformers.
Tokens are the building blocks of Natural Language.
Tokenization is a way of separating a piece of text into smaller units called tokens. Here, tokens can be either words, characters, or subwords. Hence, tokenization can be broadly classified into 3 types – word, character, and subword (n-gram characters) tokenization.
For example, consider the sentence: “Never give up”.
The most common way of forming tokens is based on space. Assuming space as a delimiter, the tokenization of the sentence results in 3 tokens – Never-give-up. As each token is a word, it becomes an example of Word tokenization.
Similarly, tokens can be either characters or subwords. For example, let us consider “smarter”:
But then is this necessary? Do we really need tokenization to do all of this?
Note: If you are new to NLP, check out our NLP Course Online
Tokenization is the process of breaking down a piece of text, like a sentence or a paragraph, into individual words or “tokens.” These tokens are the basic building blocks of language, and tokenization helps computers understand and process human language by splitting it into manageable units.
For example, tokenizing the sentence “I love ice cream” would result in three tokens: “I,” “love,” and “ice cream.” It’s a fundamental step in natural language processing and text analysis tasks.
Here is types of tokenization in nlp:
As tokens are the building blocks of Natural Language, the most common way of processing the raw text happens at the token level.
For example, Transformer based models – the State of The Art (SOTA) Deep Learning architectures in NLP – process the raw text at the token level. Similarly, the most popular deep learning architectures for NLP like RNN, GRU, and LSTM also process the raw text at the token level.
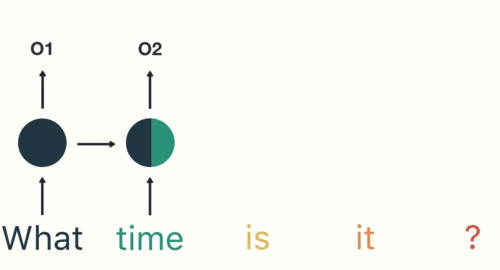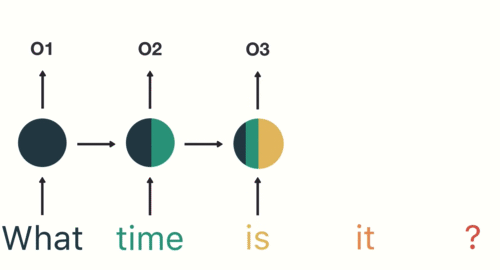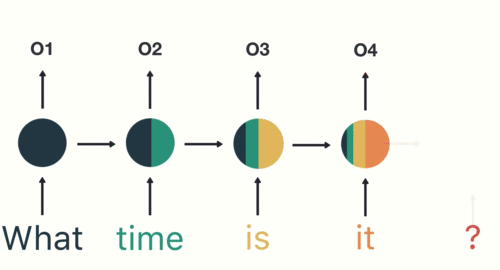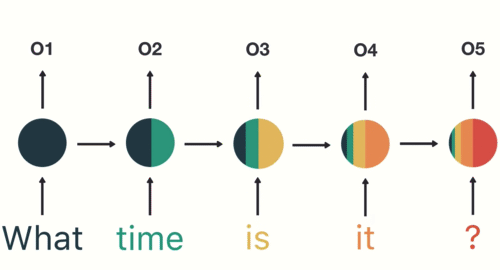
As shown here, RNN receives and processes each token at a particular timestep.
Hence, Tokenization is the foremost step while modeling text data. Tokenization is performed on the corpus to obtain tokens. The following tokens are then used to prepare a vocabulary. Vocabulary refers to the set of unique tokens in the corpus. Remember that vocabulary can be constructed by considering each unique token in the corpus or by considering the top K Frequently Occurring Words.
Creating Vocabulary is the ultimate goal of Tokenization.
One of the simplest hacks to boost the performance of the NLP model is to create a vocabulary out of top K frequently occurring words.
Now, let’s understand the usage of the vocabulary in Traditional and Advanced Deep Learning-based NLP methods.

As discussed earlier, tokenization can be performed on word, character, or subword level. It’s a common question – which Tokenization should we use while solving an NLP task? Let’s address this question here.
Word Tokenization is the most commonly used tokenization algorithm. It splits a piece of text into individual words based on a certain delimiter. Depending upon delimiters, different word-level tokens are formed. Pretrained Word Embeddings such as Word2Vec and GloVe comes under word tokenization.
But, there are few drawbacks to this.
Drawbacks of Word Tokenization
One of the major issues with word tokens is dealing with Out Of Vocabulary (OOV) words. OOV words refer to the new words which are encountered at testing. These new words do not exist in the vocabulary. Hence, these methods fail in handling OOV words.
But wait – don’t jump to any conclusions yet!
Another issue with word tokens is connected to the size of the vocabulary. Generally, pre-trained models are trained on a large volume of the text corpus. So, just imagine building the vocabulary with all the unique words in such a large corpus. This explodes the vocabulary!
This opens the door to Character Tokenization.
Character Tokenization splits apiece of text into a set of characters. It overcomes the drawbacks we saw above about Word Tokenization.
Character tokens solve the OOV problem but the length of the input and output sentences increases rapidly as we are representing a sentence as a sequence of characters. As a result, it becomes challenging to learn the relationship between the characters to form meaningful words.
This brings us to another tokenization known as Subword Tokenization which is in between a Word and Character tokenization.
Also Read- What are Categorical Data Encoding Methods
Python provides several powerful libraries and tools that make it easy to perform tokenization and text preprocessing for natural language processing tasks. Here are some of the most popular ones:
NLTK is a suite of libraries and programs for symbolic and statistical natural language processing. It includes a wide range of tokenizers for different needs:
word_tokenize: Tokenizes a string into word tokens.sent_tokenize: Tokenizes a string into sentence tokens.WordPunctTokenizer: Tokenizes a string into word and punctuation tokens.TweetTokenizer: Tokenizer designed specifically for tokenizing tweets.NLTK tokenizers support different token types like words, punctuation, and provide functionality to filter out stopwords.
spaCy is a popular open-source library for advanced natural language processing in Python. It provides highly efficient tokenization that accounts for linguistic structure and context:
spaCy’s tokenization forms the base for its advanced NLP capabilities like named entity recognition, part-of-speech tagging, etc.
The Hugging Face Tokenizers library provides access to tokenizers from popular transformer models used for tasks like text generation, summarization, translation, etc. It includes:
This library allows you to use the same tokenization as pre-trained models, ensuring consistency between tokenization during pre-training and fine-tuning.
There are also tokenization utilities in other Python data science and NLP libraries like:
The choice of tokenization library depends on the specific NLP task, performance requirements, and whether you need special handling for languages, domains or data types.
Subword Tokenization splits the piece of text into subwords (or n-gram characters). For example, words like lower can be segmented as low-er, smartest as smart-est, and so on.
Transformed based models – the SOTA in NLP – rely on Subword Tokenization algorithms for preparing vocabulary. Now, I will discuss one of the most popular Subword Tokenization algorithm known as Byte Pair Encoding (BPE).
Byte Pair Encoding (BPE) is a widely used tokenization method among transformer-based models. BPE addresses the issues of Word and Character Tokenizers:
BPE is a word segmentation algorithm that merges the most frequently occurring character or character sequences iteratively. Here is a step by step guide to learn BPE.
We will understand the steps with an example.

Consider a corpus:
1a) Append the end of the word (say </w>) symbol to every word in the corpus:

1b) Tokenize words in a corpus into characters:

2. Initialize the vocabulary:

Iteration 1:
3. Compute frequency:

4. Merge the most frequent pair:

5. Save the best pair:

Repeat steps 3-5 for every iteration from now. Let me illustrate for one more iteration.
Iteration 2:
3. Compute frequency:

4. Merge the most frequent pair:

5. Save the best pair:

After 10 iterations, BPE merge operations looks like:

Pretty straightforward, right?
But, how can we represent the OOV word at test time using BPE learned operations? Any ideas? Let’s answer this question now.
At test time, the OOV word is split into sequences of characters. Then the learned operations are applied to merge the characters into larger known symbols.
– Neural Machine Translation of Rare Words with Subword Units, 2016
Here is a step by step procedure for representing OOV words:
Let’s see all this in action next!
We are now aware of how BPE works – learning and applying to the OOV words. So, its time to implement our knowledge in Python.
The python code for BPE is already available in the original paper itself (Neural Machine Translation of Rare Words with Subword Units, 2016)
Reading Corpus
We’ll consider a simple corpus to illustrate the idea of BPE. Nevertheless, the same idea applies to another corpus as well:
Text Preparation
Tokenize the words into characters in the corpus and append </w> at the end of every word:
Python Code:
Compute the frequency of each word in the corpus:
Output:

Let’s define a function to compute the frequency of a pair of character or character sequences. It accepts the corpus and returns the pair with its frequency:
Now, the next task is to merge the most frequent pair in the corpus. We will define a function that accepts the corpus, best pair, and returns the modified corpus:
Next, its time to learn BPE operations. As BPE is an iterative procedure, we will carry out and understand the steps for one iteration. Let’s compute the frequency of bigrams:

Output:
Find the most frequent pair:
Output: (‘e’, ‘s’)
Finally, merge the best pair and save to the vocabulary:

Output:
We will follow similar steps for certain iterations:

Output:
The most interesting part is yet to come! That’s applying BPE to OOV words.
Applying BPE to OOV word
Now, we will see how to segment the OOV word into subwords using learned operations. Consider OOV word to be “lowest”:
Applying BPE to an OOV word is also an iterative process. We will implement the steps discussed earlier in the article:
Output:

As you can see here, the unknown word “lowest” is segmented as low-est.
While basic word and character level tokenization are common, there are several advanced tokenization algorithms and methods designed to handle the complexities of natural language:
An extension of the original BPE, Byte-Level BPE operates on a byte-level rather than character-level. It encodes each token as a sequence of bytes rather than characters. This allows it to:
Byte-Level BPE is used by models like GPT-2 for text generation.
SentencePiece is an advanced tokenization technique that treats text as a sequence of pieces or tokens which can be words, subwords or even characters. It uses language models to dynamically construct a vocabulary based on the input text during training.
Key features of SentencePiece include:
SentencePiece tokenization is used in models like T5, ALBERT and XLNet.
Introduced by Google for their BERT model, WordPiece is a subword tokenization technique that iteratively creates a vocabulary of “wordpieces” – common words and subwords occurring in the training data.
The WordPiece algorithm starts with a single wordpiece for each character and iteratively:
This allows representing rare/unknown words as sequences of common wordpieces.
Used in models like XLNet, this is a data-driven subword tokenization method that creates tokens based on the statistics of the training data. It constructs a vocabulary of tokens (words/subwords) that maximizes the likelihood of the training data.
Some key aspects are:
These advanced techniques aim to strike the right balance between vocabulary size and handling rare/unknown words for robust language modeling.
Tokenization is a powerful way of dealing with text data. We saw a glimpse of that in this article and also implemented tokenization using Python. Go ahead and try this out on any text-based dataset you have. The more you practice, the better your understanding of how tokenization works (and why it’s such a critical NLP concept). Feel free to reach out to me in the comments below if you have any queries or thoughts on this article. Hope you like this article and get an exact information for about tokenization and types of tokenization in nlp. We have provide an exact informat for the tokenization related topic.
Hope you like the article! You will understand what tokenization in NLP is, how tokenization NLP works, and the role of a tokenizer in processing language data effectively.
A. Tokenization in NLP divides text into meaningful units called tokens. For example, tokenizing the sentence “I love reading books” results in tokens: [“I”, “love”, “reading”, “books”].
A. Tokenization is the process of breaking down text into smaller units called tokens, which are usually words or subwords. It’s a fundamental step in NLP for tasks like text processing and analysis.
A. In NLTK (Natural Language Toolkit), tokenization involves breaking text into tokens, such as words or punctuation marks. NLTK provides various tokenizers to handle different text formats and languages.
A. Lemmatization reduces words to their base or root form to normalize them, while tokenization divides text into tokens. Together, lemmatization and tokenization form preprocessing steps in NLP to improve text analysis and machine learning model performance.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








It would be good if you also provide a link to download the "sample.txt" file.
Hi, Download the sample corpus from here
Hi. Thanks for the wonderful posting. May I translate this article into Korean and post it? I will clarify that I just translate it and URL of original post and the author's name.
Hi. I want to know what I should choose between subword tokenization and character-level tokenization. Which one is SOTA?
Comments are Closed