Univariate Data Visualization is a fundamental technique in data analysis that focuses on representing and interpreting a single variable at a time. This article explores the importance of data visualization, particularly for univariate data, and its role in uncovering meaningful insights. We’ll delve into various methods and tools for visualizing both continuous and categorical univariate data using Python libraries such as Matplotlib and Seaborn. From simple scatter plots to more complex violin plots, we’ll cover a range of techniques that help analysts and data scientists effectively communicate patterns, distributions, and trends within single-variable datasets.
The number of variables of interest featured by the data classifies it as univariate, bivariate, or multivariate. For eg., If the data features only one variable of interest then it is a uni-variate data. Further, based on the characteristics of data, it can be classified as categorical/discrete and continuous data.
In this article, the main focus is on univariate analysis data visualization(data is visualized in one-dimension). For the purpose of illustration, the ‘iris’ data set is considered. The iris data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant. The different variables involved in the data set are Sepal Length, Sepal Width, Petal Length, Petal width which is continuous and Variety which is a categorical variable. Though the data set is multivariate in nature, for univariate analysis in python, we consider one variable of interest at a time.
We proceed by first importing the required libraries and the data set. You can download the python notebook and dataset here.

The data set originally in .csv format is loaded into the DataFrame df using the pd.read_csv( ) function of pandas . Then, it displays the DataFrame df.
Before analyzing any data set, inspect the data types of the data variables. Then, one can decide on the right methods for univariate analysis data visualization.
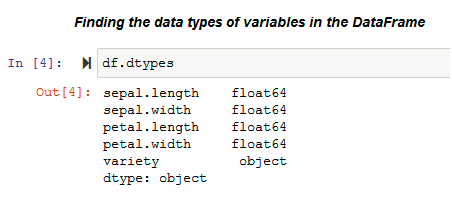
The .dtypes property is used to know the data types of the variables in the data set. Pandas stores these variables in different formats according to their type. Pandas stores categorical variables as ‘object’ and, on the other hand, continuous variables are stored as int or float. The methods used for visualization of univariate data also depends on the types of data variables.
In this article, we visualize the iris data using the libraries: matplotlib and seaborn. We use Matplotlib library to draw basic plots. Seaborn library is based on the matplotlib library and it provides a wide variety of visualization techniques for univariate analysis.
Univariate data visualization plots help us comprehend the enumerative properties as well as a descriptive summary of the particular data variable. These plots help in understanding the location/position of observations in the data variable, its distribution, and dispersion. Uni-variate plots are of two types: 1)Enumerative plots and 2)Summary plots
These plots enumerate/show every observation in data and provide information about the distribution of the observations on a single data variable. We now look at different enumerative plots.
This plots different observations/values of the same variable corresponding to the index/observation number. Consider plotting of the variable ‘sepal length(cm)’ :

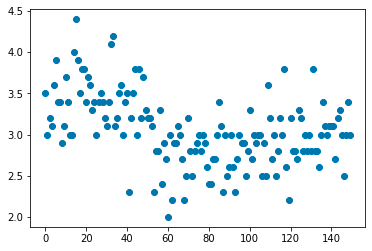
Use the plt.scatter() function of matplotlib to plot a univariate analysis scatter diagram. The scatter() function requires two parameters to plot. So, in this example, we plot the variable ‘sepal.width’ against the corresponding observation number that is stored as the index of the data frame (df.index).
Then visualize the same plot by considering its variety using the sns.scatterplot() function of the seaborn library.

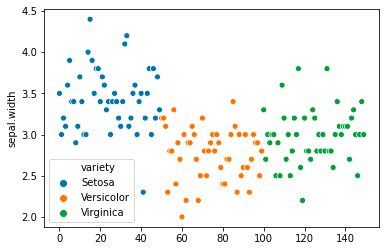
In seaborn, the ‘hue’ parameter, an interesting feature, determines which column in the data frame to use for color encoding. It differentiates data values by their categories, assigning different colors based on the grouping variable provided as input.. The variable passed onto ‘hue’ can be either categorical or numeric, although color mapping will behave differently in the latter case.
Note:Every function has got a wide variety of parameters to play with to produce better results. If one is using Jupyter notebook, the various parameters of the function used can be explored by using the ‘Shift+Tab’ shortcut.
A line plot visualizes data by connecting the data points via line segments. It resembles a scatter plot but differs in that the measurement points are ordered (usually by their x-axis value) and connected with straight line segments.
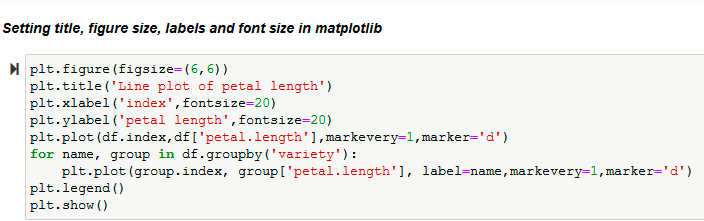
The matplotlib plt.plot() function by default plots the data using a line plot.
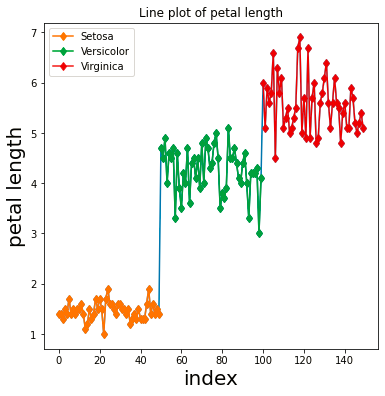
Previously, we discussed the hue parameter of seaborn. While matplotlib does not offer an automated option for this, one can utilize pandas’ groupby() function to plot such a graph effectively.
Note: In the above illustration, we also implement methods for setting title, font size, etc., in matplotlib.
— Explanation of the functions used :
The ‘markevery’ parameter of the function plt.plot() is assigned to ‘1’ which means it will plot every 1st marker starting from the first data point. There are various marker styles which we can pass as a parameter to the function.
The sns.lineplot() function can also visualize the line plot.

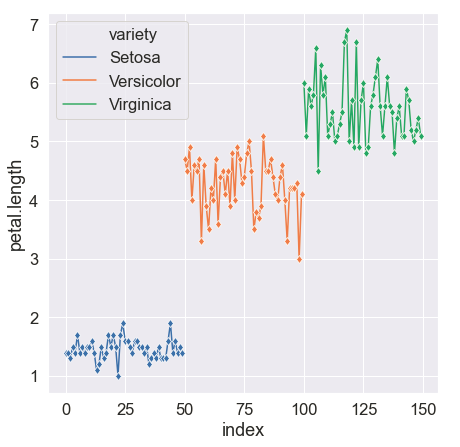
In seaborn, the labels on axes are automatically set based on the columns that are passed for plotting. However if one desires to change it, it is possible too using the set() function.
Note: There are often cases wherein one would want to explore how the distribution of a single continuous variable is affected by a second categorical variable. The seaborn library provides a variety of plots that help perform such types of comparisons between uni-variate distributions. Three such plots are discussed in this article : Strip plot, Swarm plot (under enumerative plots), and Violin plot (under summary plots). The hue parameter mentioned in above plots is also for similar use.
The strip plot is similar to a scatter plot. It is often used along with other kinds of plots for better analysis. It is used to visualize the distribution of data points of the variable.
The sns.striplot ( ) function is used to plot a strip-plot :

It also helps to plot the distribution of variables for each category as individual data points. The function by default creates a vertical strip plot, plotting distributions of continuous data along the Y-axis and spacing categories along the X-axis without consideration in the above plot. Considering the categories helps in better visualization as seen in the below plot.

The swarm-plot, similar to a strip-plot, provides a visualization technique for univariate data to view the spread of values in a continuous variable. The only difference between the strip-plot and the swarm-plot is that the swarm-plot spreads out the data points of the variable automatically to avoid overlap and hence provides a better visual overview of the data.
The sns.swarmplot( ) function is used to plot a swarm-plot :

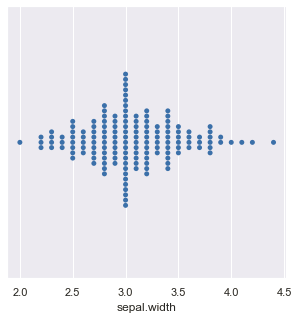
Distribution of the variable ‘sepal.width’ according to the categories :

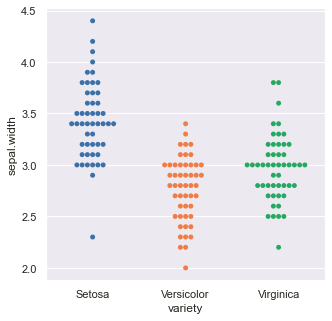
These plots give a more concise description of the location, dispersion, and distribution of a variable than an enumerative plot. Summarizing every individual data value in a plot isn’t feasible, but it efficiently represents the entire dataset, enabling better conclusions to be drawn.
Histograms are similar to bar charts which display the counts or relative frequencies of values falling in different class intervals or ranges. A histogram displays the shape and spread of continuous sample data. It also helps us understand the skewness and kurtosis of the distribution of the data.
Plotting histogram using the matplotlib plt.hist() function :
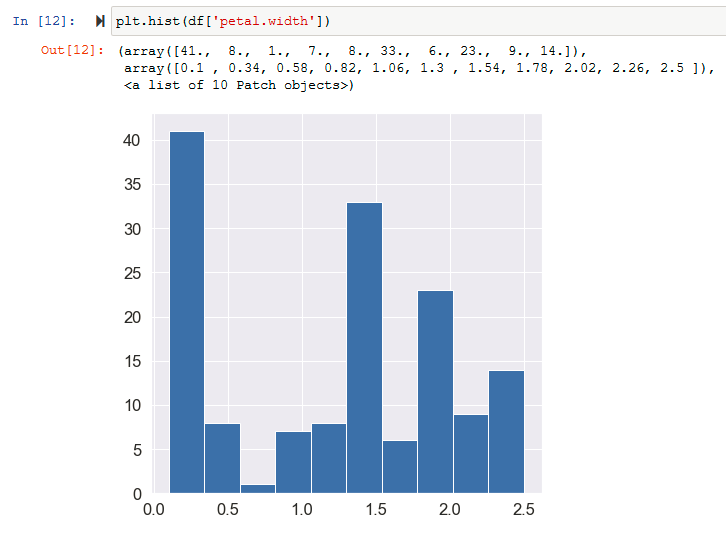
The seaborn function sns.distplot() can also be used to plot a histogram.

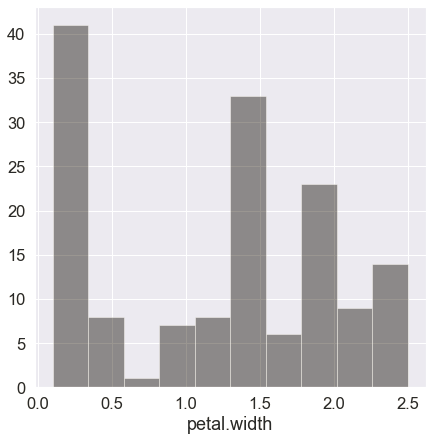
Set the kde (kernel density) parameter to False to display only the histogram. Adjust other parameters like bins (number of bins in the histogram) and color to achieve the desired plot output.
A density plot is like a smoother version of a histogram.In density plots, we use the kernel density estimate to show the probability density function of the variable. The kernel, a continuous curve, is drawn to generate a smooth density estimation for the entire dataset.
Plotting density plot of the variable ‘petal.length’ :

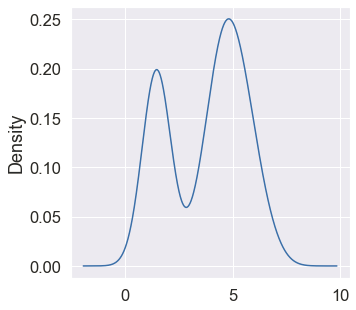

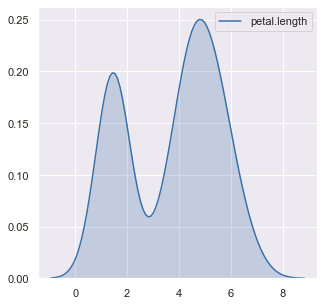
we use the pandas df.plot() function (built over matplotlib) or the seaborn library’s sns.kdeplot() function to plot a density plot . Many features like shade, type of distribution, etc can be set using the parameters available in the functions. By default, the kernel used is Gaussian (this produces a Gaussian bell curve). Also, other graph smoothing techniques/filters are applicable.
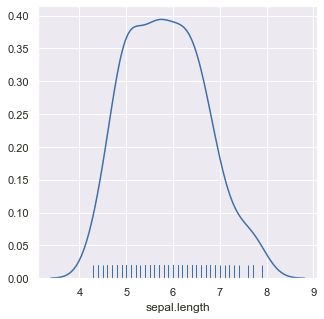
A rug plot is a very simple, but also an ideal legitimate, way of representing a distribution. It consists of vertical lines at each data point. Here, the height is arbitrary. The density of the distribution can be known by how dense the tick-marks are.
The connection between the rug plot and histogram is very direct: a histogram just creates bins along with the range of the data and then draws a bar with height equal to the number of ticks in each bin. In a rug plot, all of the data points are plotted on a single axis, one tick mark or line for each one.
Compared to a marginal histogram, the rug plot suffers somewhat in terms of readability of the distribution, but it is more compact in its representation of the data. A rug is a very short, long display of point symbols, one for each distinct value. The vertical pipe symbol | often minimizes overlap. While a rug plot may not be a primary plot choice, it can support other plots effectively in specific circumstances.
Plotting the rugs of variable ‘sepal .length’ :
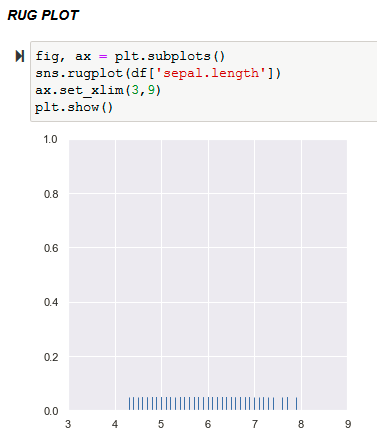
Note :In a few cases, there may be a need to set the range of the values in each axis. In the above illustration, plt.subplots() function that returns a figure object and axes object. Using the axes object ‘ax’ that is passed on to the set_xlim() method, the range of values to be considered on the X-axis is set.
A kernel density estimate can be plotted along with the rugs which can provide a better understanding of the data.
In matplotlib, there is no direct function to create a rug plot. So, we use the scipy.stats module to create the required kernel density distribution, and then we plot it using the plt.plot() function along with the rugs.
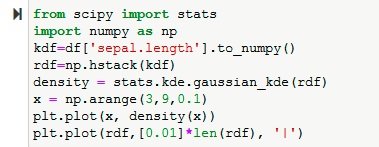
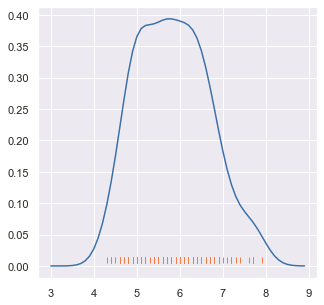
The gaussian_kde() function generates a kernel-density estimate with Gaussian kernels for univariate data. To prepare the input, convert a dataframe to a numpy array using to_numpy() and stack arrays horizontally with np.hstack(). This 1-D array, ‘rdf’, serves as input for gaussian_kde(). Define value ranges using np.arange() and plot using plt.plot() to visualize the results.
Seaborn library provides a direct and easier function to visualize such a plot with many parameters to play with.

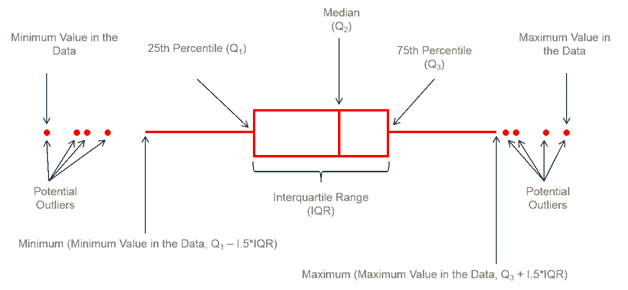
A box-plot is a very useful and standardized way of displaying the distribution of data based on a five-number summary (minimum, first quartile, second quartile(median), third quartile, maximum). It helps in understanding these parameters of the distribution of data and is extremely helpful in detecting outliers.
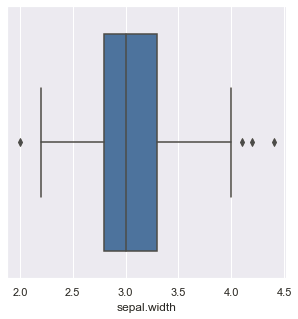
Plotting box plot of variable ‘sepal.width’ :

Plotting box plots of all variables in one frame :
Since the box plot is for continuous variables, firstly create a data frame without the column ‘variety’. Then drop the column from the DataFrame using the drop( ) function and specify axis=1 to indicate it.

In matplotlib, mention the labels separately to display it in the output.
The plotting box plot in seaborn :

Plotting the box plots of all variables in one frame :

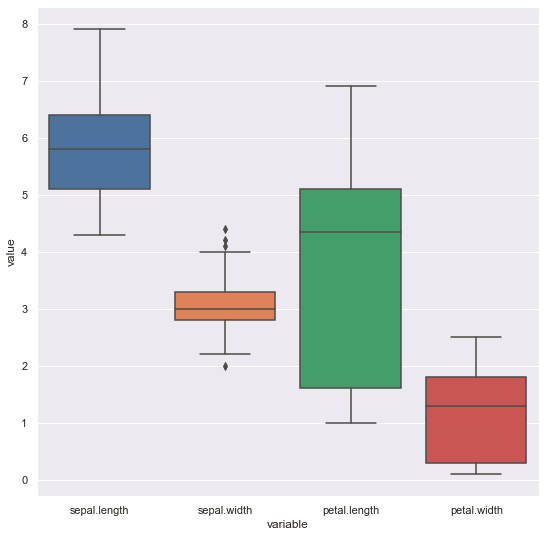
Pass the modified data frame through the pandas function pd.melt() and then to the sns.boxplot() function.
The distplot() function of seaborn library was earlier mentioned under rug plot section. This function combines the matplotlib hist() function with the seaborn kdeplot() and rugplot() functions.

The Violin plot is very much similar to a box plot, with the addition of a rotated kernel density plot on each side. It displays how quantitative data are distributed across multiple levels of one (or more) categorical variables, allowing for comparisons between these distributions.
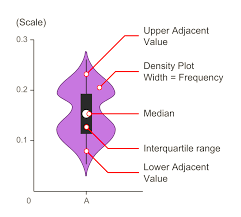

We use plt.violinplot( ) function. The Boolean parameter ‘showmedians’ is set to True, due to which the medians are marked for every variable. The violin plot helps to understand the estimated density of the variable.
In the seaborn library too, the function used to plot a violin plot is similar.

Comparing the variable ‘sepal.width’ according to the ‘variety’ of species mentioned in the dataset :

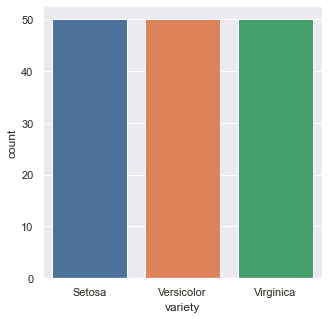
The bar plot is a univariate data visualization plot on a two-dimensional axis. One axis is the category axis indicating the category, while the second axis is the value axis that shows the numeric value of that category, indicated by the length of the bar.
The plot.bar() function plots a bar plot of a categorical variable. The value_counts() returns a series containing the counts of unique values in the variable.

The countplot() function of the seaborn library obtains a similar bar plot. There is no need to separately calculate the count when using the sns.countplot() function.
Since the variety is equally distributed, we obtain bars with equal heights.

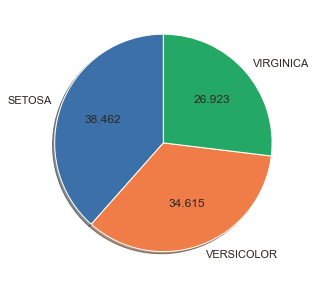
To visualize the numerical proportion occupied by each category, use the plt.pie() function. Divide the sections equally in the pie chart since the categories are equally distributed. Then, pass the array of values to the ‘labels’ parameter to add labels.

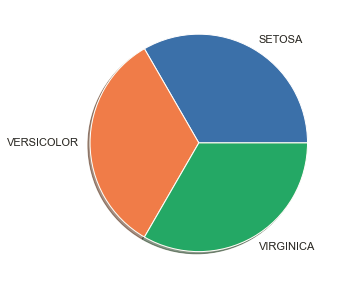
The ‘startangle’ parameter of the pie() function rotates everything counter-clockwise at a specific angle. Further, the default value for startangle is 0. The ‘autopct’ parameter enables one to display the percentage value using Python string formatting.


Most of the methods that help in the visualization of univariate data have been outlined in this article. As stated before the ability to see the structure and information carried by the data lies in its visual presentation.
Data visualization is a powerful tool for revealing trends, patterns, and insights in data. This article explored various techniques for visualizing univariate analysis in python continuous and categorical data using Python libraries like Matplotlib and Seaborn. We covered enumerative plots such as scatter plots and line plots, as well as summary plots like histograms, density plots, box plots, and violin plots. For categorical data, bar charts and pie charts were discussed. The choice of visualization depends on the data type and analysis goals. Combining multiple visualization techniques can provide a comprehensive view of the data, enabling better understanding and decision-making.
A. A univariate visualization displays and analyzes the distribution of a single variable, helping to understand its characteristics and patterns.
A. An example of univariate data is the heights of students in a class. This data set involves only one variable, height.
A. Univariate data can be described using summary statistics like mean, median, and standard deviation. It can be visualized with histograms, box plots, and density plots.
A. Univariate analysis in python examines one variable at a time. Bivariate analysis explores the relationship between two variables. Multivariate analysis investigates the relationships among three or more variables, using techniques like scatter plot matrices and heatmaps.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








Thanks so much for this awesome article
Beautifully and logically well explained all data graphs. Thanks