This article was published as a part of the Data Science Blogathon.
Introduction
As a programmer who is engaged in the field of AI and Machine Learning related activities, it is very important for him/her to perform AI-related stuff most efficiently. The efficient way here in this context means that he/she should be well capable of getting the best predictive analysis result when feeding it to the Machine learning model and to achieve this efficiency many preprocessing steps are required before the prediction to be made.

These preprocessing steps are data handling, manipulations, creation of features, updating the features, normalizing data, etc. From all these preprocessing steps present out there one of the main steps is to do the feature selection. As we know that Machine learning is an iterative process in which the machine tries to learn based on the historical data we are feeding to it and then makes predictions based on the same.
The data we feed is nothing but a combination of rows and columns of information bound within. This columnar information is independently called a feature. Here, the categorization of features is made into two parts that are, a dependent feature and an independent feature. Dependent features are those which we need to predict that is, our target feature, and the independent ones are those on which we make the Machine learning model.
It is very important that the independent features to be highly related to the dependent one. But, this fails to happen in the real world and we may end up with a poor model. To help in improving the efficiency we need to perform feature selection. Generally, there a few feature selection techniques that one should definitely know to help improve their ML model and the same has been discussed below in detail:
Common Feature Selection Filter Based Techniques
1. Feature Selection with the help of Correlation:
This is the most common type of feature selection technique that one should know to get a fairly good model. The feature selected with the help of this technique is based on the statistical relationship that we were taught in our school times. This means that features that have a high correlation with the target variable are taken into consideration and the ones with the low correlation with the target are neglected.
This can also be done with the help of only independent features i.e., if the correlation between two independent features is high then we may drop one of them and if the correlation is low then we can proceed further. The statistical equation of the correlation (X and y) is given as:
Covariance(X,y) / Standard deviation (X) . Standard deviation (y)
The correlation method we generally prefer is the Pearson Correlation which has a range of -1 to +1. Here — means strong negative correlation and +1 means strong positive correlation. The features that have a very low correlation with the target that is, below 0.3 or 30% are neglected.
The correlation can be performed with the help of Python very easily and the same has been depicted below with the help of Seaborn and Pandas library:
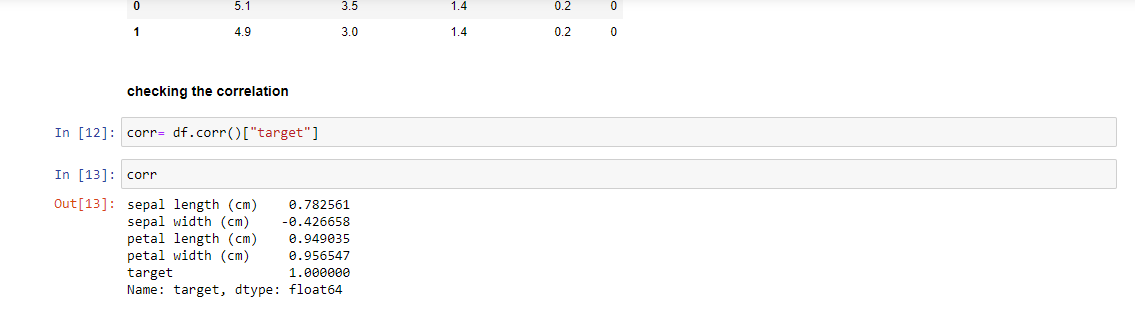
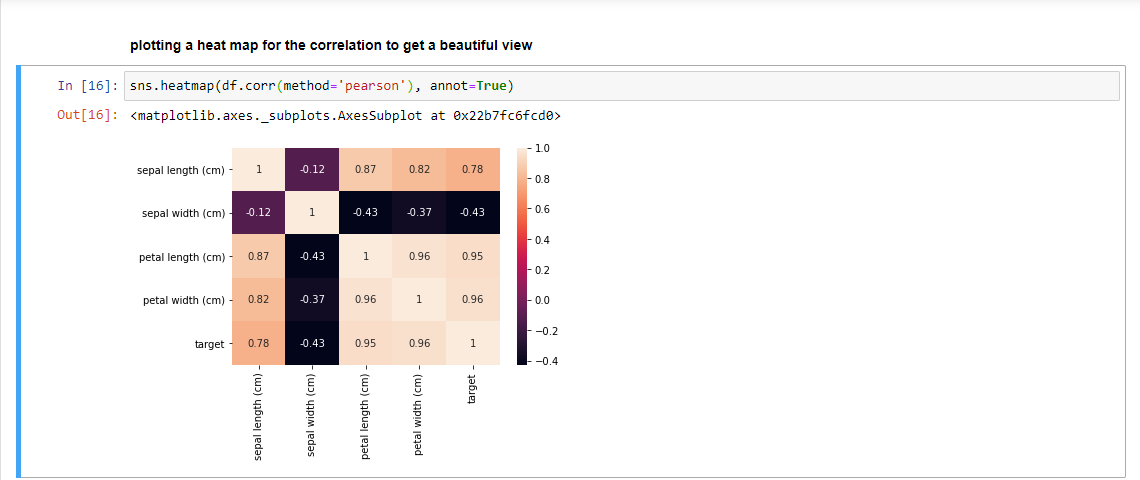
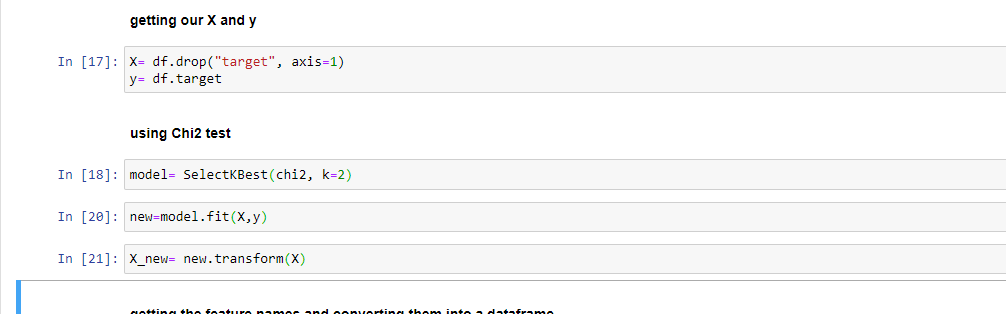
2. Feature Selection with the help of the Chi-Square Test:
This is a form of non-parametric test (a test wherein median is an important parameter) in which feature selection is done with the help of hypothesis testing and p-value. The feature selection is only suited to categorical features or features having discrete data contained within it. The continuous features are not taken into account and therefore should not be used while performing this test. The formula for this type of test is given as:
Summation (Observed Value – Expected Value) / Expected Value
If the p-value is less than 0.05 then we reject the null hypothesis and go with the alternate hypothesis in this type of test. The implementation of Chi-Square with the help of the Scikit Learn library in Python is given below:
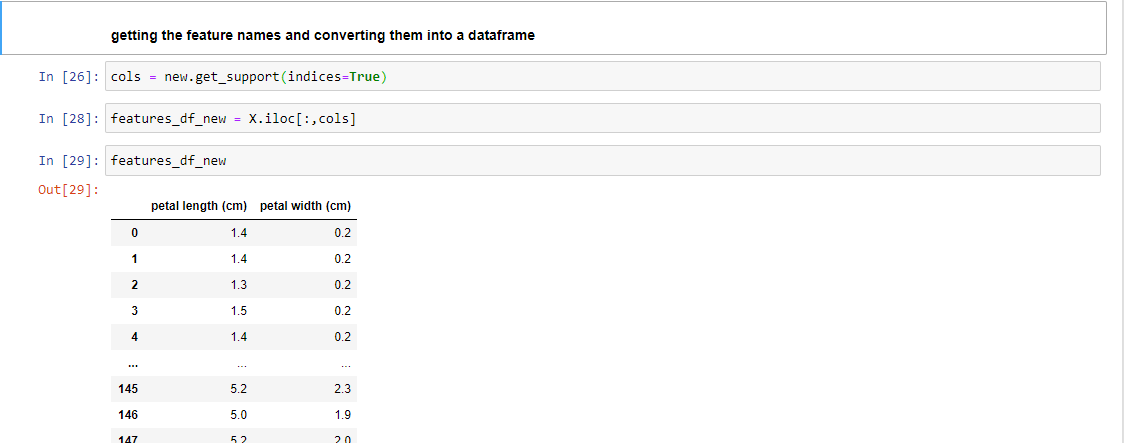
3. Feature Selection with the help of Anova Test:
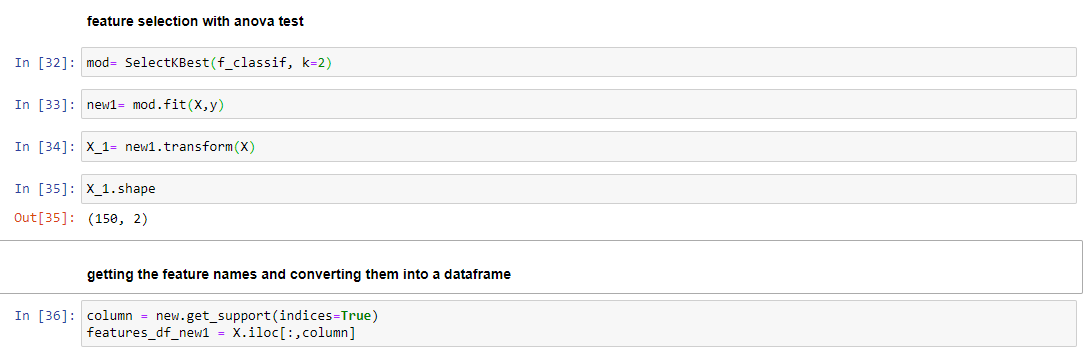
A feature selection technique is most suited to filter features wherein categorical and continuous data is involved. It is a type of parametric test which means it assumes a normal distribution of data forming a bell shape curve. There are many types of Anova test out there and a user can try out these as per their need. The assumption here is made as per the hypothesis testing where the null hypothesis states that there is no difference in the means and alternate says that there is a difference. If the p-value is less than 0.05 then the null hypothesis is rejected and the features are selected or else dropped if the null hypothesis becomes true. The implementation of this feature selection technique is given below with the help of Scikit Learn library:
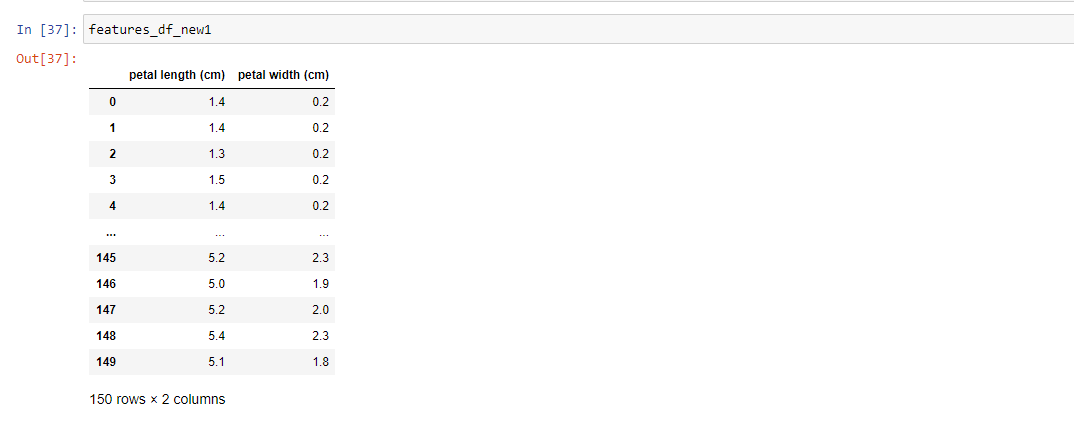
Conclusion
So, these are the most common feature selection filter based techniques that one should learn to make their model a good fit for the Machine learning algorithm and to attain higher accuracies.





