A Short Intuitive Explanation of Convolutional Recurrent Neural Networks
This article was published as a part of the Data Science Blogathon.
Introduction
Hello! Today I am going to try my best in explaining in an intuitive way how Convolutional Recurrent Neural Networks (CRNN) work. When I first tried learning about how CRNN work, I found that the information was split between multiple sites and different levels of “depth” was also present, so I will try to explain them in a way that by the end of this article you will know how exactly do they work and why do they perform better in some categories than others.
In this article, I will assume you already know a bit about how a simple Neural Network works. In case you need a little revision of the way it works or even if you don’t know at all how they work, I recommend you watch the well-made videos explaining the way they work that I linked at the end of the article. I will provide all the information I consider needed for understanding intuitively how CRNN works.
In this article we will cover the following topics, so feel free to skip the ones you already know about:
- What are Convolutional Neural Networks, how do they work and why do we need them?
- What are Recurrent Neural Networks, how do they work and why do we need them?
- · What are and why do we need Convolutional Recurrent Neural Networks? +example for Handwritten Text Recognition
- · Further reading and links
What are Convolutional Neural Networks, how do they work and why do we need them?
The easiest one to answer is the last question, why do we need them? For that, let’s take an example. Let’s say we want to discover if in the image we have a cat or a dog. To simplify the explanation, let’s think of a 3×3 image first. In this image, we have an important feature in the blue rectangle (like the face of a dog, or a letter, or whatever the important feature is).
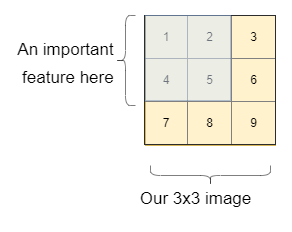
Let’s see how a simple Neural Network would recognize the importance and the link between the pixels.
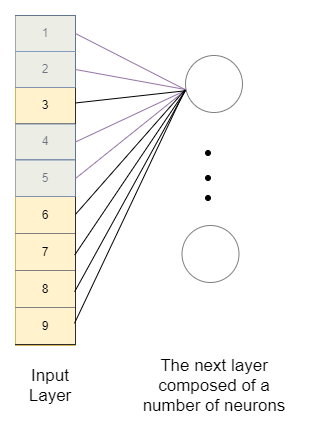
As we can see, we will need to “flatten” the image in order to feed it to a dense Neural Network. By doing so, we lose the spatial context in the image of the entire feature with the background and as well as the pieces of the feature to each other. Imagine how hard it will be for the Neural Network to learn that they are related. Moreover, we will have a lot of weights to train, so we will need more data and therefore more time to train it.
So, we can see multiple problems with this approach:
- The spatial context is lost
- A lot more weights for bigger images
- More weights result in more time and more data needed
Only if there was another way… Wait! There is! This is where Convolutional Neural Networks jumps in to save the day. Their main role is to extract relevant features from the input (an image for example) by using filters. These filters are firstly chosen randomly and then trained just like weights are. They are modified by the Neural Network in order to extract and find the most relevant features.
Okay, so we established so far that Convolutional Neural Networks, which I will use as CNN, use filters in order to extract features. But what exactly are filters and how do they work?
Filters are matrixes containing different values that slide over the image (for example) in order to analyze the features. If the matrix is, for example, 3x3x3, the feature extracted will be of size 3x3x3. If the matrix is of size 5×5, the feature that it will detect will have a maximum size of 5×5 in the image, and so on. By analyzing a window of pixels, we understand element-wise multiplication between the filter and the window covered.
So, for example, if we have an image with a size of 6×6 and a filter of 3×3, we can imagine the filter sliding over the image, and every time it lands on a new window, it analyzes it, which we can see represented in the image below, only for the first two rows of the image:
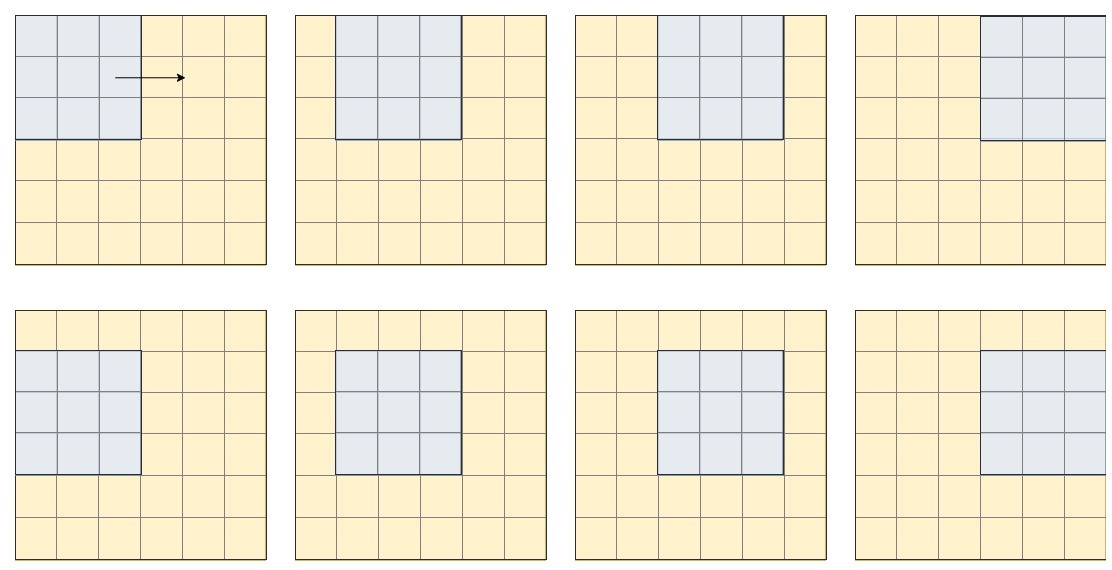
Depending on what we need it to extract, we can change the step of the filter (vertically as well as horizontally, in the example above, the filter takes one step in both directions).
After we do the multiplication (element-wise), the result becomes the new pixel in the image. So after “analyzing” the first window, we get the first pixel in our image, and so on. We see that in the case presented above, the final image will have a size of 5×5.To have the final image with the same size, we can apply the filters after imaginary padding the image (adding an imaginary row and column at the beginning and end), but the details are for another time to discuss.
In order to see even better how convolution works, we can look at examples of filters and the effect that they cause on the output image:

We can see how different filters detect and “extract” different features. The role of training a Convolution Neural Network is to find the best filters in order to extract the most relevant feature for our task.
So, to conclude the part about Convolution Neural Networks, we can summarize the information in 3 simple ideas:
- What are they: Convolutional Neural Networks are a type of Neural Networks that use the operation of convolution (sliding a filter across an image) in order to extract relevant features.
- Why do we need them: They perform better on data (rather than using normal dense Neural Networks) in which there is a strong correlation between, for example, pixels because the spatial context is not lost.
- How do they work: They use filters in order to extract features. The filters are matrixes that “slide” over the image. They are modified in the training period in order to extract the most relevant features.
What are Recurrent Neural Networks, how do they work and why do we need them?
While Convolutional Neural Networks help us at extracting relevant features in the image, Recurrent Neural Networks help the NNet to take into consideration information from the past in order to make predictions or analyze.
Therefore if we have, for instance, the following array: {2, 4, 6}, and we want to predict what comes next, we can use a Recurrent Neural Network, because, at every step, it will take into consideration what was before it.
We can visualize a simple recurrent cell, as shown in the image below:
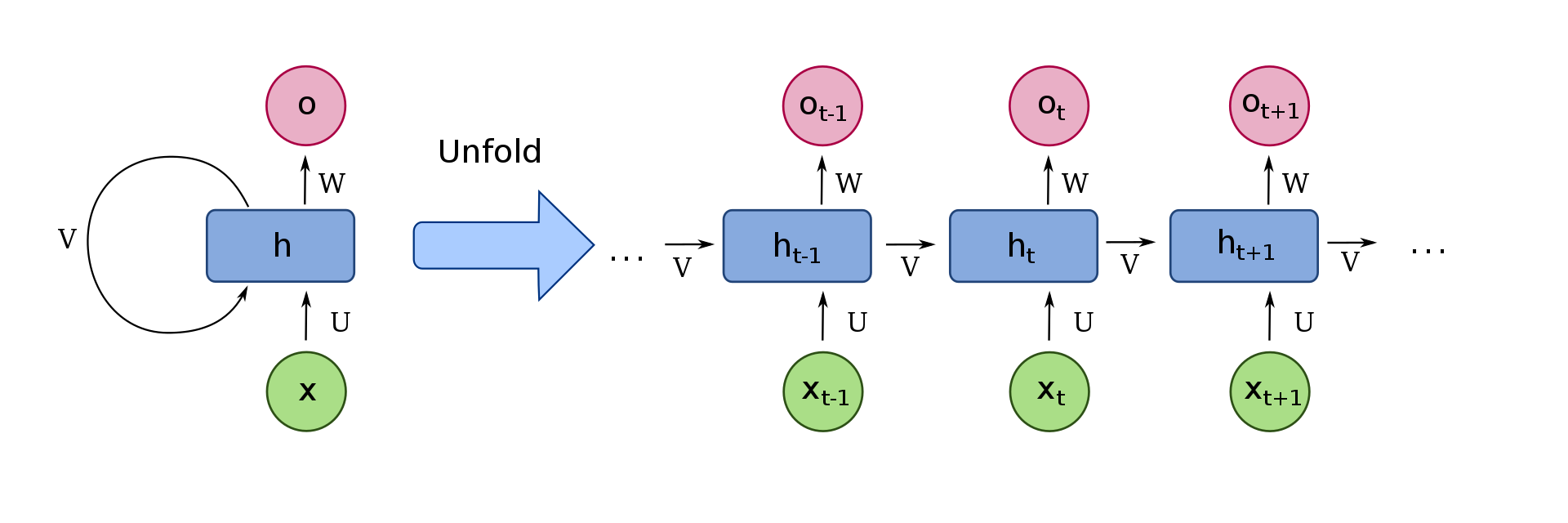
First, let’s focus on the right side of the image only. Here, xt are the inputs received at the timestep t. To follow the same example, these could be the numbers from the array mentioned earlier, x0 = 2, x1 = 4, x2 = 6. In order to take into consideration what was before the time-step, the property that makes them part of a Recurrent Neural Network, we have to receive information from the previous time-step, which in this image we have represented as v. Each cell has a so-called “state”, which intuitively holds the information that is then sent to the next cell.
So to recap, xt is the input of the cell. The cell then decides what is the important information, taking into consideration information from previous timesteps, received through the “v”, and sends it to the next cell. Moreover, we have the choice if we want to return this important information that the cell considered, through the “o” in the image, the output of the cell.
To represent the process mentioned earlier in a more compact way, we can “fold” the cells, represented in the left part of the image.
We won’t go into detail about the exact type of recurrent cells, as they are a lot of options, and explaining in detail how they work would take us a bit too long. If you are interested, I left some links I found very useful at the end of the article.
What are and why do we need Convolutional Recurrent Neural Networks?
+example for Handwritten Text Recognition
We now have all the important information to understand how a Convolutional Recurrent Network works.
Most of the time, the Convolutional Neural Network analyzes the image, sending it to the recurrent part of the important features detected. The recurrent part analyzes these features in order, taking into consideration previous information in order to realize what are some important links between these features that influence the output.
To understand a bit more about how a CRNN works in some tasks, let’s take Handwritten Text Recognition as an example.
Let’s imagine we have images containing words, and we want to train the NNet in order to give us what word is initially in the image.
Firstly, we would want our Neural Network to be able to extract important features for different letters, such as loops from “g” or “l”, or even circles from “a” or “o”. For this, we can use a Convolutional Neural Network. As explained earlier, CNN uses filters in order to extract the important features (we saw how different filters have different effects on the initial image). Of course, these filters will detect in practice more abstract features that we can’t really understand, but intuitively we can think of simpler features, such as the ones mentioned earlier.
Then, we would want to analyze these features. Let’s take a look as to why we can’t decide what a letter is based solely on its own features. In the image below, we see that the letter is either “a” (from “aux”) or “o” (from for).
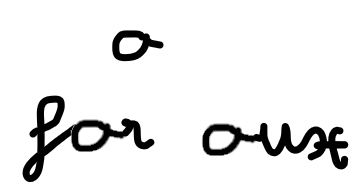
The difference is made by the way the letter is linked to the other letters. So we would need to know information from previous places in the image in order to determine the letter. Sounds familiar? This is where the RNN part comes in. It analyzes recursively the information extracted by the CNN, where the input for each cell might be the features detected in a specific slice of the image, as represented below, with only 10 slices (less than we would use in real models):
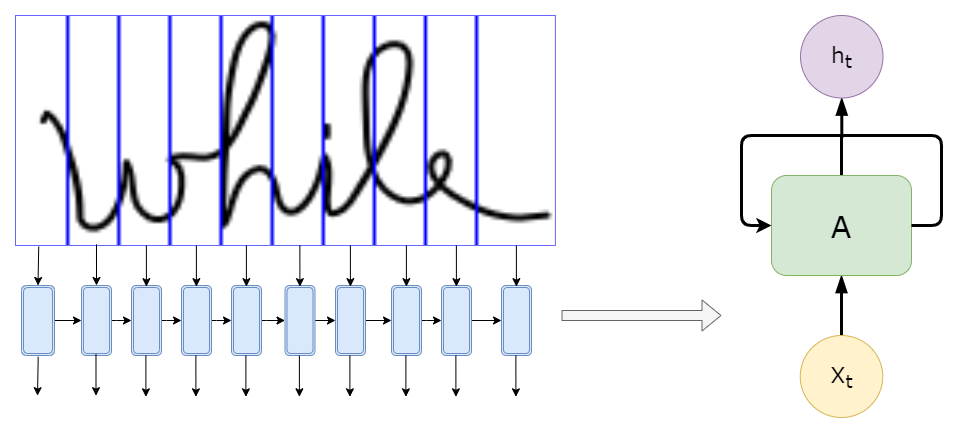
We don’t feed the RNN the image itself, as shown in the above image, but rather the features extracted from that “slice”.
We might also see that processing the image forward is as important as processing the image backward, so we can add a layer of cells that process the features in the other way, taking into consideration both of them when computing the output. Or even vertically, depending on the task at hand.
Hooray! We finally have the image analyzed: the features extracted and analyzed in relation to one another. All we have to do now add a layer that calculates the loss and an algorithm that decodes the output, for this, we might want to use a CTC (Connectionist Temporal Classification) for Handwritten Text Recognition, but that is an interesting subject on its own and I think it deserves another article.
Conclusions
In this article, we discussed shortly how Convolutional Recurrent Neural Networks work, how they analyze and extract features and an example of how they could be used.
The Convolutional Neural Network extracts the features by applying relevant filters and the Recurrent Neural Network analyzes these features, taking into consideration information received from previous time-steps.








