Introduction

Deep reinforcement learning has a variety of different algorithms that solves many types of complex problems in various situations, one class of these algorithms is policy gradient (PG), which applies to a wide range of problems in both discrete and continuous action spaces, but applying it naively is inefficient, because of its poor sample complexity and high variance, which result in slower learning, to mitigate this we can use a baseline.
In this article, I will explain:
- What are baselines and how they reduce the variance of the policy gradient?
- How we choose a good baseline with two examples.
Let us dive in 🙂
Baselines
Recall that the formula of policy gradient is
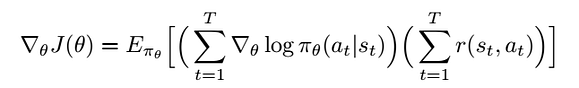
In practice, we approximate this expectation by taking N samples and average their values.
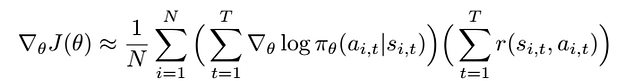
The cause of the high variance problem is the reward scale, we think of policy gradient as it increases the probability of taking good actions and decreases it for bad actions, but mostly this is not the case, imagine a situation where the “good” episode return was 10 and the “bad” one was 5, then both probabilities of the actions in those episodes will be increased, which is not what we want, this problem is what baselines can solve.
Mathematically, a baseline is a function when added to an expectation, does not change the expected value (or does not introduce bias), but at the same time, it can significantly affect the variance.
Following this definition, we want a baseline for the policy gradient that can reduce its high variance and does not change its direction, a natural thing to do is to take the actions that are better than average, increase their probability, and decrease the probability of the actions that are worse than average, this is implemented by calculating the average reward over the trajectory and subtract it from the reward at the current timestep, this kind of baselines is called the average reward baseline.
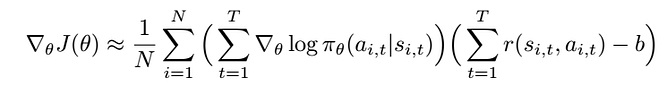
where b is the average reward over the sampled trajectories
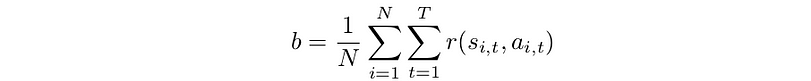
Now, we will show how baselines do not change the expected value, and we can choose any baselines we want.
For notational convenience, we will write the policy gradient in the form
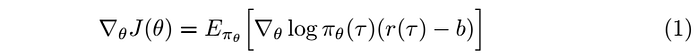
where
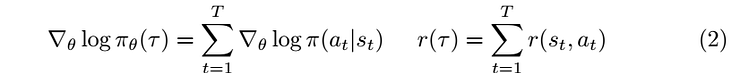
by the distributive property and linearity of expectation equation (1) can be expressed as a sum of two terms
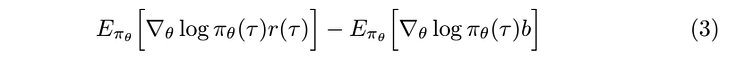
Now, we will focus on the second term in equation (3), the goal is to show that it is equal to zero, which proves that adding a baseline will not change the expected value.
But before we dig in, I will remind you of identity from calculus.
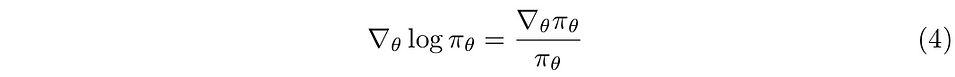
after some rearrangement
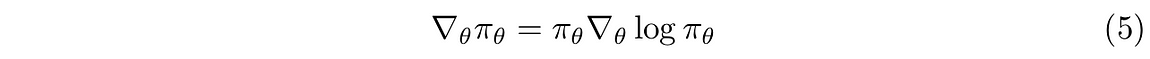
Now, apply the definition of expectation to the second term of equation(3) and substitute the underlined term with the left-hand side of equation(5).
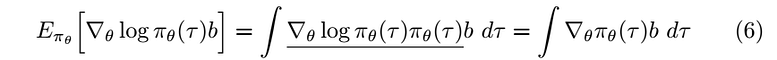
Since b is constant with respect to tau and by the linearity of the gradient operator, we can write the previous equation as
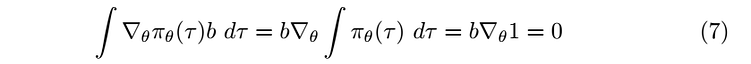
we know that π(τ ) is a probability distribution so its integral must be one, and the derivative of a constant is zero, using this result equation (1) will be
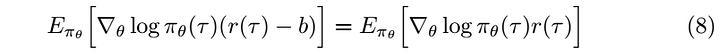
and this shows that baselines do not change the expected value and we can choose any baseline, but the question is how we choose a baseline that reduces the variance of the policy gradient effectively?
One way to answer this is to find the optimum baseline, which is the one that will minimize the variance of the policy gradient, the direct way to compute it is firstly by calculating the variance of the PG, take its derivative and set it to zero and solve the resulted equation for b, which is exactly what we will do next.
Recall that the variance of a random variable X is defined as
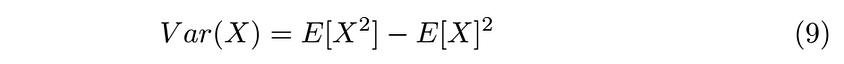
Applying this definition to the PG yields
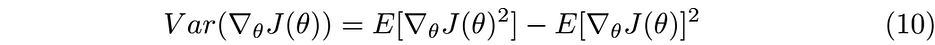
Now unpack the definition of the PG from equation 1
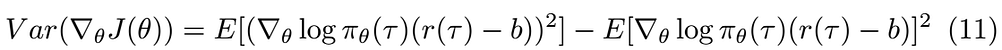
Notice that the second term in the previous equation is the baselined PG squared and we know that it is the same as the regular PG, hence we can replace the second term with the normal PG, this will make the derivative calculation easier since the second term will not depend on b which makes its derivative zero.
After replacing the second term the equation is
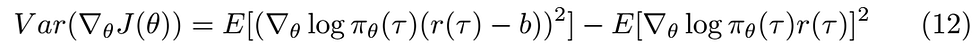
Now we are ready to take the derivative with respect to b, I will assume that you are familiar with derivative calculations and the chain rule.
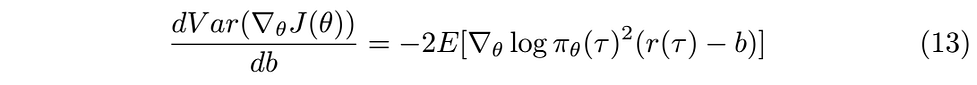
To reach to the optimum b set the derivative to zero
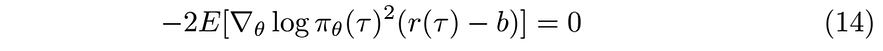
We can distribute the squared derivative and use the linearity of expectation to decompose the equation into two terms
![]()
Since b is a constant with respect to the expected value, we can pull it out of the expectation, after some the rearrangement the optimum baseline is
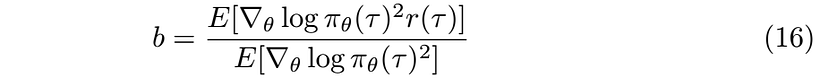
This baseline can be seen as the expected reward weighted by the PG squared, but usually, in practice, the type of baseline used is the previously mentioned average reward baseline in which we compute the average reward overall all trajectories and subtract it from the reward of the current trajectory.
In fact, there is a connection between the average reward baseline and the optimum one, you can read more details in section 3 of the paper by Lex and Nigel.
In this article we show how baselines can improve the variance of the PG without changing its expected value, we also derived the optimum baseline and introduced the average reward baseline.
References
- The Optimal Reward Baseline for Gradient·Based Reinforcement Learning by Lex and Nigel.
- Deep RL course by UC Berkely Lecture 5
- Reinforcement learning: An Introduction by Richard S. Sutton and Andrew G. Barto chapter 13.
About the Author

Faisal Ahmed
My name is Faisal Ahmed, I graduated from the University of Khartoum, Sudan, with a Mechanical Engineering Degree, I worked as a Teaching Assistant and a Research Assistant, I am a machine learning enthusiast especially about deep reinforcement learning, I write articles about various
topics in ML and mathematics.



Hi guys, just a quick unrelated question. Where can I subscribe to your awesome newsletter? I cant find the section for this on your website anymore.
Correct me if I am wrong, but you only demonstrated how a baseline doesn't impact the bias in the private case of a constant baseline that equals the average of all rewards. No? And then you talk about the advantage of baselines, all sorts of baselines. Can you prove the general case?