This article was published as a part of the Data Science Blogathon.
Introduction
Most of the machine learning and artificial intelligence models are popularly referred to as “Black Boxes”. Have you ever wondered why they are called so? Is it always good to have black box models? For the uninitiated, black-box models are those machines for which humans can only see the input and the output. We as humans are clueless about what the machine has done with the input to arrive at the said output.
In machine learning(ML) too, most of the time, we are not aware of how the machine has arrived at a particular solution but we are aware of the accuracy of the model. So, we are left with two choices: either we can just trust the machine and accept the solution or take a deep dive into figuring out why the machine is arriving at a particular solution? Let’s take the latter route and try to interpret a machine learning model.
But before we start, let’s answer a very critical question: why is it necessary to interpret a machine learning model when it already has high accuracy? Why not just trust it already?
Why is the interpretability of ML models so important?
In ML, there is always a trade-off between model interpretation and accuracy. And which one to choose always depends on: What has to be predicted? For example, we don’t care how a movie recommendation system makes recommendations given that it has good accuracy. However, things will be a bit different when a highly accurate machine learning model makes predictions on what kind of drug should be administered to a patient.
In the latter case, we have very little appetite for a wrong prediction when compared to the former. So it becomes necessary to check how the model is arriving at the solution. Model interpretation is also important for presenting our solution to business people, who don’t care about our code and the fancy loss functions that we have used. They just care about if the model solves the problem.
Having discussed why interpretability is so important, let’s go ahead and try to get some hands-on experience in a very popular model interpretation tool called ELI5.
What is ELI5?
In short, ELI5 is a python package that is used to inspect ML classifiers and explain their predictions. It is popularly used to debug algorithms such as sklearn regressors and classifiers, XGBoost, CatBoost, Keras, etc. You can read more about the package here.
ELI5 Model Interpretation
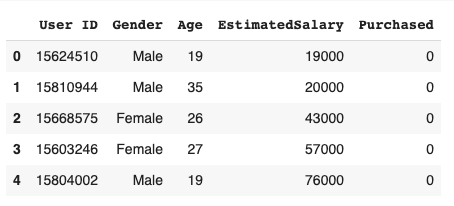
To begin with, we need a dataset and a problem. For the purpose of this article, we will be using the social_network_ads dataset. Here, we will try to predict whether a user has purchased a product by clicking on the advertisements shown to it on social networks, based on its gender, age, and estimated salary. So without further ado, let’s get started.
Step 1: Install ELI5
Once you have installed the package, we are all set to work with it.
Step 2: Import the important libraries
Step 3: Import the dataset
Python Code:
import pandas as pd
import numpy as np
import seaborn as sns
import eli5 as eli
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
data = pd.read_csv(r'Social_Network_Ads.csv')
print(data.head())
Step 4: Data preparation and preprocessing
In this step, we have performed some basic preprocessing steps such as checking for NAs, splitting the dataset into inputs and outcome, training and testing sets, and label encoding categorical variables.
data.isna().sum()

#split the dataset into independent and dependent variables
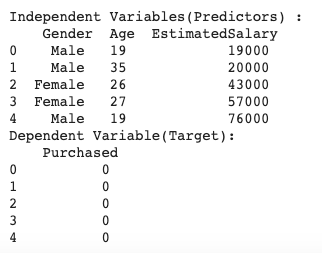
X = data.iloc[:, [1, 2, 3]]
y = data.iloc[:,[4]]
print("Independent Variables(Predictors) :n", X.head(), "nDependent Variable(Target):n", y.head())
encoder = LabelEncoder() X.Gender = encoder.fit_transform(X.Gender) # Splitting the dataset into the Training set and Test set (75:25) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25)
Once we have prepared the data, we are all set to train an ML model to make predictions. In this case, we are using a decision tree classifier.
Step 5: Model Training
# Decision Tree Classifier classifier_dtc = DecisionTreeClassifier() classifier_dtc.fit(X_train, y_train)

Step 6: Model Testing
After training the model, test it on the 25% of the dataset that we kept aside for testing.
# Predicting the Test set results y_pred = classifier_dtc.predict(X_test)
Step 7: Model Evaluation
Predictions have been made, now it’s time for model evaluation. We are using a confusion matrix here. Each row in a confusion matrix corresponds to the actual class while each column corresponds to a predicted class.
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
clf_rpt = classification_report(y_test,y_pred)
print("classification report :", clf_rpt)
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm,annot=True)

As can be seen from the classification report, the model is 84% accurate. But we want to know how the model is coming to this conclusion. Hence, let’s go ahead and try to use ELI5 to get some answers.
Step 8: Model Interpretation
To start with, we can use explain_weights() to find the weight given to each feature in prediction. For tree-based models, ELI5 does nothing new for calculating feature weights. It simply uses the GINI index used for preparing decision trees as weights.
eli.explain_weights(classifier_dtc)

Here is a portion of the decision tree with feature weights.
Suppose if we wish to debug and check how the outcome has been predicted for a particular row. We can use explain_prediction().
eli.explain_prediction(classifier_dtc , np.array(X_test)[1])

As can be observed from the above output, eli5 shows us the contribution of each feature in predicting the output. If you further wish to see and compare what combination of features and values lead to a particular prediction, we can use show_prediction().
eli.show_prediction(classifier_dtc, X_test.iloc[1],
feature_names=list(X.columns),
show_feature_values=True)

eli.show_prediction(classifier_dtc, X_test.iloc[20],
feature_names=list(X.columns),
show_feature_values=True)

Yeah! you guess it right. In ELI5, a prediction is basically the sum of positive features inclusive of bias.
WRAP UP
These were just a few examples of debugging using ELI5. There are many other model interpretation frameworks such as Skater and SHAP. Be Sherlock !! go ahead and try to inspect and debug the machine learning models that make you ponder over the outcomes.





