This article is the third in a series of four, where we mention some of the most discussed points to keep in mind before taking the big leap towards analytics. You can read the first 2 articles using the following links-
-
Everything you need to know before setting up Business Analytics!
-
Getting Started with Analytics in your Organization: Think Big, Start Small
Introduction
Organizations – be it a Fortune 500 company or a nascent-stage start-up, are busy amassing petabytes of data. This data ranges from customer-facing data (such as the click of a mouse, a walk into a store, product visibility on a shelf) to operational data (such as R&D findings, sales interactions, machinery breakdown, and product stock-outs).
While everyone agrees with the importance of data as a key differentiator and enabler in business strategy, very few have realigned their data practices to reflect this intent. Something is clearly wrong here: while data collection is moving at the speed of light, data management needs to catch up.
The USD 2 trillion behemoth Amazon owes its success to date. While its e-commerce division obviously uses data to predict customer behavior in addition to showing relevant ads and products, data is the very foundation of its most profitable business division – Amazon Web Services (AWS). AWS offers cloud computing, storage, and analytics services to businesses of all sizes and is responsible for approximately 70% of Amazon.com Inc’s operating profits.
In fact, all the other big tech companies – Microsoft, Alphabet, and IBM – are also betting big on cloud computing services. All these giants have huge investments being poured into big data management by organizations across sectors. Have these investments in data started to pay off? An increasing number of executives admit to being let down by the Return on Investment (RoI) realized from investments in data. Is there some way to rethink or optimize these investments? Here are some data challenges that business leaders need to overcome to tap into the much-hyped “big data potential”.
Data Collection
Shining Light on Dark Data
The ability to collect data far exceeds the throughput at which organizations can analyze this data. This trend has been fuelled by the cheap data storage and pay-as-you-go cloud models, which are hosted and managed by third-party service providers. This leads to hordes of “Dark Data” lying within organizations.
To quote Wikipedia-
“Dark data is data which is acquired through various computer network operations but not used in any manner to derive insights or for decision-making.”
At times, organizations are not even aware that such data is being collected. According to a study by IBM, roughly 90% of data generated by sophisticated IT systems (sensors and telemeters) is never utilized. For a brighter future of data analytics, dark data needs to go, paving the way for cost rationalization and ease of operations.
An even Darker Side
While there is an overwhelming amount of data for coming-of-the-age businesses, most conventional businesses are still struggling to collect valuable data about customers. Often, there are no data collection practices in place, and legacy IT systems are not keeping up with increasing data volumes and complexity. Operational data (sales ledger, order book, logistics, etc.) is the only priority, and other data is often missing or outdated.
The root cause is a lack of awareness about value-based data collection – understanding what problem needs to be solved and what data can/should be collected to analyze it. To tackle this, a shift in mindset is required where data is treated as a strategic asset rather than an IT liability.
Data Storage & Processing
IT Infrastructure – IT is what it is
Despite the pace of advancement in big data & cloud technologies, IT systems need to keep up with expanding volume, velocity, and variety of data. Often, a number of different technologies and tools like NoSQL databases, Hadoop, Spark, etc. are needed to manage expectations of different stakeholders – e.g. streaming data, graph data, or unstructured data. Data integration and migration from disparate IT systems is another challenge. Few IT platforms have no or limited inbuilt support for data migration or data from these systems may not be in sync with each other.
To tackle these issues, more investments are required in the form of acquisition and up-gradation of data infrastructure, staff training, and onboarding. Technologies like de-duplication, compression, and indexing can lead to significant improvements in database costs and performance. While data architecture should be sophisticated enough to fulfill future needs in terms of both scale and agility, it should also function seamlessly with other IT systems – especially ETL and analytics platforms.
Rather than developing capabilities in-house, companies can make use of existing cloud services like AWS, Microsoft Azure, etc. The following figure shows the 7 V’s framework, which is often referred to when deciding data infrastructure requirements.

Data Digitization – Cloud Nine
While a 100% shift to digital might not be possible for every business, a lot of data collected through physical forms, invoices, receipts, and standalone excel sheets can be converted to usable forms by employing automation and Optical Character Recognition (OCR) devices. Unstructured data constitutes 80% of overall data generated, and it has been the focus of recent advancements in deep learning.
This information, in the form of text, images, geospatial data, blockchain, etc., is often overlooked due to operational challenges to capture and analyze this data as well as the lack of appropriate use-cases.
Data Quality – Garbage In, Garbage Out
It is highly likely that poor data quality is the key cause of the under-utilization of data. Findings based on incomplete, biased, and incorrect data can often be flawed, and business managers often find it tough to trust decisions backed by such data. Non-standard and manual processes for data logging, maintenance, and updating add up to data errors and duplication.
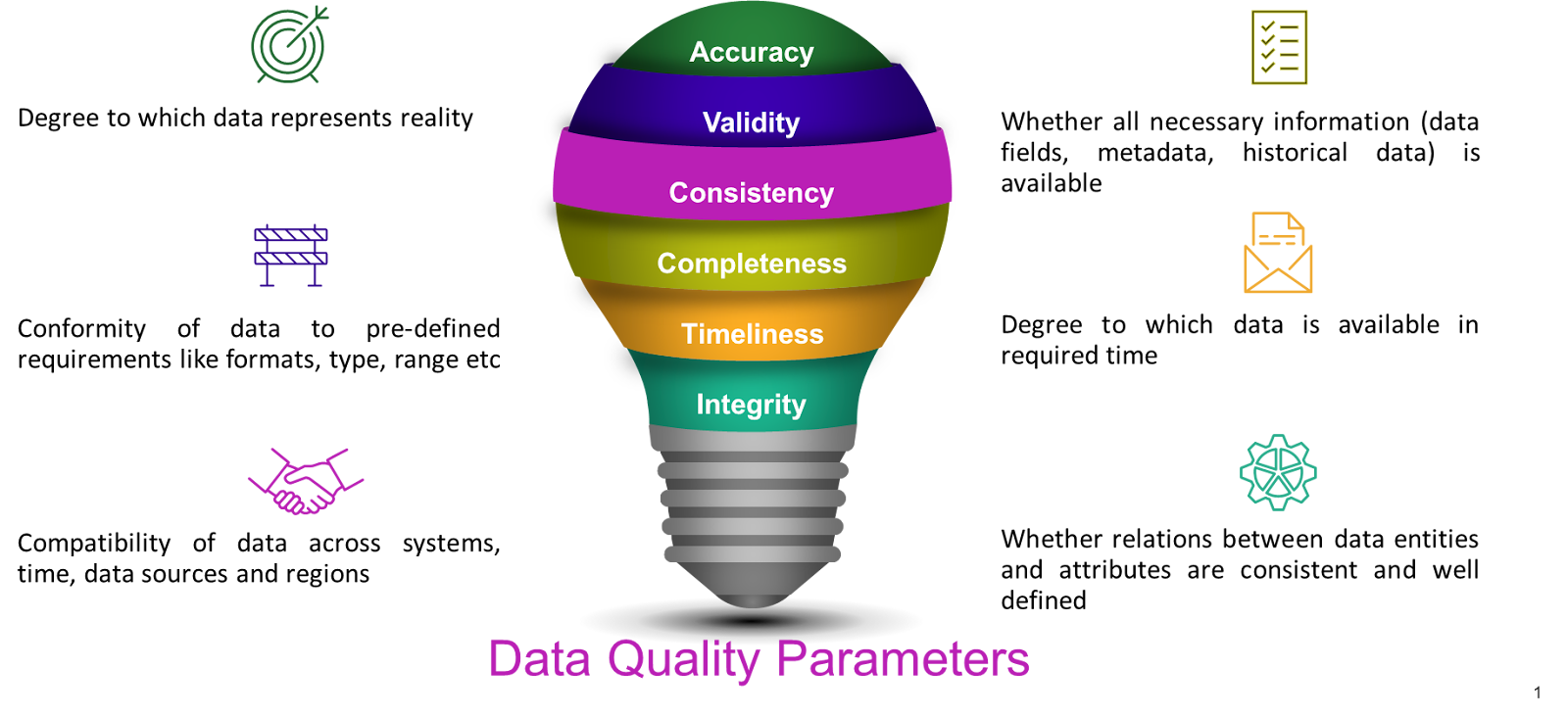
What makes this more problematic is the fact that such errors often go unnoticed, making data insights dicey. Hence, it is imperative to focus on continually improving the quality of data through a mechanism of data validation, data hygiene checks, quality control, and data cleansing practices. An external service provider or commercial software can also help in mitigating these issues. The following infographic sums up the key data quality parameters that one needs to focus on to better leverage the power of data.
Data Governance
Privacy and Integrity Concerns – Give that man a cookie!
With big data, powers come bigger scrutiny. As new and extensive data privacy laws (e.g. GDPR) come into the picture, organizations are plagued with legal and compliance concerns. While it is a good start, there is still a very significant grey area. GDPR has no clear indication of what includes “personal data” and what is meant by a “reasonable” level of protection for such data.
The underlying assumption of data should be to serve consumers better and hence, consumer-facing businesses having sensitive user data, such as personal and financial details, need to rethink how and when this data will help, who is the owner, and who is the end-user of this data.
To tackle concerns on data ethics, users need to be informed beforehand about what data is being stored and how it might be shared and used in the future within or outside of the organization. Furthermore, technologies like data masking and encryption can be used to help in assuaging the data privacy fears of customers and top management.
Security and Governance Risks – Store but secure
Data stored in servers often outlives its usage, leading to unnecessary regulatory and maintenance burden. Data lifecycle management could be the right step in this direction. Data sharing practices are also not updated frequently, which means the relevant people (developers or decision-makers) in an organization do not have the required knowledge, permission, or tools to access data. Internal data audits highlighting data storage, and sharing practices should be held on a timely basis.
This will ensure flushing out of junk data, setting clear definitions and expectations from data stakeholders, and minimizing the risk of data loss or data leaks. A data breach or a hacking attempt can be catastrophic in terms of business and reputation loss arising from such events. To mitigate such risks, organizations need to step-up data security by formulating internal policies and controls for data ownership, restricting unauthorized access to data, and tightening cybersecurity measures.
Closing Comments
To make sure that the enterprise analytics engine is running smoothly, there is a need to channelize the appropriate data at a desired pace and quality. Requiring more than merely hardware, applications, and skills, data transformation relies on people and the governance structure around it. In order to separate insights from data points and understand data possibilities, organizations should evaluate their existing data framework and collection practices, remove and rationalize unnecessary overheads, while simultaneously sharpening their focus on a secure and centralized data environment.
There is also a need to distinguish data for operations (for purposes of regulatory, record-keeping, and quality management) from data for insights. A business case for data is most important to ensure momentum and longevity. Hence, any changes in data strategy should be incorporated after taking inputs from business managers.
About the Author

Amit Kumar
Amit, a Data Science and Artificial Intelligence professional is currently working as a Director at Nexdigm (SKP), a global business advisory organization serving clients from 50+ countries. He holds over 15 years of experience across industries and has worked from both perspectives, as an internal functional expert (in Vodafone, Aviva Insurance, GE) and as a consultant. A passionate advocate of data science, Amit constantly endeavors to create optimal, actionable solutions, that help derive measurable business value from data.
Connect with Amit – LinkedIn.



