This article was published as a part of the Data Science Blogathon.
Introduction
Scala is difficult to learn, true, but it’s worth the hard work. Scala has much easier syntax and is also more expressive. Scala codes are much concise than Java’s and an engineer who can write short and expressive code while also making it a type-safe and high-performance application are be considered valuable.
In this project, that I made as a college project, we’ll see how to write in a .csv file using Scala, which we will then use to create a basic fruit detection Machine Learning model.
Data Set
The data set that we will use can be found here.
The data set contains 4 fruits – Apple, Mandarin, Orange, and Lemons. And we will classify them,
solely on the basis of the given height, width, mass, and color score.
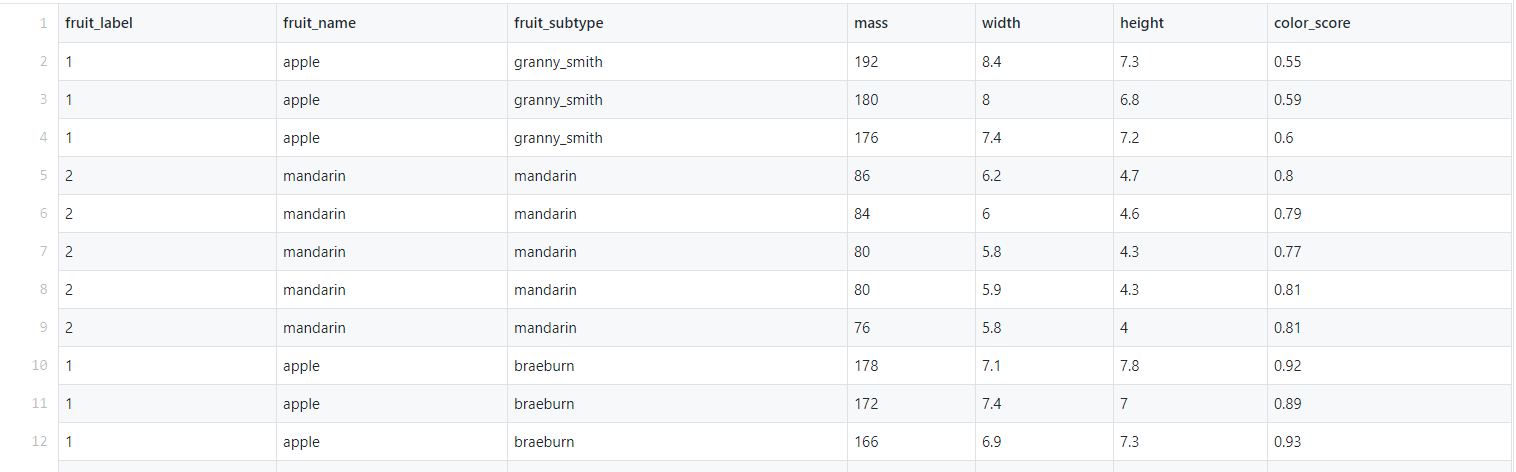
Although our dataset is already cleaned, if you wish to use a different dataset, make sure to clean and preprocess the data using python or any other way you want, to get the maximum out of your data, while training the model.
Writing in the CSV file
For writing the CSV file, we’ll use Scala’s BufferedWriter,
FileWriter and csvWriter.
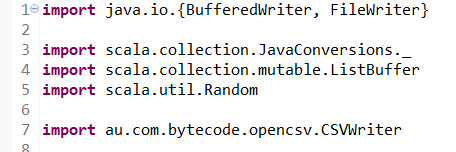
We need to import all the above files before moving forward to deciding a path and giving column headings to our file.

We take a few rows of our data to take as input for the training dataset and to use it in writing our CSV file.
1. val out = new BufferedWriter(new FileWriter("D:/Academic/Assignments/Scala/Fruits.csv")) //this line will locate the file in the said directory
2. val writer = new CSVWriter(out) //this creates a csvWriter object for our file
3. val FruitSchema=Array("fruit_label","fruit_name","fruit_subtype","mass","width","height","color_score") // these are the schemas/headings of our csv file
Then we create arrays of our dataset, according to our schema plan.

To write this data into our csv file, we need to add this code snippet,

1. var listOfRecords=List() // this creates a list which holds our data 2. writer.writeAll(listOfRecords) // this adds our data into csv file 3. out.close() //closing the file
Whew, we got that right,
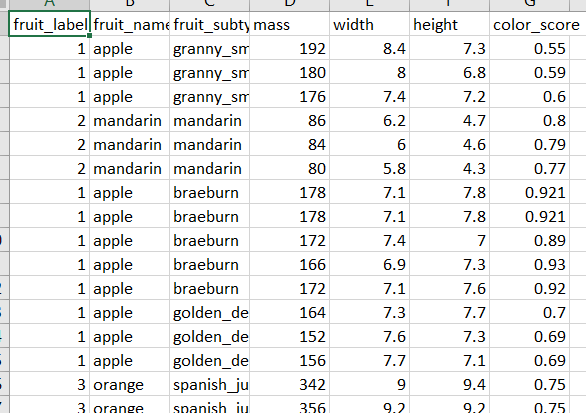
Creating a file using random data
We’ve created our CSV file using Scala. Although, there is one more way to do this, where we generate our data randomly, using ranges which we can then convert to lists.
Firstly, we import all the required libraries.

Then, we’ll now create our lists and ranges, which will contain the data we need in our CSV file.
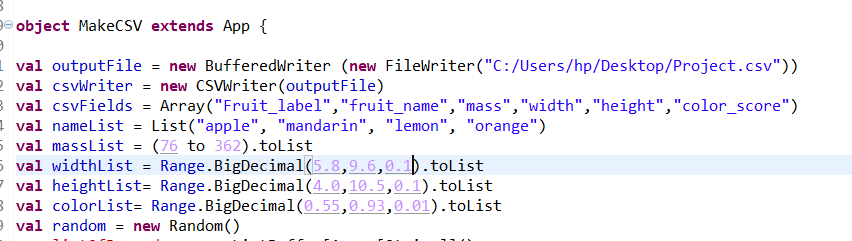
1. val widthList = Range.BigDecimal(5.8,9.6,0.1).toList // BigDecimal(starting number, ending number, step count) is used to accept float in range and the toList function converts this range to a list 2. val random = new Random() // this function is used to generate the data randomly
Now we will put all this data in our CSV

1. var listOfRecords = new ListBuffer[Array[String]]() // this buffer holds all our data
2. listOfRecords += csvFields // this adds our schemas/headings
3. for(i<- 1 until 50){ listOfRecords+=Array(i.toString,nameList(random.nextInt(nameList.length)),massList(random.nextInt(massList.length)).toString(), widthList(random.nextInt(widthList.length)).toString(),heightList(random.nextInt(heightList.length)).toString(),colorList(random.nextInt(colorList.length)).toString())} //the loop that which adds data to buffer
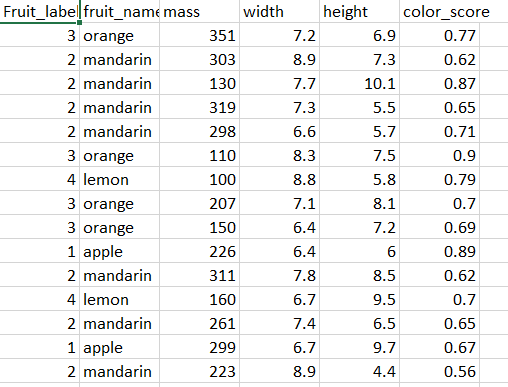
I used the Vlookup function in excel to add the fruit label.
This code generates the data purely randomly, so we need to be very careful before using it.
Creating Machine Learning model
To build our model, we’ll use Jupyter IDE of python.
I added a few more rows of data in my first CSV file, to get more accurate results.
Let’s get started, by importing the required libraries.
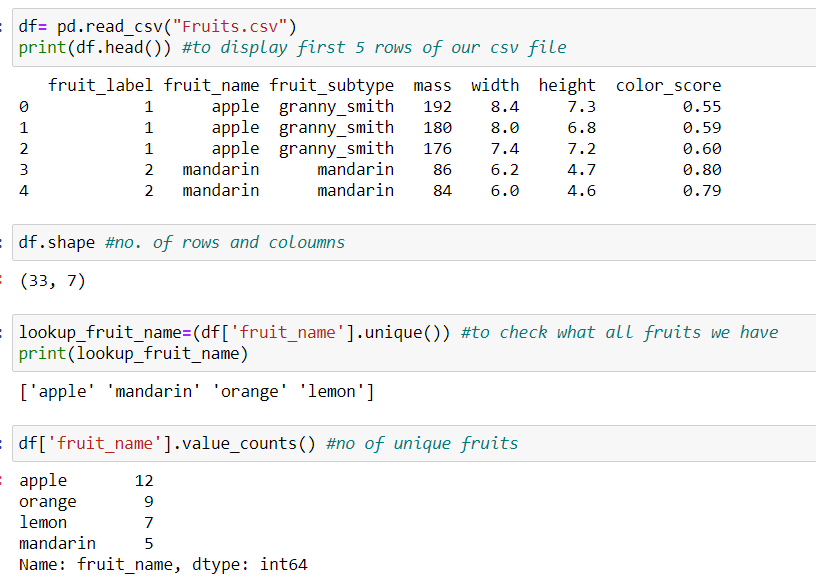
Now, it’s always better to have all the CSV files and python files in the same folder, so that it’s easy for us to code and organize and for python to find the file. Now, we will read in our CSV file.
We can also visualize the data using the seaborn library of python, to understand the data better. I, for one, have skipped it for now.
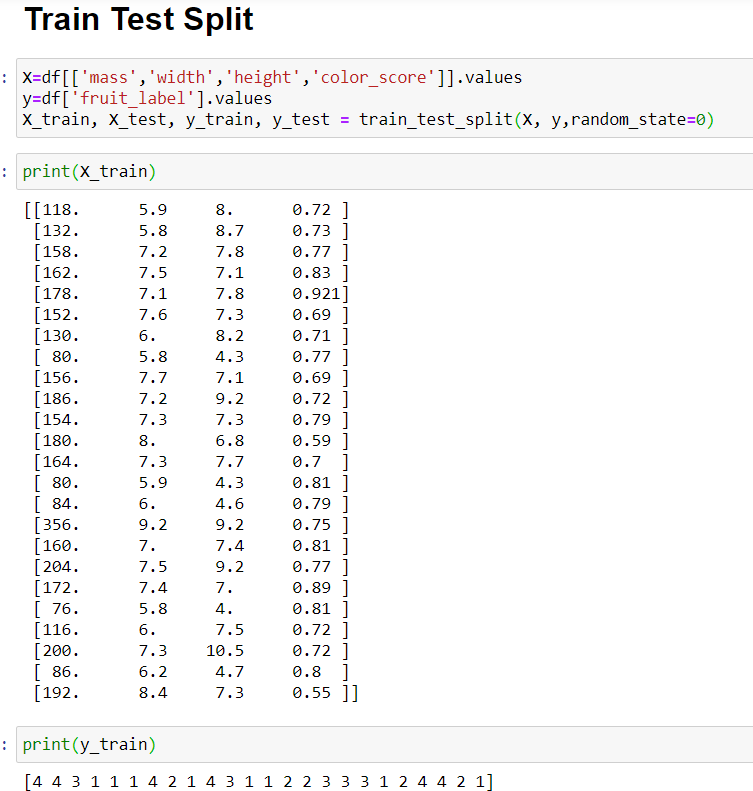
Lets split our data into training and test data,
After splitting the data, let’s check what model we can use, I first tried using Decision Tree, as we have a comparatively lesser data
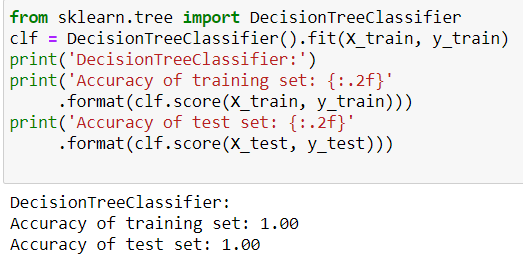
But, we can clearly see that this model is overfitting, so we reject this. Now, let’s check for K Nearest Neighbor,

We can see that accuracy for both, training and test set is pretty good, so we can use this model, as it is neither overfitting nor underfitting.
Let’s fit our data in the KNN model and check for the best neighbor value.
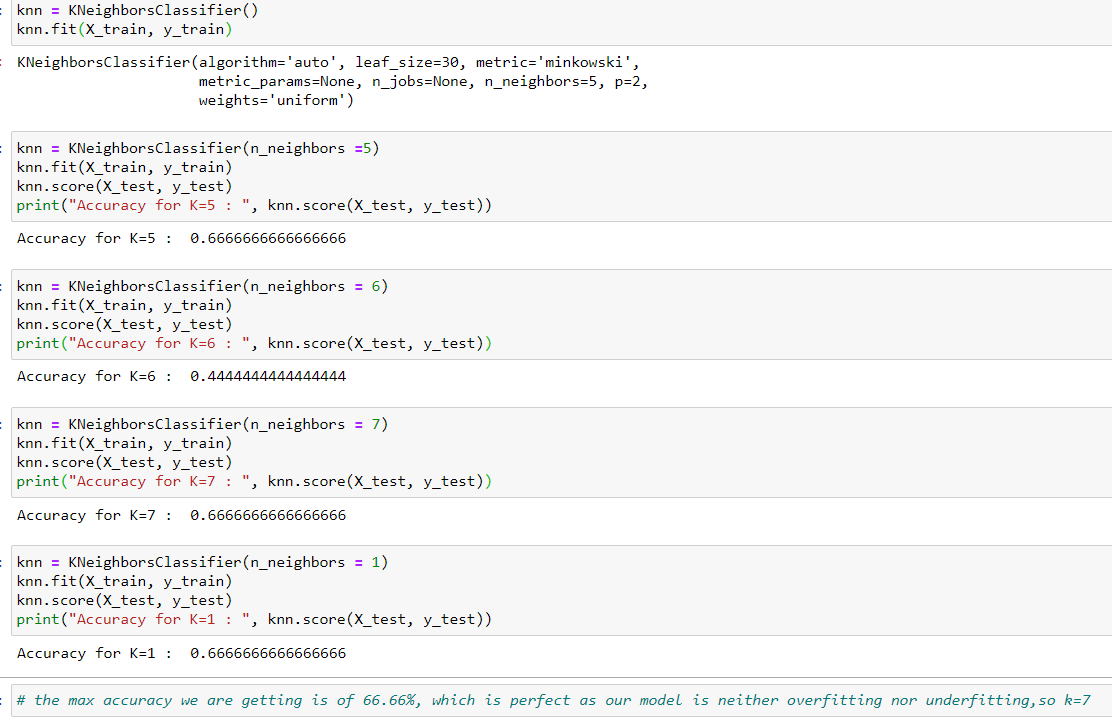
After finding the perfect value, let’s see the prediction score of our model,
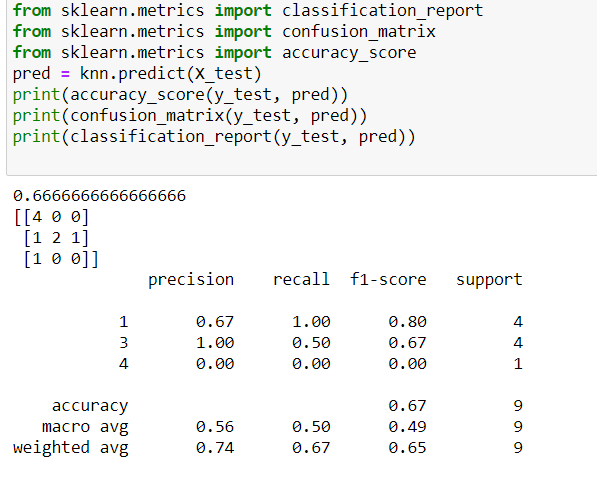
It’s not the best, but because we took a small dataset for this project, this is quite nice, now, we’ll finally plot the decision boundaries of our project.
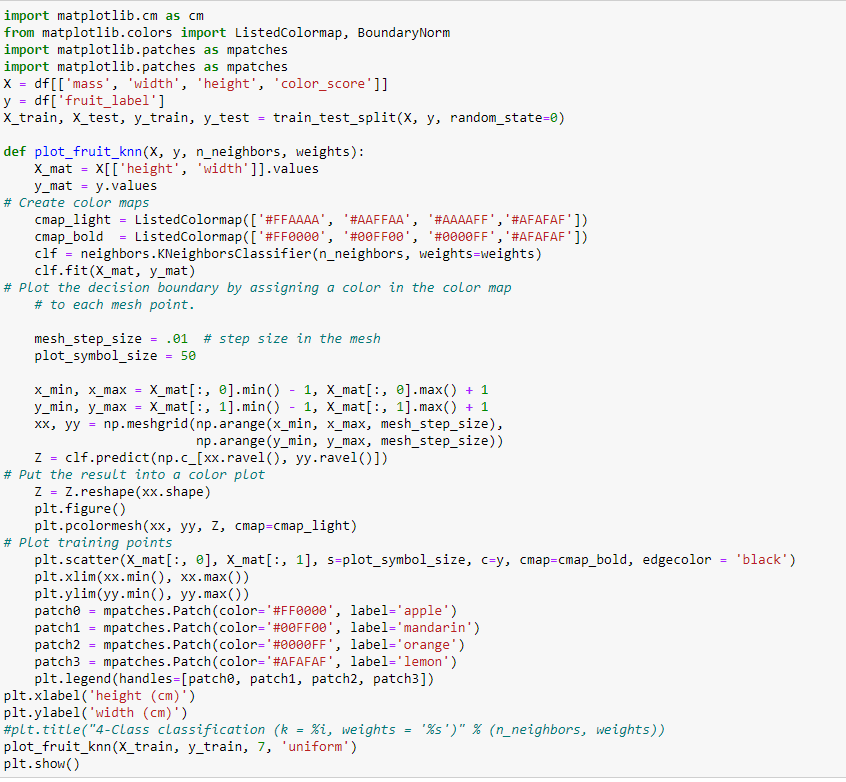
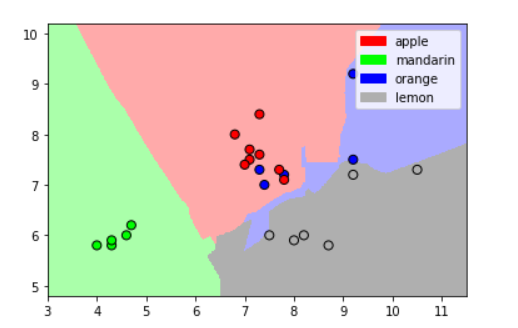
And, we’re done!
Conclusion
We have now learned, how to create CSV files using Scala and the basics of Machine Learning!






Good work.