This article was published as a part of the Data Science Blogathon.
Introduction
Comprehending the reviews of customers is very crucial for a business to be successful. Analyzing the reviews helps to properly discern the customer different preferences, likes, dislikes, etc. These extracted insights can then be used to improve customer service and experience.
In this article, we would be working on a Brazilian E-commerce reviews dataset where we would perform some exploratory data analysis (EDA) on reviews text, derive meaningful insights from our analysis, and then translate our outputs from Portuguese to the English language for better and easier understanding.
Dataset Description
This dataset was taken from Kaggle and was generously provided by Olist online stores in Brazil. Here’s the link to the dataset.
This Kaggle project has multiple datasets containing different fields such as orders, payments, geolocation, products, products_category, etc. but we would be solely focusing on the text reviews dataset for our analysis. The reviews dataset has 100,000 datapoints and after getting rid of NaN values, 40,000 reviews were left which is sufficient for analysis. Some of the reviews had titles and all had to review scores so we also have to take these into consideration.
Methodology
Installing and Importing libraries
We have to, first of all, import important libraries (such as pandas, numpy, and matplotlib) and NLTK tools for our natural language processing.
For our language translation, we need to install Google Translate API. I initially encountered some error in making use of the original API but I was able to find a working version a few days ago named ‘Google_trans_new’ that effectively solved the problem. You can visit here to know more-
If you have not yet installed it, go ahead and do so because this would be used for our translation later. From the image above, we can see the list of languages that are supported by this translate API. For now, we are only interested in the Portuguese and English languages. Let’s run a quick example;
.png)
We can see how our Portuguese text got translated and we can decide to translate to any other language supported by this API.
Data Preprocessing
Next, we would read in our data and carry out some initial EDA and dataset modification.
.png)
The review dataset has a significant amount of NaN values in the reviews text and reviews title so we would make sure to drop those missing values and reset the index.
.png)
Just like the normal Day-to-day NLP tasks carried out, we need to implement some necessary preprocessing steps which involve; transforming the reviews data by removing stop words, using the regular expression module to accept only letters, tokenizing the text, and making all the words lower case for consistency. In this case, we would have to remove Portuguese stop words.
Data Visualization
After our data preprocessing, it is time to visualize our review text using Wordclouds. A Wordcloud is a visual representation of the involved text data and it displays the importance of the words by the font size.

The Wordcloud above shows the most frequent words in Portuguese and this would not mean much if you don’t understand Portuguese so we need to translate these words to English. At this point, Countvectorizer was used to get the most important Unigrams(one word), Bigrams(two words), and Trigrams(three words). Below are the codes and images showing the trigrams and the respective English translations. To get the unigrams and bigrams, replace ngram_range =(1,1) and (2,2) respectively.
.png)
From the unigrams, bigrams, and trigrams that were gotten, we can safely deduce that most customers were satisfied with the delivery service and some others were satisfied with the product quality.
Similar preprocessing steps were also applied to the reviews titles column and Wordcloud was used to visualize these titles.

.png)
Carrying out similar operations on the reviews title column, we were able to better understand the unhappy comments of displeased customers. These comments include: Getting incomplete delivery, Not receiving ordered goods, Delay in delivery, Low quality of delivered goods, Receiving wrong/defective products. So far, these have been the major complaints of unhappy customers but we have also seen a high degree of satisfaction among other customers.
To further understand the relationship between customers who gave low/high review score and those who gave reviews, we need to do a count plot showing these figures;
.png)
We can notice that about 36% of 5-star reviewers gave reviews while 79% of 1-star reviewers gave reviews so a customer was more likely to give reviews when he/she is displeased.
Let’s also have a look at the average number of words per review;
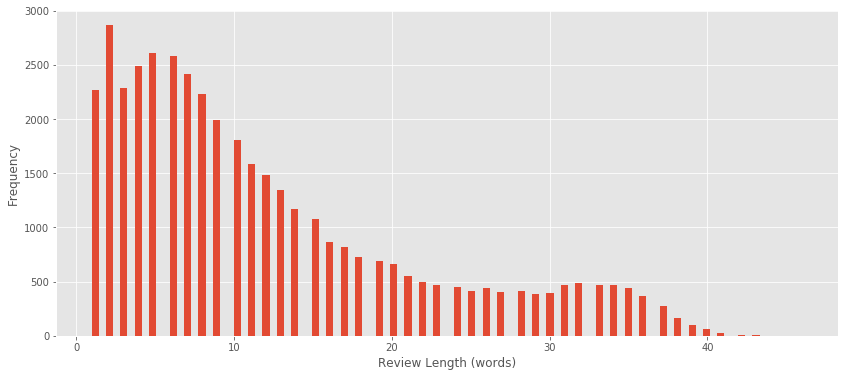
Conclusion
So far, we have been able to the analysis of the text reviews of customers and we have seen the unhappy comments made by some of them. It’s now up to the data scientist/analyst to figure out the best ways in making sure these problems are solved.
At the end of this article, I am sure that you know how to be able to carry out basic text visualization and also be able to convert text languages to your preferred choice using Google Translate API. There are other numerous ideas that can be implemented on this dataset such as sentiment analysis and topic modeling, these were also covered in my notebook. The complete Github Notebook can be found here.
Happy Learning!




