This article was published as a part of the Data Science Blogathon.

Introduction
Similar to rule-based mathematical models, AI/ML models are also validated for inherent risks and the business problem they are intended to solve.
Typically, the model is checked on the following grounds:
* Expected performance
* Is it in alignment with the objective it is meant for?
* Assumptions – are they valid and sound?
* What is the limitation of the serving model?
* The potential impact on the KPI
* Does it adhere to regulatory and ethical mandates? (wherever needed)
AI/ML evaluation and validation pointers:
1) Data Integrity:
* Data documentation is critical given that we are dealing with humongous data on daily basis throughout the data pipeline. Data lineage ensures traceability i.e. to maintain data integrity.
* Data pipeline during model training should be synchronous to what is used for production, as multiple model retraining might make it challenging to maintain such dynamic changes.
* Data integrity involves checking the appropriate missing values imputation, data standardization techniques, identifying anomalous patterns, legit labeled data (mislabelled data makes model development a difficult learning process)
2) Feature Engineering:
* Feature Engineering is the heart of the AI/ML model pipeline and makes a significant impact on pattern learning. Having said that, bad feature engineering does equal damage, e.g. data leakage
3) Sampling bias:
* Model should be robust to sampling bias i.e. it should be built on the sample which is an appropriate representation of the population. Imbalanced i.e. under and overrepresentation of any particular class introduces systematic bias to the model
4) Hyper parametrization:
* Change in parameter settings has a direct impact on the model output and needs to be addressed for computational feasibility as well.
5) Explainability:
* AI/ML model ingests a set of input features and outputs the predictions, but how to understand those output predictions is of key interest to gain user’s confidence.
* For simpler models like Linear Regression, we can easily identify the contribution or impact of features on the output variable. But for complex models, such as ensemble models or neural networks, there is no clear path or trajectory which can explain how a certain input vector got transformed into a certain output.
* When model explainability is not transparent, it can entail a lot of other issues which might go unidentified, to the likes of sampling bias, fairness, an appropriate representation of each group, etc.
* Sensitivity and stress testing are necessary to answer the following questions, which embodies the model explainability framework: Key features for each prediction, drivers of actual projections, the difference between ML model and a linear model, working of an ML model, model performance under new states of the world
Feature Importance is at two levels – global (training/historical data) and local (each prediction)
Multiple frameworks for model explainability:
* Global: Tree-based, Partial Dependence Plots, Permutation test-based, Global Sensitivity Analysis
* Local: Shapley values, LIME, LRP i.e. layer-wise relevant propagation
Global Explainability using Partial Dependence Plots:
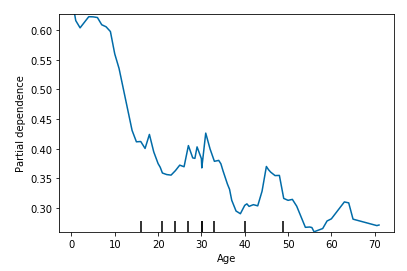
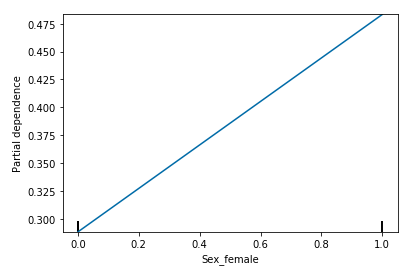
Below is an implementation of PDP using the sklearn library on the Titanic dataset.
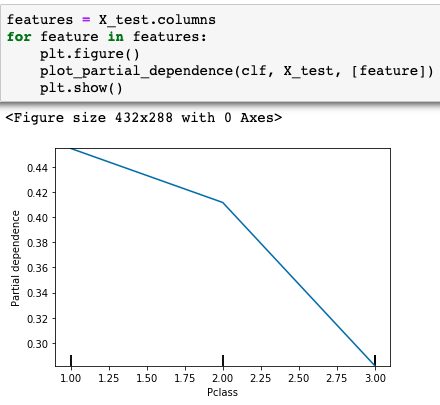
The figure shows that Class-1 Passengers had a better chance of survival as compared to Class-3 Passengers
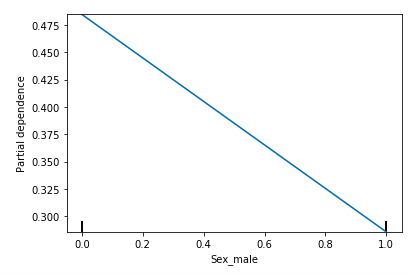
The figure depicts that being male lessens the chance of survival
Local Explainability using Shap values and Lime
Below is the implementation of Shap and lime on the titanic dataset.


I have picked 4 examples from the test set to showcase the sample explainability
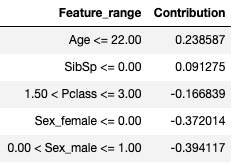
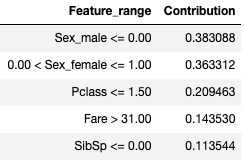
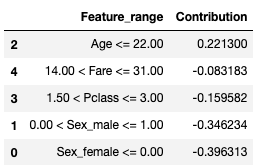
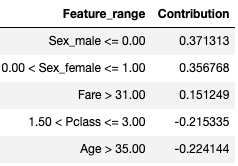
Example 1:
Outcome: Not survived


Feature value contributions(LIME):






In this article, we learned the importance of Model Risk Management, an in-depth understanding of AI/ML specific risk areas, and a deeper understanding of the importance of explainability. We also implemented Global and Local explainability using PDP, SHAP, and LIME frameworks on the Titanic dataset and were able to visualize/compare feature contributions.
Thank you! Keep reading, keep learning!






Good and orderly presentation full of so many useful and eye-opening ideas imbedded in it